 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiformer: Feature-isolated Transformer for Efficient Skeleton-based Sign Language Recognition
Mar 26, 2025Sign language recognition (SLR) refers to interpreting sign language glosses from given videos automatically. This research area presents a complex challenge in computer vision because of the rapid and intricate movements inherent in sign languages, which encompass hand gestures, body postures, and even facial expressions. Recently, skeleton-based action recognition has attracted increasing attention due to its ability to handle variations in subjects and backgrounds independently. However, current skeleton-based SLR methods exhibit three limitations: 1) they often neglect the importance of realistic hand poses, where most studies train SLR models on non-realistic skeletal representations; 2) they tend to assume complete data availability in both training or inference phases, and capture intricate relationships among different body parts collectively; 3) these methods treat all sign glosses uniformly, failing to account for differences in complexity levels regarding skeletal representations. To enhance the realism of hand skeletal representations, we present a kinematic hand pose rectification method for enforcing constraints. Mitigating the impact of missing data, we propose a feature-isolated mechanism to focus on capturing local spatial-temporal context. This method captures the context concurrently and independently from individual features, thus enhancing the robustness of the SLR model. Additionally, to adapt to varying complexity levels of sign glosses, we develop an input-adaptive inference approach to optimise computational efficiency and accuracy. Experimental results demonstrate the effectiveness of our approach, as evidenced by achieving a new state-of-the-art (SOTA) performance on WLASL100 and LSA64. For WLASL100, we achieve a top-1 accuracy of 86.50\%, marking a relative improvement of 2.39% over the previous SOTA. For LSA64, we achieve a top-1 accuracy of 99.84%.
Assessing AI Detectors in Identifying AI-Generated Code: Implications for Education
Jan 08, 2024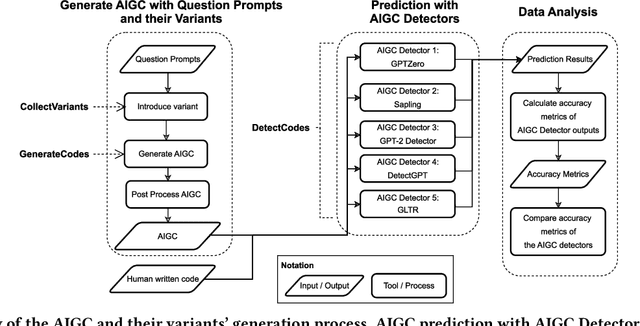


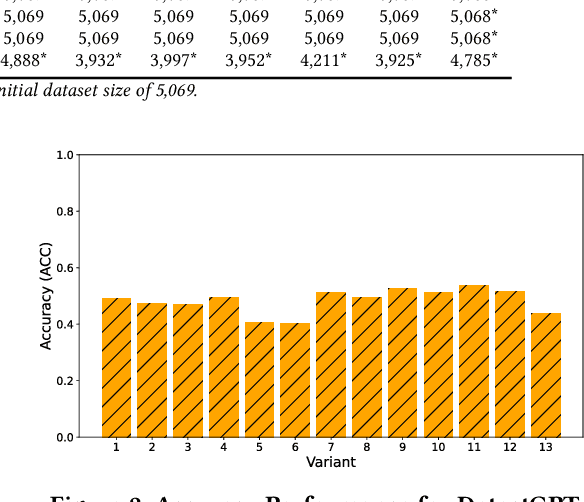
Educators are increasingly concerned about the usage of Large Language Models (LLMs) such as ChatGPT in programming education, particularly regarding the potential exploitation of imperfections in Artificial Intelligence Generated Content (AIGC) Detectors for academic misconduct. In this paper, we present an empirical study where the LLM is examined for its attempts to bypass detection by AIGC Detectors. This is achieved by generating code in response to a given question using different variants. We collected a dataset comprising 5,069 samples, with each sample consisting of a textual description of a coding problem and its corresponding human-written Python solution codes. These samples were obtained from various sources, including 80 from Quescol, 3,264 from Kaggle, and 1,725 from LeetCode. From the dataset, we created 13 sets of code problem variant prompts, which were used to instruct ChatGPT to generate the outputs. Subsequently, we assessed the performance of five AIGC detectors. Our results demonstrate that existing AIGC Detectors perform poorly in distinguishing between human-written code and AI-generated code.
Robustness Evaluation in Hand Pose Estimation Models using Metamorphic Testing
Mar 08, 2023



Hand pose estimation (HPE) is a task that predicts and describes the hand poses from images or video frames. When HPE models estimate hand poses captured in a laboratory or under controlled environments, they normally deliver good performance. However, the real-world environment is complex, and various uncertainties may happen, which could degrade the performance of HPE models. For example, the hands could be occluded, the visibility of hands could be reduced by imperfect exposure rate, and the contour of hands prone to be blurred during fast hand movements. In this work, we adopt metamorphic testing to evaluate the robustness of HPE models and provide suggestions on the choice of HPE models for different applications. The robustness evaluation was conducted on four state-of-the-art models, namely MediaPipe hands, OpenPose, BodyHands, and NSRM hand. We found that on average more than 80\% of the hands could not be identified by BodyHands, and at least 50\% of hands could not be identified by MediaPipe hands when diagonal motion blur is introduced, while an average of more than 50\% of strongly underexposed hands could not be correctly estimated by NSRM hand. Similarly, applying occlusions on only four hand joints will also largely degrade the performance of these models. The experimental results show that occlusions, illumination variations, and motion blur are the main obstacles to the performance of existing HPE models. These findings may pave the way for researchers to improve the performance and robustness of hand pose estimation models and their applications.
ASDF: A Differential Testing Framework for Automatic Speech Recognition Systems
Feb 11, 2023
Recent years have witnessed wider adoption of Automated Speech Recognition (ASR) techniques in various domains. Consequently, evaluating and enhancing the quality of ASR systems is of great importance. This paper proposes ASDF, an Automated Speech Recognition Differential Testing Framework for testing ASR systems. ASDF extends an existing ASR testing tool, the CrossASR++, which synthesizes test cases from a text corpus. However, CrossASR++ fails to make use of the text corpus efficiently and provides limited information on how the failed test cases can improve ASR systems. To address these limitations, our tool incorporates two novel features: (1) a text transformation module to boost the number of generated test cases and uncover more errors in ASR systems and (2) a phonetic analysis module to identify on which phonemes the ASR system tend to produce errors. ASDF generates more high-quality test cases by applying various text transformation methods (e.g., change tense) to the texts in failed test cases. By doing so, ASDF can utilize a small text corpus to generate a large number of audio test cases, something which CrossASR++ is not capable of. In addition, ASDF implements more metrics to evaluate the performance of ASR systems from multiple perspectives. ASDF performs phonetic analysis on the identified failed test cases to identify the phonemes that ASR systems tend to transcribe incorrectly, providing useful information for developers to improve ASR systems. The demonstration video of our tool is made online at https://www.youtube.com/watch?v=DzVwfc3h9As. The implementation is available at https://github.com/danielyuenhx/asdf-differential-testing.
SERCNN: Stacked Embedding Recurrent Convolutional Neural Network in Detecting Depression on Twitter
Aug 05, 2022
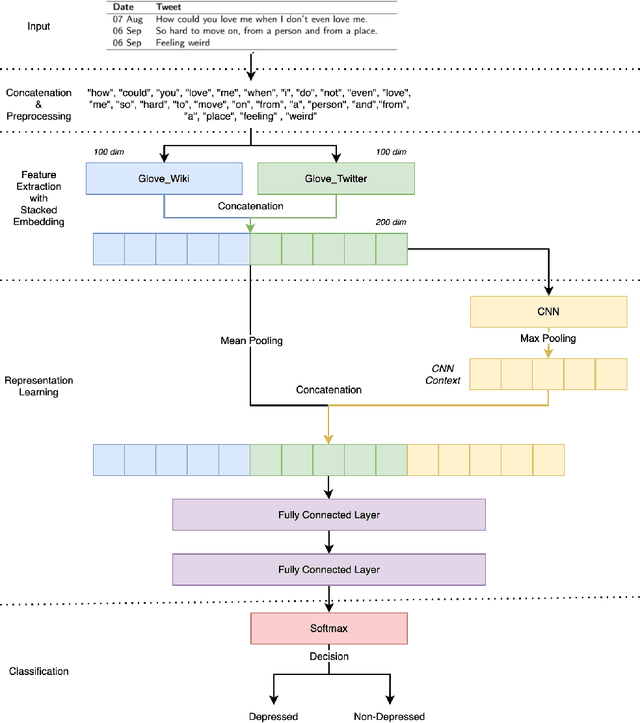
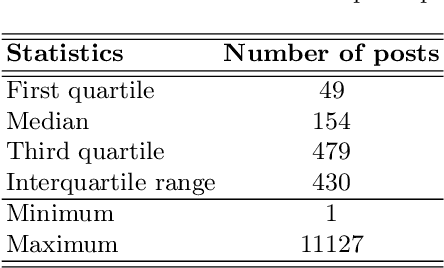
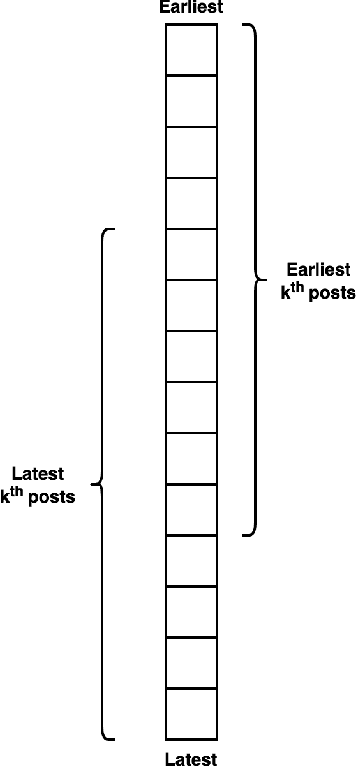
Conventional approaches to identify depression are not scalable, and the public has limited awareness of mental health, especially in developing countries. As evident by recent studies, social media has the potential to complement mental health screening on a greater scale. The vast amount of first-person narrative posts in chronological order can provide insights into one's thoughts, feelings, behavior, or mood for some time, enabling a better understanding of depression symptoms reflected in the online space. In this paper, we propose SERCNN, which improves the user representation by (1) stacking two pretrained embeddings from different domains and (2) reintroducing the embedding context to the MLP classifier. Our SERCNN shows great performance over state-of-the-art and other baselines, achieving 93.7% accuracy in a 5-fold cross-validation setting. Since not all users share the same level of online activity, we introduced the concept of a fixed observation window that quantifies the observation period in a predefined number of posts. With as minimal as 10 posts per user, SERCNN performed exceptionally well with an 87% accuracy, which is on par with the BERT model, while having 98% less in the number of parameters. Our findings open up a promising direction for detecting depression on social media with a smaller number of posts for inference, towards creating solutions for a cost-effective and timely intervention. We hope that our work can bring this research area closer to real-world adoption in existing clinical practice.
Metamorphic Testing-based Adversarial Attack to Fool Deepfake Detectors
Apr 19, 2022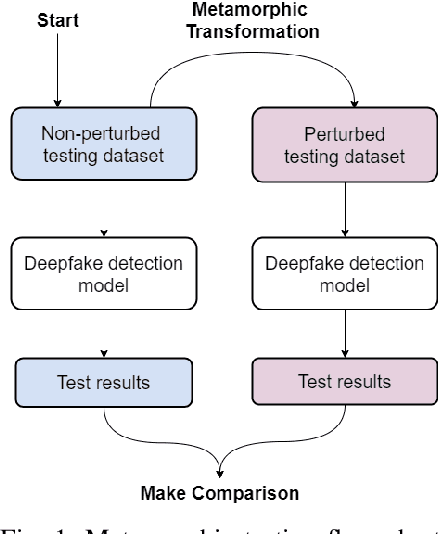
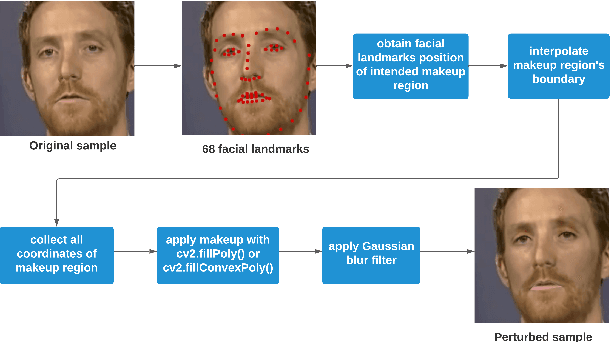

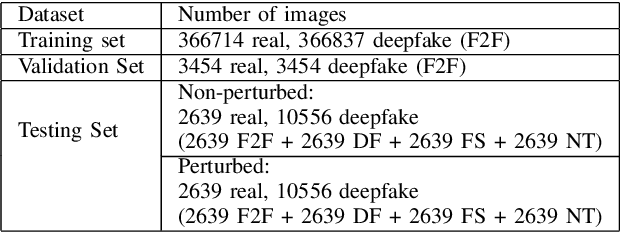
Deepfakes utilise Artificial Intelligence (AI) techniques to create synthetic media where the likeness of one person is replaced with another. There are growing concerns that deepfakes can be maliciously used to create misleading and harmful digital contents. As deepfakes become more common, there is a dire need for deepfake detection technology to help spot deepfake media. Present deepfake detection models are able to achieve outstanding accuracy (>90%). However, most of them are limited to within-dataset scenario, where the same dataset is used for training and testing. Most models do not generalise well enough in cross-dataset scenario, where models are tested on unseen datasets from another source. Furthermore, state-of-the-art deepfake detection models rely on neural network-based classification models that are known to be vulnerable to adversarial attacks. Motivated by the need for a robust deepfake detection model, this study adapts metamorphic testing (MT) principles to help identify potential factors that could influence the robustness of the examined model, while overcoming the test oracle problem in this domain. Metamorphic testing is specifically chosen as the testing technique as it fits our demand to address learning-based system testing with probabilistic outcomes from largely black-box components, based on potentially large input domains. We performed our evaluations on MesoInception-4 and TwoStreamNet models, which are the state-of-the-art deepfake detection models. This study identified makeup application as an adversarial attack that could fool deepfake detectors. Our experimental results demonstrate that both the MesoInception-4 and TwoStreamNet models degrade in their performance by up to 30\% when the input data is perturbed with makeup.
Fairness Evaluation in Deepfake Detection Models using Metamorphic Testing
Mar 14, 2022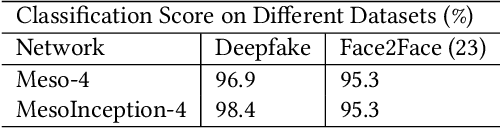
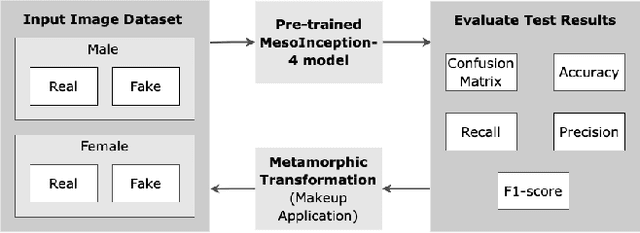

Fairness of deepfake detectors in the presence of anomalies are not well investigated, especially if those anomalies are more prominent in either male or female subjects. The primary motivation for this work is to evaluate how deepfake detection model behaves under such anomalies. However, due to the black-box nature of deep learning (DL) and artificial intelligence (AI) systems, it is hard to predict the performance of a model when the input data is modified. Crucially, if this defect is not addressed properly, it will adversely affect the fairness of the model and result in discrimination of certain sub-population unintentionally. Therefore, the objective of this work is to adopt metamorphic testing to examine the reliability of the selected deepfake detection model, and how the transformation of input variation places influence on the output. We have chosen MesoInception-4, a state-of-the-art deepfake detection model, as the target model and makeup as the anomalies. Makeups are applied through utilizing the Dlib library to obtain the 68 facial landmarks prior to filling in the RGB values. Metamorphic relations are derived based on the notion that realistic perturbations of the input images, such as makeup, involving eyeliners, eyeshadows, blushes, and lipsticks (which are common cosmetic appearance) applied to male and female images, should not alter the output of the model by a huge margin. Furthermore, we narrow down the scope to focus on revealing potential gender biases in DL and AI systems. Specifically, we are interested to examine whether MesoInception-4 model produces unfair decisions, which should be considered as a consequence of robustness issues. The findings from our work have the potential to pave the way for new research directions in the quality assurance and fairness in DL and AI systems.
Robustness Evaluation of Stacked Generative Adversarial Networks using Metamorphic Testing
Mar 04, 2021



Synthesising photo-realistic images from natural language is one of the challenging problems in computer vision. Over the past decade, a number of approaches have been proposed, of which the improved Stacked Generative Adversarial Network (StackGAN-v2) has proven capable of generating high resolution images that reflect the details specified in the input text descriptions. In this paper, we aim to assess the robustness and fault-tolerance capability of the StackGAN-v2 model by introducing variations in the training data. However, due to the working principle of Generative Adversarial Network (GAN), it is difficult to predict the output of the model when the training data are modified. Hence, in this work, we adopt Metamorphic Testing technique to evaluate the robustness of the model with a variety of unexpected training dataset. As such, we first implement StackGAN-v2 algorithm and test the pre-trained model provided by the original authors to establish a ground truth for our experiments. We then identify a metamorphic relation, from which test cases are generated. Further, metamorphic relations were derived successively based on the observations of prior test results. Finally, we synthesise the results from our experiment of all the metamorphic relations and found that StackGAN-v2 algorithm is susceptible to input images with obtrusive objects, even if it overlaps with the main object minimally, which was not reported by the authors and users of StackGAN-v2 model. The proposed metamorphic relations can be applied to other text-to-image synthesis models to not only verify the robustness but also to help researchers understand and interpret the results made by the machine learning models.
Crowd Behavior Analysis: A Review where Physics meets Biology
Nov 20, 2015
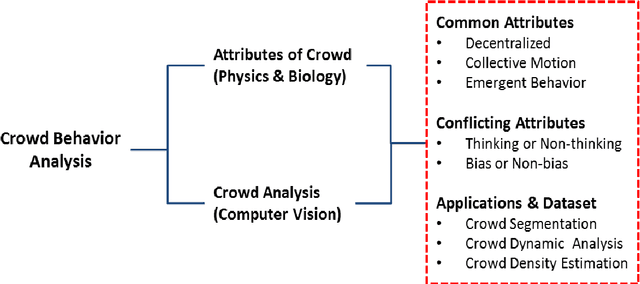

Although the traits emerged in a mass gathering are often non-deliberative, the act of mass impulse may lead to irre- vocable crowd disasters. The two-fold increase of carnage in crowd since the past two decades has spurred significant advances in the field of computer vision, towards effective and proactive crowd surveillance. Computer vision stud- ies related to crowd are observed to resonate with the understanding of the emergent behavior in physics (complex systems) and biology (animal swarm). These studies, which are inspired by biology and physics, share surprisingly common insights, and interesting contradictions. However, this aspect of discussion has not been fully explored. Therefore, this survey provides the readers with a review of the state-of-the-art methods in crowd behavior analysis from the physics and biologically inspired perspectives. We provide insights and comprehensive discussions for a broader understanding of the underlying prospect of blending physics and biology studies in computer vision.
* Accepted in Neurocomputing, 31 pages, 180 references
Detection of Salient Regions in Crowded Scenes
Oct 15, 2014



The increasing number of cameras and a handful of human operators to monitor the video inputs from hundreds of cameras leave the system ill equipped to fulfil the task of detecting anomalies. Thus, there is a dire need to automatically detect regions that require immediate attention for a more effective and proactive surveillance. We propose a framework that utilises the temporal variations in the flow field of a crowd scene to automatically detect salient regions, while eliminating the need to have prior knowledge of the scene or training. We deem the flow fields to be a dynamic system and adopt the stability theory of dynamical systems, to determine the motion dynamics within a given area. In the context of this work, salient regions refer to areas with high motion dynamics, where points in a particular region are unstable. Experimental results on public, crowd scenes have shown the effectiveness of the proposed method in detecting salient regions which correspond to unstable flow, occlusions, bottlenecks, entries and exits.