 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing AI Detectors in Identifying AI-Generated Code: Implications for Education
Paper and Code
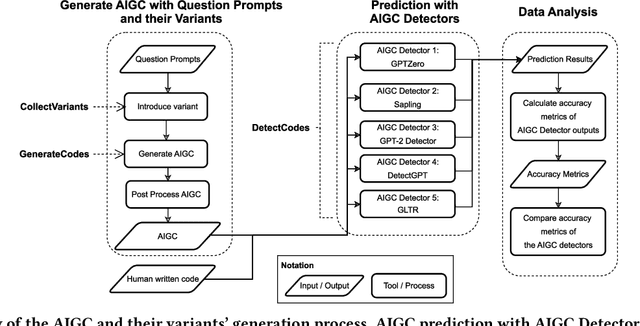


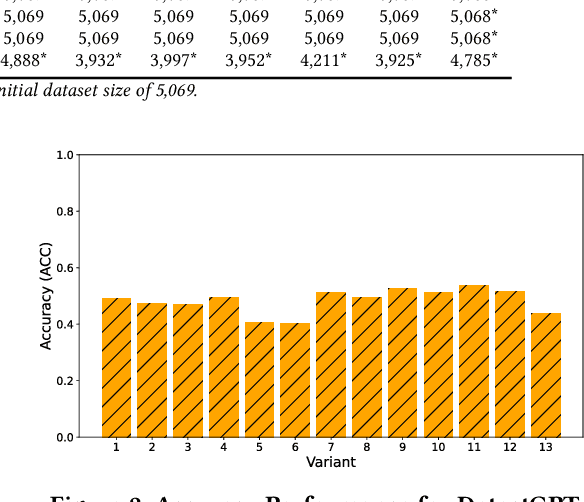
Educators are increasingly concerned about the usage of Large Language Models (LLMs) such as ChatGPT in programming education, particularly regarding the potential exploitation of imperfections in Artificial Intelligence Generated Content (AIGC) Detectors for academic misconduct. In this paper, we present an empirical study where the LLM is examined for its attempts to bypass detection by AIGC Detectors. This is achieved by generating code in response to a given question using different variants. We collected a dataset comprising 5,069 samples, with each sample consisting of a textual description of a coding problem and its corresponding human-written Python solution codes. These samples were obtained from various sources, including 80 from Quescol, 3,264 from Kaggle, and 1,725 from LeetCode. From the dataset, we created 13 sets of code problem variant prompts, which were used to instruct ChatGPT to generate the outputs. Subsequently, we assessed the performance of five AIGC detectors. Our results demonstrate that existing AIGC Detectors perform poorly in distinguishing between human-written code and AI-generated code.