 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised 360 Layout Estimation with Panoramic Collaborative Perturbations
Mar 03, 2025The performance of existing supervised layout estimation methods heavily relies on the quality of data annotations. However, obtaining large-scale and high-quality datasets remains a laborious and time-consuming challenge. To solve this problem, semi-supervised approaches are introduced to relieve the demand for expensive data annotations by encouraging the consistent results of unlabeled data with different perturbations. However, existing solutions merely employ vanilla perturbations, ignoring the characteristics of panoramic layout estimation. In contrast, we propose a novel semi-supervised method named SemiLayout360, which incorporates the priors of the panoramic layout and distortion through collaborative perturbations. Specifically, we leverage the panoramic layout prior to enhance the model's focus on potential layout boundaries. Meanwhile, we introduce the panoramic distortion prior to strengthen distortion awareness. Furthermore, to prevent intense perturbations from hindering model convergence and ensure the effectiveness of prior-based perturbations, we divide and reorganize them as panoramic collaborative perturbations. Our experimental results on three mainstream benchmarks demonstrate that the proposed method offers significant advantages over existing state-of-the-art (SoTA) solutions.
SGFormer: Spherical Geometry Transformer for 360 Depth Estimation
Apr 23, 2024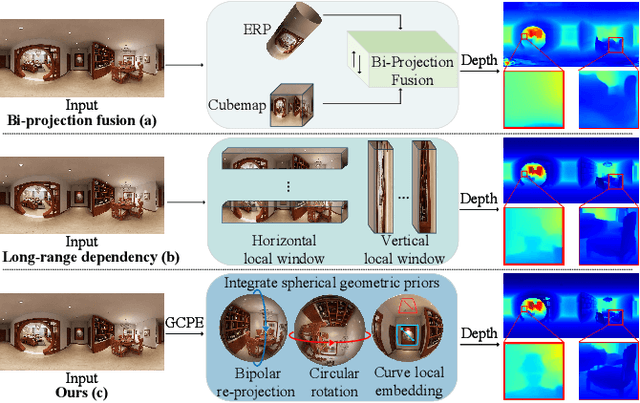
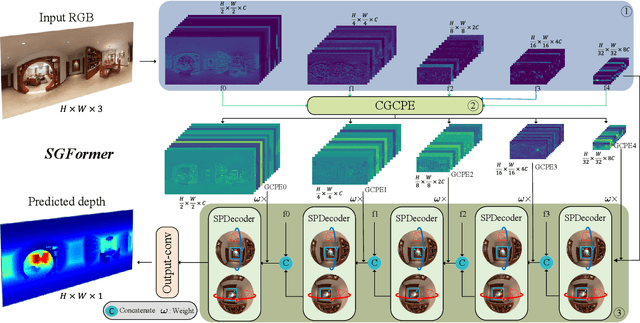
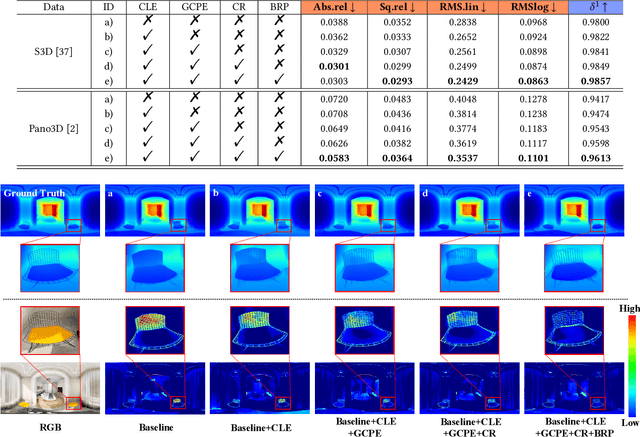
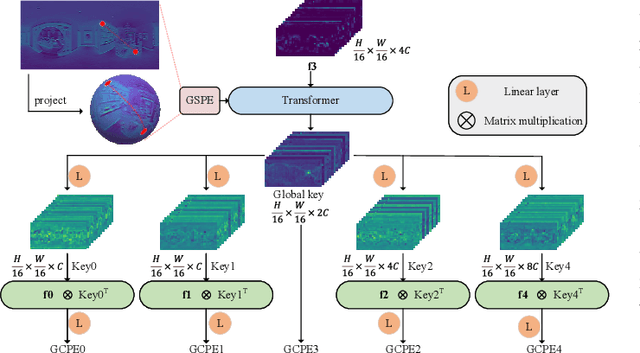
Panoramic distortion poses a significant challenge in 360 depth estimation, particularly pronounced at the north and south poles. Existing methods either adopt a bi-projection fusion strategy to remove distortions or model long-range dependencies to capture global structures, which can result in either unclear structure or insufficient local perception. In this paper, we propose a spherical geometry transformer, named SGFormer, to address the above issues, with an innovative step to integrate spherical geometric priors into vision transformers. To this end, we retarget the transformer decoder to a spherical prior decoder (termed SPDecoder), which endeavors to uphold the integrity of spherical structures during decoding. Concretely, we leverage bipolar re-projection, circular rotation, and curve local embedding to preserve the spherical characteristics of equidistortion, continuity, and surface distance, respectively. Furthermore, we present a query-based global conditional position embedding to compensate for spatial structure at varying resolutions. It not only boosts the global perception of spatial position but also sharpens the depth structure across different patches. Finally, we conduct extensive experiments on popular benchmarks, demonstrating our superiority over state-of-the-art solutions.
Improving Chinese Character Representation with Formation Tree
Apr 19, 2024Learning effective representations for Chinese characters presents unique challenges, primarily due to the vast number of characters and their continuous growth, which requires models to handle an expanding category space. Additionally, the inherent sparsity of character usage complicates the generalization of learned representations. Prior research has explored radical-based sequences to overcome these issues, achieving progress in recognizing unseen characters. However, these approaches fail to fully exploit the inherent tree structure of such sequences. To address these limitations and leverage established data properties, we propose Formation Tree-CLIP (FT-CLIP). This model utilizes formation trees to represent characters and incorporates a dedicated tree encoder, significantly improving performance in both seen and unseen character recognition tasks. We further introduce masking for to both character images and tree nodes, enabling efficient and effective training. This approach accelerates training significantly (by a factor of 2 or more) while enhancing accuracy. Extensive experiments show that processing characters through formation trees aligns better with their inherent properties than direct sequential methods, significantly enhancing the generality and usability of the representations.
360 Layout Estimation via Orthogonal Planes Disentanglement and Multi-view Geometric Consistency Perception
Dec 26, 2023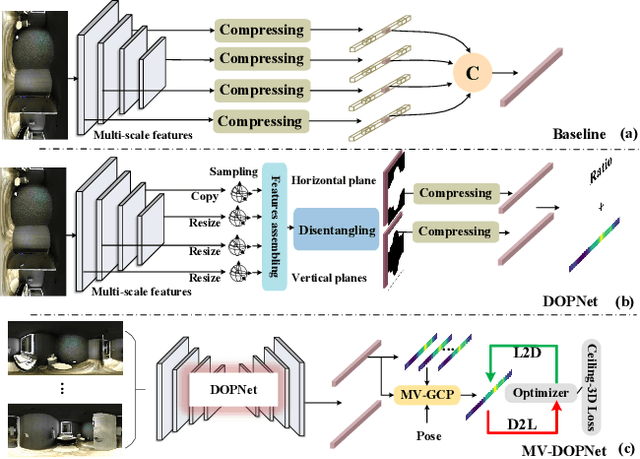
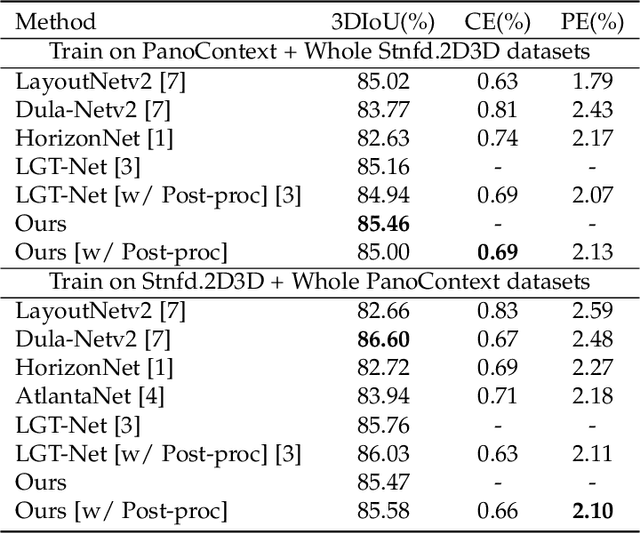
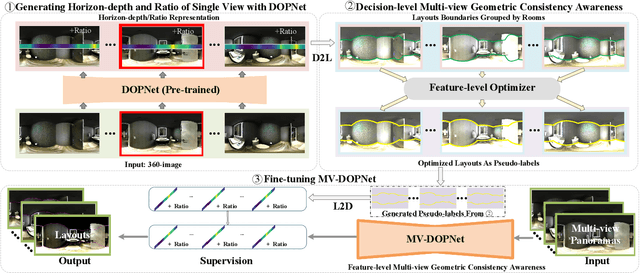

Existing panoramic layout estimation solutions tend to recover room boundaries from a vertically compressed sequence, yielding imprecise results as the compression process often muddles the semantics between various planes. Besides, these data-driven approaches impose an urgent demand for massive data annotations, which are laborious and time-consuming. For the first problem, we propose an orthogonal plane disentanglement network (termed DOPNet) to distinguish ambiguous semantics. DOPNet consists of three modules that are integrated to deliver distortion-free, semantics-clean, and detail-sharp disentangled representations, which benefit the subsequent layout recovery. For the second problem, we present an unsupervised adaptation technique tailored for horizon-depth and ratio representations. Concretely, we introduce an optimization strategy for decision-level layout analysis and a 1D cost volume construction method for feature-level multi-view aggregation, both of which are designed to fully exploit the geometric consistency across multiple perspectives. The optimizer provides a reliable set of pseudo-labels for network training, while the 1D cost volume enriches each view with comprehensive scene information derived from other perspectives. Extensive experiments demonstrate that our solution outperforms other SoTA models on both monocular layout estimation and multi-view layout estimation tasks.
NRTR: Neuron Reconstruction with Transformer from 3D Optical Microscopy Images
Dec 08, 2022The neuron reconstruction from raw Optical Microscopy (OM) image stacks is the basis of neuroscience. Manual annotation and semi-automatic neuron tracing algorithms are time-consuming and inefficient. Existing deep learning neuron reconstruction methods, although demonstrating exemplary performance, greatly demand complex rule-based components. Therefore, a crucial challenge is designing an end-to-end neuron reconstruction method that makes the overall framework simpler and model training easier. We propose a Neuron Reconstruction Transformer (NRTR) that, discarding the complex rule-based components, views neuron reconstruction as a direct set-prediction problem. To the best of our knowledge, NRTR is the first image-to-set deep learning model for end-to-end neuron reconstruction. In experiments using the BigNeuron and VISoR-40 datasets, NRTR achieves excellent neuron reconstruction results for comprehensive benchmarks and outperforms competitive baselines. Results of extensive experiments indicate that NRTR is effective at showing that neuron reconstruction is viewed as a set-prediction problem, which makes end-to-end model training available.
Functional Network: A Novel Framework for Interpretability of Deep Neural Networks
May 24, 2022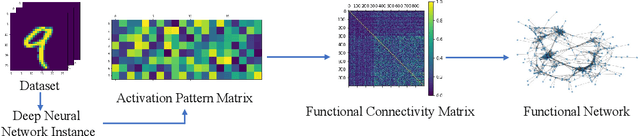

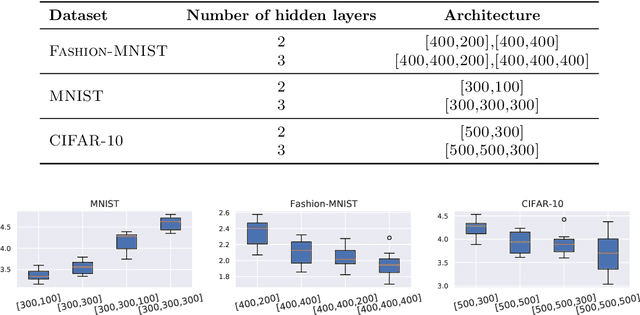
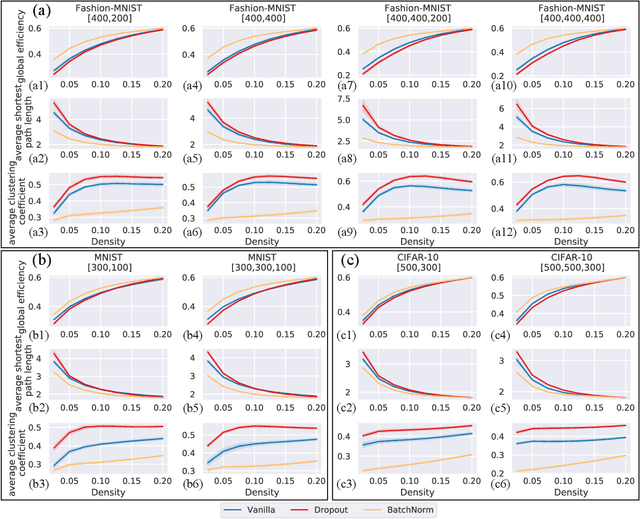
The layered structure of deep neural networks hinders the use of numerous analysis tools and thus the development of its interpretability. Inspired by the success of functional brain networks, we propose a novel framework for interpretability of deep neural networks, that is, the functional network. We construct the functional network of fully connected networks and explore its small-worldness. In our experiments, the mechanisms of regularization methods, namely, batch normalization and dropout, are revealed using graph theoretical analysis and topological data analysis. Our empirical analysis shows the following: (1) Batch normalization enhances model performance by increasing the global e ciency and the number of loops but reduces adversarial robustness by lowering the fault tolerance. (2) Dropout improves generalization and robustness of models by improving the functional specialization and fault tolerance. (3) The models with dierent regularizations can be clustered correctly according to their functional topological dierences, re ecting the great potential of the functional network and topological data analysis in interpretability.