 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Entropy: Learning from Token-Level Distributional Deviations for LLM Reasoning
Jun 18, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has significantly advanced Large Language Model (LLM) reasoning; however, it faces a fundamental optimization instability: uniform token updates precipitate entropy collapse, leading to premature convergence to suboptimal strategies, whereas excessive Shannon Entropy maximization can cause entropy explosion, driving blind exploration toward incoherent reasoning chains. To resolve this dichotomy, we introduce the Independent Combinatorial Tokens (ICT) framework, which shifts the optimization focus from scalar uncertainty to the distributional properties of token logits. By leveraging the Jensen-Shannon (JS) divergence between token logits distributions, ICT identifies tokens with distinctive distributional patterns as critical branching points for guiding effective exploration in LLM reasoning. Our theoretical analysis, grounded in both Shannon and second-order Rényi entropy, proves that selectively updating on these tokens regulates policy concentration: it reduces the overall distribution uncertainty measured by Shannon entropy, while controlling probability concentration captured by second-order Rényi entropy. This dual effect prevents over-concentrated token generation from weakening exploration and effectively stabilizes the training landscape. Empirical results demonstrate that updating only the top 10% of unique tokens on Qwen2.5 (0.5B/1.5B/7B) models yields an average pass@4 improvement of 4.58%, with a maximum gain of 14.9%, over GRPO, 20-Entropy, and STAPO baselines across seven benchmarks spanning math, commonsense, and Olympiad-level problems.
Harnessing Reasoning Trajectories for Hallucination Detection via Answer-agreement Representation Shaping
Jan 24, 2026Large reasoning models (LRMs) often generate long, seemingly coherent reasoning traces yet still produce incorrect answers, making hallucination detection challenging. Although trajectories contain useful signals, directly using trace text or vanilla hidden states for detection is brittle: traces vary in form and detectors can overfit to superficial patterns rather than answer validity. We introduce Answer-agreement Representation Shaping (ARS), which learns detection-friendly trace-conditioned representations by explicitly encoding answer stability. ARS generates counterfactual answers through small latent interventions, specifically, perturbing the trace-boundary embedding, and labels each perturbation by whether the resulting answer agrees with the original. It then learns representations that bring answer-agreeing states together and separate answer-disagreeing ones, exposing latent instability indicative of hallucination risk. The shaped embeddings are plug-and-play with existing embedding-based detectors and require no human annotations during training. Experiments demonstrate that ARS consistently improves detection and achieves substantial gains over strong baselines.
DLMMPR:Deep Learning-based Measurement Matrix for Phase Retrieval
Nov 16, 2025


This paper pioneers the integration of learning optimization into measurement matrix design for phase retrieval. We introduce the Deep Learning-based Measurement Matrix for Phase Retrieval (DLMMPR) algorithm, which parameterizes the measurement matrix within an end-to-end deep learning architecture. Synergistically augmented with subgradient descent and proximal mapping modules for robust recovery, DLMMPR's efficacy is decisively confirmed through comprehensive empirical validation across diverse noise regimes. Benchmarked against DeepMMSE and PrComplex, our method yields substantial gains in PSNR and SSIM, underscoring its superiority.
NVR: Vector Runahead on NPUs for Sparse Memory Access
Feb 19, 2025Deep Neural Networks are increasingly leveraging sparsity to reduce the scaling up of model parameter size. However, reducing wall-clock time through sparsity and pruning remains challenging due to irregular memory access patterns, leading to frequent cache misses. In this paper, we present NPU Vector Runahead (NVR), a prefetching mechanism tailored for NPUs to address cache miss problems in sparse DNN workloads. Rather than optimising memory patterns with high overhead and poor portability, NVR adapts runahead execution to the unique architecture of NPUs. NVR provides a general micro-architectural solution for sparse DNN workloads without requiring compiler or algorithmic support, operating as a decoupled, speculative, lightweight hardware sub-thread alongside the NPU, with minimal hardware overhead (under 5%). NVR achieves an average 90% reduction in cache misses compared to SOTA prefetching in general-purpose processors, delivering 4x average speedup on sparse workloads versus NPUs without prefetching. Moreover, we investigate the advantages of incorporating a small cache (16KB) into the NPU combined with NVR. Our evaluation shows that expanding this modest cache delivers 5x higher performance benefits than increasing the L2 cache size by the same amount.
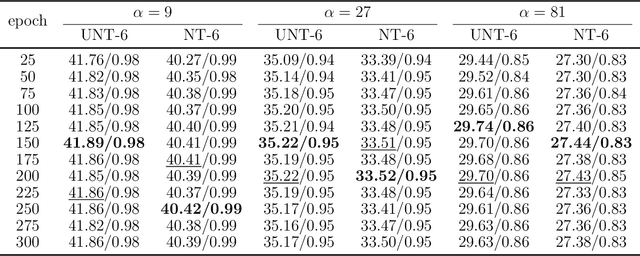
Break The Spell Of Total Correlation In betaTCVAE
Oct 17, 2022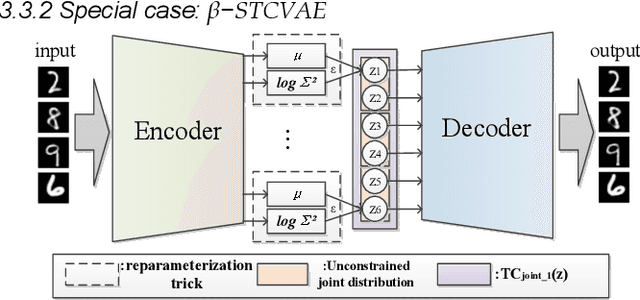
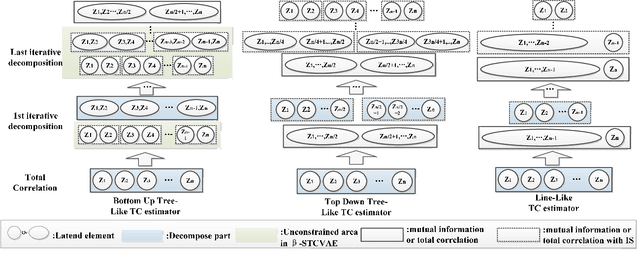

This paper proposes a way to break the spell of total correlation in betaTCVAE based on the motivation of the total correlation decomposition. An iterative decomposition path of total correlation is proposed, and an explanation for representation learning ability of VAE from the perspective of model capacity allocation. Newly developed objective function combines latent variable dimensions into joint distribution while relieving independent distribution constraint of the marginal distribution in combination, leading to latent variables with a more manipulable prior distribution. The novel model enables VAE to adjust the parameter capacity to divide dependent and independent data features flexibly. Experimental results on various datasets show an interesting relevance between model capacity and the latent variable grouping size, called the "V"-shaped best ELBO trajectory. Additional experiments demonstrate that the proposed method obtains better disentanglement performance with reasonable parameter capacity allocation. Finally, we design experiments to show the limitations of estimating total correlation with mutual information, identifying its source of estimation deviation.