 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLA-Sign: Looped Transformers with Geometry-aware Alignment for Skeleton-based Sign Language Recognition
Mar 30, 2026Skeleton-based isolated sign language recognition (ISLR) demands fine-grained understanding of articulated motion across multiple spatial scales, from subtle finger movements to global body dynamics. Existing approaches typically rely on deep feed-forward architectures, which increase model capacity but lack mechanisms for recurrent refinement and structured representation. We propose LA-Sign, a looped transformer framework with geometry-aware alignment for ISLR. Instead of stacking deeper layers, LA-Sign derives its depth from recurrence, repeatedly revisiting latent representations to progressively refine motion understanding under shared parameters. To further regularise this refinement process, we present a geometry-aware contrastive objective that projects skeletal and textual features into an adaptive hyperbolic space, encouraging multi-scale semantic organisation. We study three looping designs and multiple geometric manifolds, demonstrating that encoder-decoder looping combined with adaptive Poincare alignment yields the strongest performance. Extensive experiments on WLASL and MSASL benchmarks show that LA-Sign achieves state-of-the-art results while using fewer unique layers, highlighting the effectiveness of recurrent latent refinement and geometry-aware representation learning for sign language recognition.
MulVul: Retrieval-augmented Multi-Agent Code Vulnerability Detection via Cross-Model Prompt Evolution
Jan 26, 2026Large Language Models (LLMs) struggle to automate real-world vulnerability detection due to two key limitations: the heterogeneity of vulnerability patterns undermines the effectiveness of a single unified model, and manual prompt engineering for massive weakness categories is unscalable. To address these challenges, we propose \textbf{MulVul}, a retrieval-augmented multi-agent framework designed for precise and broad-coverage vulnerability detection. MulVul adopts a coarse-to-fine strategy: a \emph{Router} agent first predicts the top-$k$ coarse categories and then forwards the input to specialized \emph{Detector} agents, which identify the exact vulnerability types. Both agents are equipped with retrieval tools to actively source evidence from vulnerability knowledge bases to mitigate hallucinations. Crucially, to automate the generation of specialized prompts, we design \emph{Cross-Model Prompt Evolution}, a prompt optimization mechanism where a generator LLM iteratively refines candidate prompts while a distinct executor LLM validates their effectiveness. This decoupling mitigates the self-correction bias inherent in single-model optimization. Evaluated on 130 CWE types, MulVul achieves 34.79\% Macro-F1, outperforming the best baseline by 41.5\%. Ablation studies validate cross-model prompt evolution, which boosts performance by 51.6\% over manual prompts by effectively handling diverse vulnerability patterns.
AXIOM: Benchmarking LLM-as-a-Judge for Code via Rule-Based Perturbation and Multisource Quality Calibration
Dec 23, 2025Large language models (LLMs) have been increasingly deployed in real-world software engineering, fostering the development of code evaluation metrics to study the quality of LLM-generated code. Conventional rule-based metrics merely score programs based on their surface-level similarities with reference programs instead of analyzing functionality and code quality in depth. To address this limitation, researchers have developed LLM-as-a-judge metrics, prompting LLMs to evaluate and score code, and curated various code evaluation benchmarks to validate their effectiveness. However, these benchmarks suffer from critical limitations, hindering reliable assessments of evaluation capability: Some feature coarse-grained binary labels, which reduce rich code behavior to a single bit of information, obscuring subtle errors. Others propose fine-grained but subjective, vaguely-defined evaluation criteria, introducing unreliability in manually-annotated scores, which is the ground-truth they rely on. Furthermore, they often use uncontrolled data synthesis methods, leading to unbalanced score distributions that poorly represent real-world code generation scenarios. To curate a diverse benchmark with programs of well-balanced distributions across various quality levels and streamline the manual annotation procedure, we propose AXIOM, a novel perturbation-based framework for synthesizing code evaluation benchmarks at scale. It reframes program scores as the refinement effort needed for deployment, consisting of two stages: (1) Rule-guided perturbation, which prompts LLMs to apply sequences of predefined perturbation rules to existing high-quality programs to modify their functionality and code quality, enabling us to precisely control each program's target score to achieve balanced score distributions. (2) Multisource quality calibration, which first selects a subset of...
Siformer: Feature-isolated Transformer for Efficient Skeleton-based Sign Language Recognition
Mar 26, 2025Sign language recognition (SLR) refers to interpreting sign language glosses from given videos automatically. This research area presents a complex challenge in computer vision because of the rapid and intricate movements inherent in sign languages, which encompass hand gestures, body postures, and even facial expressions. Recently, skeleton-based action recognition has attracted increasing attention due to its ability to handle variations in subjects and backgrounds independently. However, current skeleton-based SLR methods exhibit three limitations: 1) they often neglect the importance of realistic hand poses, where most studies train SLR models on non-realistic skeletal representations; 2) they tend to assume complete data availability in both training or inference phases, and capture intricate relationships among different body parts collectively; 3) these methods treat all sign glosses uniformly, failing to account for differences in complexity levels regarding skeletal representations. To enhance the realism of hand skeletal representations, we present a kinematic hand pose rectification method for enforcing constraints. Mitigating the impact of missing data, we propose a feature-isolated mechanism to focus on capturing local spatial-temporal context. This method captures the context concurrently and independently from individual features, thus enhancing the robustness of the SLR model. Additionally, to adapt to varying complexity levels of sign glosses, we develop an input-adaptive inference approach to optimise computational efficiency and accuracy. Experimental results demonstrate the effectiveness of our approach, as evidenced by achieving a new state-of-the-art (SOTA) performance on WLASL100 and LSA64. For WLASL100, we achieve a top-1 accuracy of 86.50\%, marking a relative improvement of 2.39% over the previous SOTA. For LSA64, we achieve a top-1 accuracy of 99.84%.
Can LLMs Replace Human Evaluators? An Empirical Study of LLM-as-a-Judge in Software Engineering
Feb 10, 2025Recently, large language models (LLMs) have been deployed to tackle various software engineering (SE) tasks like code generation, significantly advancing the automation of SE tasks. However, assessing the quality of these LLM-generated code and text remains challenging. The commonly used Pass@k metric necessitates extensive unit tests and configured environments, demands a high labor cost, and is not suitable for evaluating LLM-generated text. Conventional metrics like BLEU, which measure only lexical rather than semantic similarity, have also come under scrutiny. In response, a new trend has emerged to employ LLMs for automated evaluation, known as LLM-as-a-judge. These LLM-as-a-judge methods are claimed to better mimic human assessment than conventional metrics without relying on high-quality reference answers. Nevertheless, their exact human alignment in SE tasks remains unexplored. In this paper, we empirically explore LLM-as-a-judge methods for evaluating SE tasks, focusing on their alignment with human judgments. We select seven LLM-as-a-judge methods that utilize general-purpose LLMs, alongside two LLMs specifically fine-tuned for evaluation. After generating and manually scoring LLM responses on three recent SE datasets of code translation, code generation, and code summarization, we then prompt these methods to evaluate each response. Finally, we compare the scores generated by these methods with human evaluation. The results indicate that output-based methods reach the highest Pearson correlation of 81.32 and 68.51 with human scores in code translation and generation, achieving near-human evaluation, noticeably outperforming ChrF++, one of the best conventional metrics, at 34.23 and 64.92. Such output-based methods prompt LLMs to output judgments directly, and exhibit more balanced score distributions that resemble human score patterns. Finally, we provide...
The Prompt Alchemist: Automated LLM-Tailored Prompt Optimization for Test Case Generation
Jan 02, 2025



Test cases are essential for validating the reliability and quality of software applications. Recent studies have demonstrated the capability of Large Language Models (LLMs) to generate useful test cases for given source code. However, the existing work primarily relies on human-written plain prompts, which often leads to suboptimal results since the performance of LLMs can be highly influenced by the prompts. Moreover, these approaches use the same prompt for all LLMs, overlooking the fact that different LLMs might be best suited to different prompts. Given the wide variety of possible prompt formulations, automatically discovering the optimal prompt for each LLM presents a significant challenge. Although there are methods on automated prompt optimization in the natural language processing field, they are hard to produce effective prompts for the test case generation task. First, the methods iteratively optimize prompts by simply combining and mutating existing ones without proper guidance, resulting in prompts that lack diversity and tend to repeat the same errors in the generated test cases. Second, the prompts are generally lack of domain contextual knowledge, limiting LLMs' performance in the task.
Assessing AI Detectors in Identifying AI-Generated Code: Implications for Education
Jan 08, 2024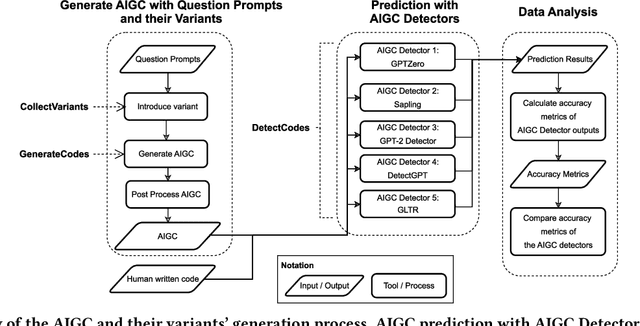


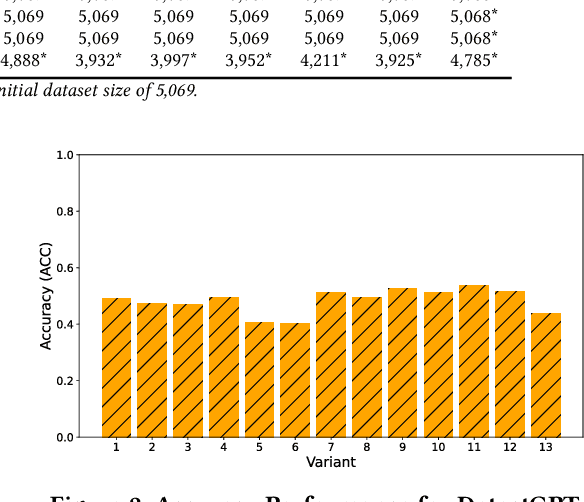
Educators are increasingly concerned about the usage of Large Language Models (LLMs) such as ChatGPT in programming education, particularly regarding the potential exploitation of imperfections in Artificial Intelligence Generated Content (AIGC) Detectors for academic misconduct. In this paper, we present an empirical study where the LLM is examined for its attempts to bypass detection by AIGC Detectors. This is achieved by generating code in response to a given question using different variants. We collected a dataset comprising 5,069 samples, with each sample consisting of a textual description of a coding problem and its corresponding human-written Python solution codes. These samples were obtained from various sources, including 80 from Quescol, 3,264 from Kaggle, and 1,725 from LeetCode. From the dataset, we created 13 sets of code problem variant prompts, which were used to instruct ChatGPT to generate the outputs. Subsequently, we assessed the performance of five AIGC detectors. Our results demonstrate that existing AIGC Detectors perform poorly in distinguishing between human-written code and AI-generated code.
Robustness Evaluation in Hand Pose Estimation Models using Metamorphic Testing
Mar 08, 2023



Hand pose estimation (HPE) is a task that predicts and describes the hand poses from images or video frames. When HPE models estimate hand poses captured in a laboratory or under controlled environments, they normally deliver good performance. However, the real-world environment is complex, and various uncertainties may happen, which could degrade the performance of HPE models. For example, the hands could be occluded, the visibility of hands could be reduced by imperfect exposure rate, and the contour of hands prone to be blurred during fast hand movements. In this work, we adopt metamorphic testing to evaluate the robustness of HPE models and provide suggestions on the choice of HPE models for different applications. The robustness evaluation was conducted on four state-of-the-art models, namely MediaPipe hands, OpenPose, BodyHands, and NSRM hand. We found that on average more than 80\% of the hands could not be identified by BodyHands, and at least 50\% of hands could not be identified by MediaPipe hands when diagonal motion blur is introduced, while an average of more than 50\% of strongly underexposed hands could not be correctly estimated by NSRM hand. Similarly, applying occlusions on only four hand joints will also largely degrade the performance of these models. The experimental results show that occlusions, illumination variations, and motion blur are the main obstacles to the performance of existing HPE models. These findings may pave the way for researchers to improve the performance and robustness of hand pose estimation models and their applications.
ASDF: A Differential Testing Framework for Automatic Speech Recognition Systems
Feb 11, 2023
Recent years have witnessed wider adoption of Automated Speech Recognition (ASR) techniques in various domains. Consequently, evaluating and enhancing the quality of ASR systems is of great importance. This paper proposes ASDF, an Automated Speech Recognition Differential Testing Framework for testing ASR systems. ASDF extends an existing ASR testing tool, the CrossASR++, which synthesizes test cases from a text corpus. However, CrossASR++ fails to make use of the text corpus efficiently and provides limited information on how the failed test cases can improve ASR systems. To address these limitations, our tool incorporates two novel features: (1) a text transformation module to boost the number of generated test cases and uncover more errors in ASR systems and (2) a phonetic analysis module to identify on which phonemes the ASR system tend to produce errors. ASDF generates more high-quality test cases by applying various text transformation methods (e.g., change tense) to the texts in failed test cases. By doing so, ASDF can utilize a small text corpus to generate a large number of audio test cases, something which CrossASR++ is not capable of. In addition, ASDF implements more metrics to evaluate the performance of ASR systems from multiple perspectives. ASDF performs phonetic analysis on the identified failed test cases to identify the phonemes that ASR systems tend to transcribe incorrectly, providing useful information for developers to improve ASR systems. The demonstration video of our tool is made online at https://www.youtube.com/watch?v=DzVwfc3h9As. The implementation is available at https://github.com/danielyuenhx/asdf-differential-testing.
SERCNN: Stacked Embedding Recurrent Convolutional Neural Network in Detecting Depression on Twitter
Aug 05, 2022
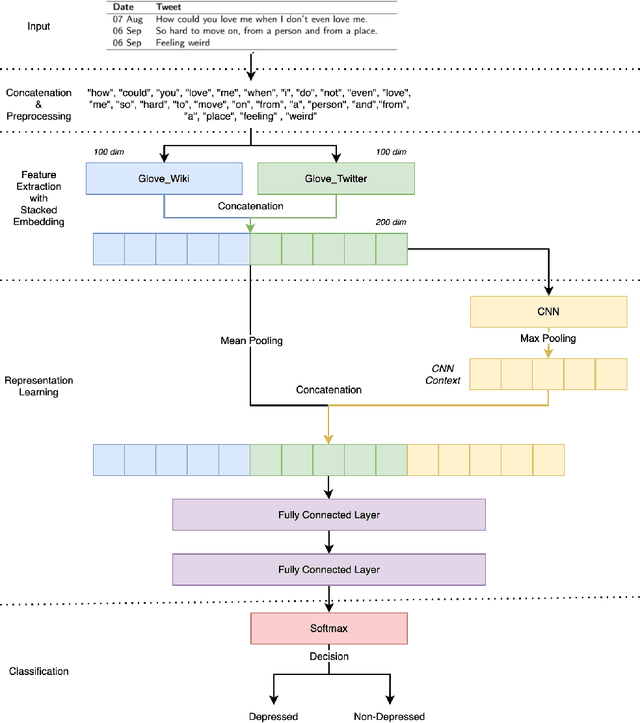
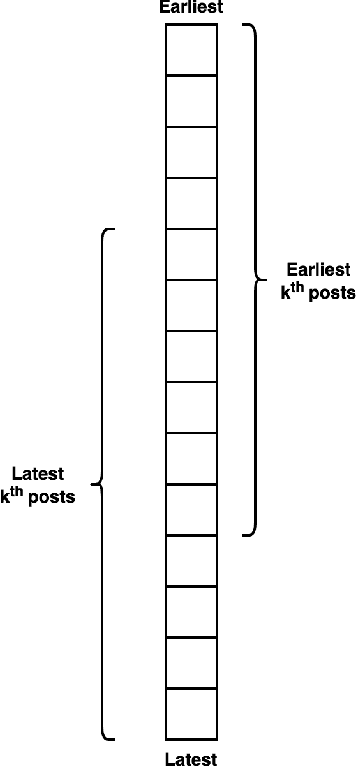
Conventional approaches to identify depression are not scalable, and the public has limited awareness of mental health, especially in developing countries. As evident by recent studies, social media has the potential to complement mental health screening on a greater scale. The vast amount of first-person narrative posts in chronological order can provide insights into one's thoughts, feelings, behavior, or mood for some time, enabling a better understanding of depression symptoms reflected in the online space. In this paper, we propose SERCNN, which improves the user representation by (1) stacking two pretrained embeddings from different domains and (2) reintroducing the embedding context to the MLP classifier. Our SERCNN shows great performance over state-of-the-art and other baselines, achieving 93.7% accuracy in a 5-fold cross-validation setting. Since not all users share the same level of online activity, we introduced the concept of a fixed observation window that quantifies the observation period in a predefined number of posts. With as minimal as 10 posts per user, SERCNN performed exceptionally well with an 87% accuracy, which is on par with the BERT model, while having 98% less in the number of parameters. Our findings open up a promising direction for detecting depression on social media with a smaller number of posts for inference, towards creating solutions for a cost-effective and timely intervention. We hope that our work can bring this research area closer to real-world adoption in existing clinical practice.