 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeBERT: A Language Spikformer Trained with Two-Stage Knowledge Distillation from BERT
Paper and Code
Aug 30, 2023
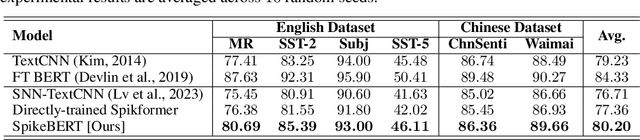


Spiking neural networks (SNNs) offer a promising avenue to implement deep neural networks in a more energy-efficient way. However, the network architectures of existing SNNs for language tasks are too simplistic, and deep architectures have not been fully explored, resulting in a significant performance gap compared to mainstream transformer-based networks such as BERT. To this end, we improve a recently-proposed spiking transformer (i.e., Spikformer) to make it possible to process language tasks and propose a two-stage knowledge distillation method for training it, which combines pre-training by distilling knowledge from BERT with a large collection of unlabelled texts and fine-tuning with task-specific instances via knowledge distillation again from the BERT fine-tuned on the same training examples. Through extensive experimentation, we show that the models trained with our method, named SpikeBERT, outperform state-of-the-art SNNs and even achieve comparable results to BERTs on text classification tasks for both English and Chinese with much less energy consumption.