 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360 Layout Estimation via Orthogonal Planes Disentanglement and Multi-view Geometric Consistency Perception
Paper and Code
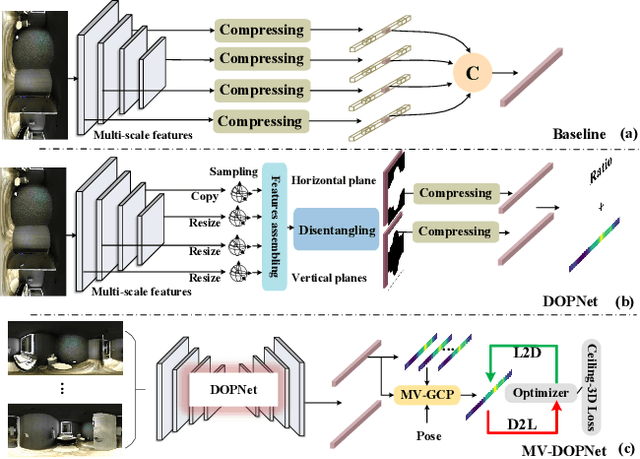
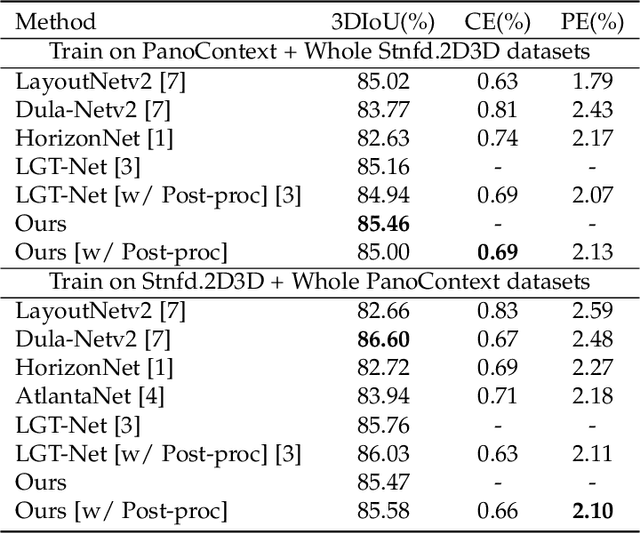
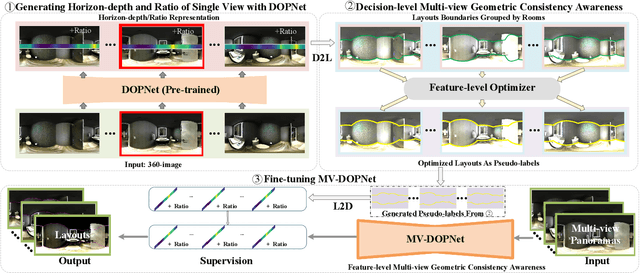

Existing panoramic layout estimation solutions tend to recover room boundaries from a vertically compressed sequence, yielding imprecise results as the compression process often muddles the semantics between various planes. Besides, these data-driven approaches impose an urgent demand for massive data annotations, which are laborious and time-consuming. For the first problem, we propose an orthogonal plane disentanglement network (termed DOPNet) to distinguish ambiguous semantics. DOPNet consists of three modules that are integrated to deliver distortion-free, semantics-clean, and detail-sharp disentangled representations, which benefit the subsequent layout recovery. For the second problem, we present an unsupervised adaptation technique tailored for horizon-depth and ratio representations. Concretely, we introduce an optimization strategy for decision-level layout analysis and a 1D cost volume construction method for feature-level multi-view aggregation, both of which are designed to fully exploit the geometric consistency across multiple perspectives. The optimizer provides a reliable set of pseudo-labels for network training, while the 1D cost volume enriches each view with comprehensive scene information derived from other perspectives. Extensive experiments demonstrate that our solution outperforms other SoTA models on both monocular layout estimation and multi-view layout estimation tasks.