 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Object Visibility Prediction in Autonomous Driving
Mar 06, 2024



With the rapid advancement of hardware and software technologies, research in autonomous driving has seen significant growth. The prevailing framework for multi-sensor autonomous driving encompasses sensor installation, perception, path planning, decision-making, and motion control. At the perception phase, a common approach involves utilizing neural networks to infer 3D bounding box (Bbox) attributes from raw sensor data, including classification, size, and orientation. In this paper, we present a novel attribute and its corresponding algorithm: 3D object visibility. By incorporating multi-task learning, the introduction of this attribute, visibility, negligibly affects the model's effectiveness and efficiency. Our proposal of this attribute and its computational strategy aims to expand the capabilities for downstream tasks, thereby enhancing the safety and reliability of real-time autonomous driving in real-world scenarios.
Mini-PointNetPlus: a local feature descriptor in deep learning model for 3d environment perception
Jul 25, 2023Common deep learning models for 3D environment perception often use pillarization/voxelization methods to convert point cloud data into pillars/voxels and then process it with a 2D/3D convolutional neural network (CNN). The pioneer work PointNet has been widely applied as a local feature descriptor, a fundamental component in deep learning models for 3D perception, to extract features of a point cloud. This is achieved by using a symmetric max-pooling operator which provides unique pillar/voxel features. However, by ignoring most of the points, the max-pooling operator causes an information loss, which reduces the model performance. To address this issue, we propose a novel local feature descriptor, mini-PointNetPlus, as an alternative for plug-and-play to PointNet. Our basic idea is to separately project the data points to the individual features considered, each leading to a permutation invariant. Thus, the proposed descriptor transforms an unordered point cloud to a stable order. The vanilla PointNet is proved to be a special case of our mini-PointNetPlus. Due to fully utilizing the features by the proposed descriptor, we demonstrate in experiment a considerable performance improvement for 3D perception.
LEST: Large-scale LiDAR Semantic Segmentation with Transformer
Jul 14, 2023Large-scale LiDAR-based point cloud semantic segmentation is a critical task in autonomous driving perception. Almost all of the previous state-of-the-art LiDAR semantic segmentation methods are variants of sparse 3D convolution. Although the Transformer architecture is becoming popular in the field of natural language processing and 2D computer vision, its application to large-scale point cloud semantic segmentation is still limited. In this paper, we propose a LiDAR sEmantic Segmentation architecture with pure Transformer, LEST. LEST comprises two novel components: a Space Filling Curve (SFC) Grouping strategy and a Distance-based Cosine Linear Transformer, DISCO. On the public nuScenes semantic segmentation validation set and SemanticKITTI test set, our model outperforms all the other state-of-the-art methods.
MVP-Net: Multiple View Pointwise Semantic Segmentation of Large-Scale Point Clouds
Jan 30, 2022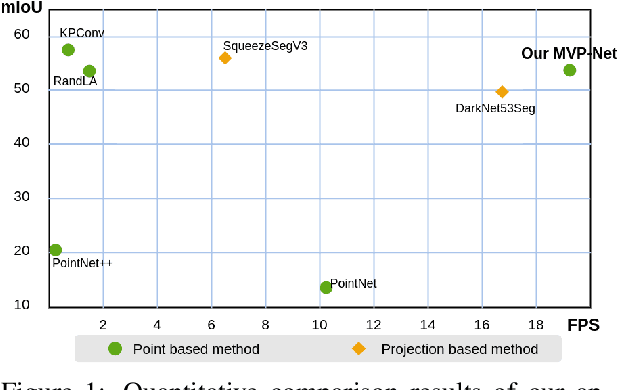


Semantic segmentation of 3D point cloud is an essential task for autonomous driving environment perception. The pipeline of most pointwise point cloud semantic segmentation methods includes points sampling, neighbor searching, feature aggregation, and classification. Neighbor searching method like K-nearest neighbors algorithm, KNN, has been widely applied. However, the complexity of KNN is always a bottleneck of efficiency. In this paper, we propose an end-to-end neural architecture, Multiple View Pointwise Net, MVP-Net, to efficiently and directly infer large-scale outdoor point cloud without KNN or any complex pre/postprocessing. Instead, assumption-based sorting and multi-rotation of point cloud methods are introduced to point feature aggregation and receptive field expanding. Numerical experiments show that the proposed MVP-Net is 11 times faster than the most efficient pointwise semantic segmentation method RandLA-Net and achieves the same accuracy on the large-scale benchmark SemanticKITTI dataset.