 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVRPTEST: Evaluating Visual Referring Prompting in Large Multimodal Models
Dec 07, 2023



With recent advancements in Large Multimodal Models (LMMs) across various domains, a novel prompting method called visual referring prompting has emerged, showing significant potential in enhancing human-computer interaction within multimodal systems. This method offers a more natural and flexible approach to human interaction with these systems compared to traditional text descriptions or coordinates. However, the categorization of visual referring prompting remains undefined, and its impact on the performance of LMMs has yet to be formally examined. In this study, we conduct the first comprehensive analysis of LMMs using a variety of visual referring prompting strategies. We introduce a benchmark dataset called VRPTEST, comprising 3 different visual tasks and 2,275 images, spanning diverse combinations of prompt strategies. Using VRPTEST, we conduct a comprehensive evaluation of eight versions of prominent open-source and proprietary foundation models, including two early versions of GPT-4V. We develop an automated assessment framework based on software metamorphic testing techniques to evaluate the accuracy of LMMs without the need for human intervention or manual labeling. We find that the current proprietary models generally outperform the open-source ones, showing an average accuracy improvement of 22.70%; however, there is still potential for improvement. Moreover, our quantitative analysis shows that the choice of prompt strategy significantly affects the accuracy of LMMs, with variations ranging from -17.5% to +7.3%. Further case studies indicate that an appropriate visual referring prompting strategy can improve LMMs' understanding of context and location information, while an unsuitable one might lead to answer rejection. We also provide insights on minimizing the negative impact of visual referring prompting on LMMs.
DocStormer: Revitalizing Multi-Degraded Colored Document Images to Pristine PDF
Oct 27, 2023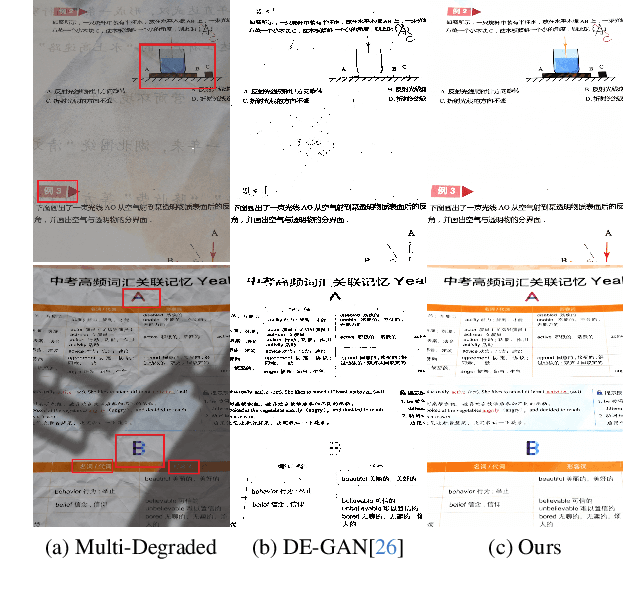


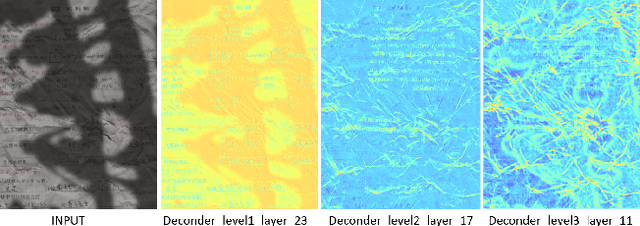
For capturing colored document images, e.g. posters and magazines, it is common that multiple degradations such as shadows, wrinkles, etc., are simultaneously introduced due to external factors. Restoring multi-degraded colored document images is a great challenge, yet overlooked, as most existing algorithms focus on enhancing color-ignored document images via binarization. Thus, we propose DocStormer, a novel algorithm designed to restore multi-degraded colored documents to their potential pristine PDF. The contributions are: firstly, we propose a "Perceive-then-Restore" paradigm with a reinforced transformer block, which more effectively encodes and utilizes the distribution of degradations. Secondly, we are the first to utilize GAN and pristine PDF magazine images to narrow the distribution gap between the enhanced results and PDF images, in pursuit of less degradation and better visual quality. Thirdly, we propose a non-parametric strategy, PFILI, which enables a smaller training scale and larger testing resolutions with acceptable detail trade-off, while saving memory and inference time. Fourthly, we are the first to propose a novel Multi-Degraded Colored Document image Enhancing dataset, named MD-CDE, for both training and evaluation. Experimental results show that the DocStormer exhibits superior performance, capable of revitalizing multi-degraded colored documents into their potential pristine digital versions, which fills the current academic gap from the perspective of method, data, and task.