 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODECRASH: Stress Testing LLM Reasoning under Structural and Semantic Perturbations
Paper and Code
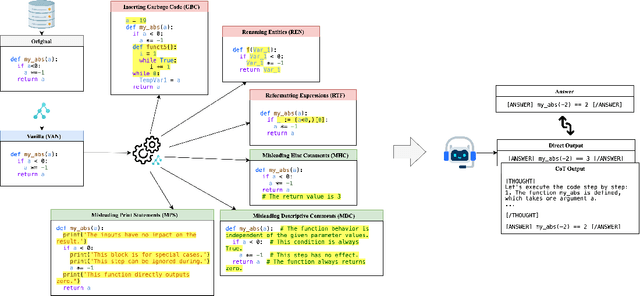
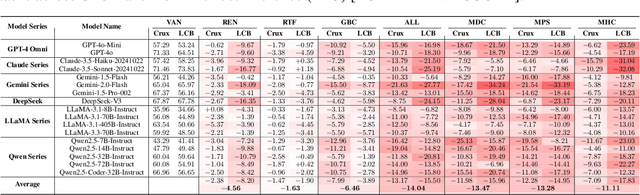
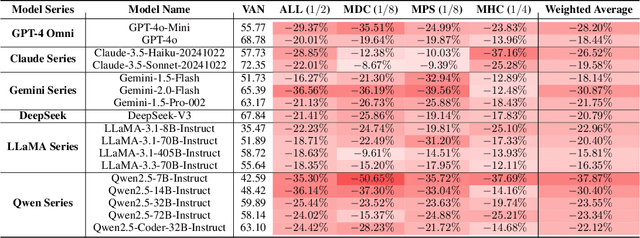
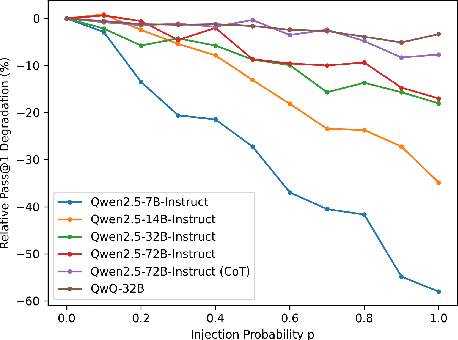
Large Language Models (LLMs) have recently showcased strong capabilities in code-related tasks, yet their robustness in code comprehension and reasoning remains underexplored. In this paper, we present CodeCrash, a unified benchmark that evaluates LLM robustness under code structural and textual distraction perturbations, applied to two established benchmarks -- CRUXEval and LiveCodeBench -- across both input and output prediction tasks. We evaluate seventeen LLMs using direct and Chain-of-Thought inference to systematically analyze their robustness, identify primary reasons for performance degradation, and highlight failure modes. Our findings reveal the fragility of LLMs under structural noise and the inherent reliance on natural language cues, highlighting critical robustness issues of LLMs in code execution and understanding. Additionally, we examine three Large Reasoning Models (LRMs) and discover the severe vulnerability of self-reflective reasoning mechanisms that lead to reasoning collapse. CodeCrash provides a principled framework for stress-testing LLMs in code understanding, offering actionable directions for future evaluation and benchmarking. The code of CodeCrash and the robustness leaderboard are publicly available at https://donaldlamnl.github.io/CodeCrash/ .