 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Molecular Computer: Enabling Arithmetic Operations in Molecular Communication
Feb 27, 2025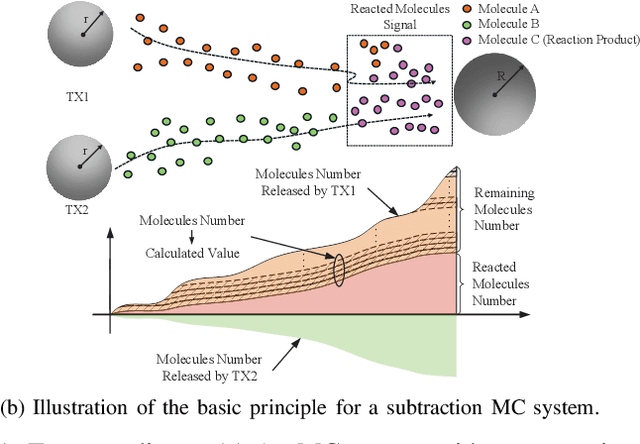
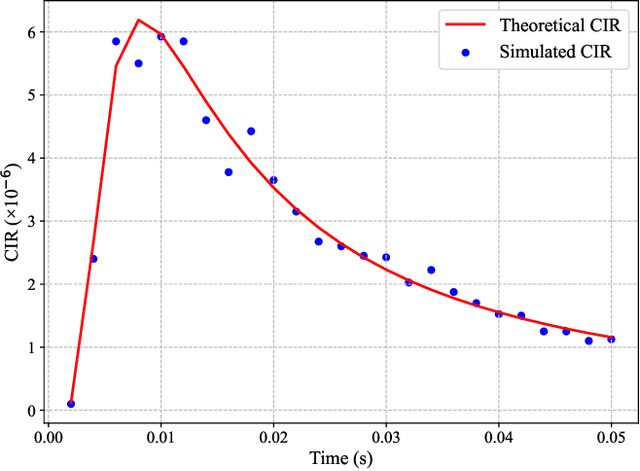
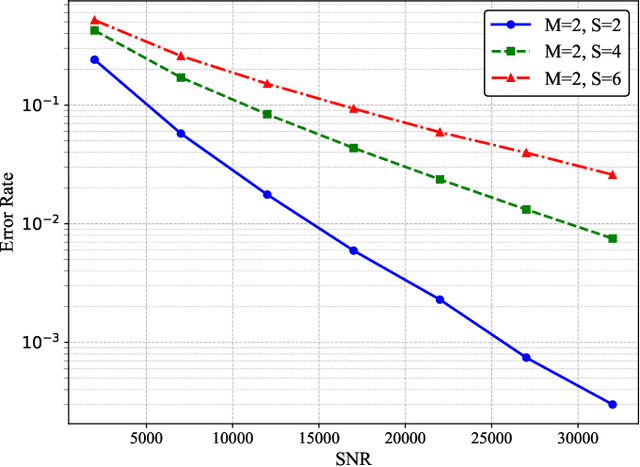
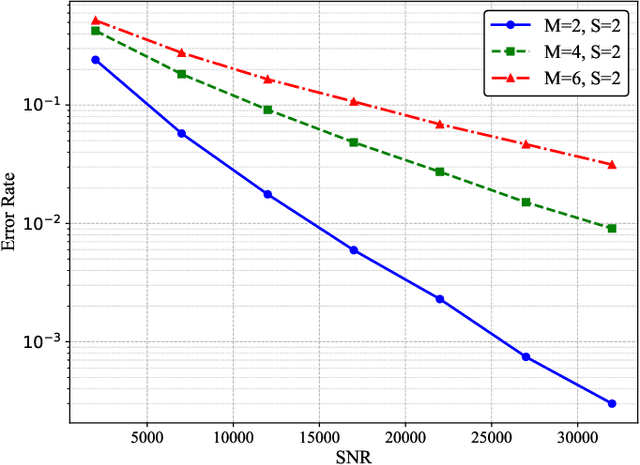
In current molecular communication (MC) systems, performing computational operations at the nanoscale remains challenging, restricting their applicability in complex scenarios such as adaptive biochemical control and advanced nanoscale sensing. To overcome this challenge, this paper proposes a novel framework that seamlessly integrates computation into the molecular communication process. The system enables arithmetic operations, namely addition, subtraction, multiplication, and division, by encoding numerical values into two types of molecules emitted by each transmitter to represent positive and negative values, respectively. Specifically, addition is achieved by transmitting non-reactive molecules, while subtraction employs reactive molecules that interact during propagation. The receiver demodulates molecular counts to directly compute the desired results. Theoretical analysis for an upper bound on the bit error rate (BER), and computational simulations confirm the system's robustness in performing complex arithmetic tasks. Compared to conventional MC methods, the proposed approach not only enables fundamental computational operations at the nanoscale but also lays the groundwork for intelligent, autonomous molecular networks.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
DocStormer: Revitalizing Multi-Degraded Colored Document Images to Pristine PDF
Oct 27, 2023For capturing colored document images, e.g. posters and magazines, it is common that multiple degradations such as shadows, wrinkles, etc., are simultaneously introduced due to external factors. Restoring multi-degraded colored document images is a great challenge, yet overlooked, as most existing algorithms focus on enhancing color-ignored document images via binarization. Thus, we propose DocStormer, a novel algorithm designed to restore multi-degraded colored documents to their potential pristine PDF. The contributions are: firstly, we propose a "Perceive-then-Restore" paradigm with a reinforced transformer block, which more effectively encodes and utilizes the distribution of degradations. Secondly, we are the first to utilize GAN and pristine PDF magazine images to narrow the distribution gap between the enhanced results and PDF images, in pursuit of less degradation and better visual quality. Thirdly, we propose a non-parametric strategy, PFILI, which enables a smaller training scale and larger testing resolutions with acceptable detail trade-off, while saving memory and inference time. Fourthly, we are the first to propose a novel Multi-Degraded Colored Document image Enhancing dataset, named MD-CDE, for both training and evaluation. Experimental results show that the DocStormer exhibits superior performance, capable of revitalizing multi-degraded colored documents into their potential pristine digital versions, which fills the current academic gap from the perspective of method, data, and task.