 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpertAD: Enhancing Autonomous Driving Systems with Mixture of Experts
Nov 13, 2025Recent advancements in end-to-end autonomous driving systems (ADSs) underscore their potential for perception and planning capabilities. However, challenges remain. Complex driving scenarios contain rich semantic information, yet ambiguous or noisy semantics can compromise decision reliability, while interference between multiple driving tasks may hinder optimal planning. Furthermore, prolonged inference latency slows decision-making, increasing the risk of unsafe driving behaviors. To address these challenges, we propose ExpertAD, a novel framework that enhances the performance of ADS with Mixture of Experts (MoE) architecture. We introduce a Perception Adapter (PA) to amplify task-critical features, ensuring contextually relevant scene understanding, and a Mixture of Sparse Experts (MoSE) to minimize task interference during prediction, allowing for effective and efficient planning. Our experiments show that ExpertAD reduces average collision rates by up to 20% and inference latency by 25% compared to prior methods. We further evaluate its multi-skill planning capabilities in rare scenarios (e.g., accidents, yielding to emergency vehicles) and demonstrate strong generalization to unseen urban environments. Additionally, we present a case study that illustrates its decision-making process in complex driving scenarios.
ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation
Aug 14, 2023



In this work, we make the first attempt to evaluate LLMs in a more challenging code generation scenario, i.e. class-level code generation. We first manually construct the first class-level code generation benchmark ClassEval of 100 class-level Python code generation tasks with approximately 500 person-hours. Based on it, we then perform the first study of 11 state-of-the-art LLMs on class-level code generation. Based on our results, we have the following main findings. First, we find that all existing LLMs show much worse performance on class-level code generation compared to on standalone method-level code generation benchmarks like HumanEval; and the method-level coding ability cannot equivalently reflect the class-level coding ability among LLMs. Second, we find that GPT-4 and GPT-3.5 still exhibit dominate superior than other LLMs on class-level code generation, and the second-tier models includes Instruct-Starcoder, Instruct-Codegen, and Wizardcoder with very similar performance. Third, we find that generating the entire class all at once (i.e. holistic generation strategy) is the best generation strategy only for GPT-4 and GPT-3.5, while method-by-method generation (i.e. incremental and compositional) is better strategies for the other models with limited ability of understanding long instructions and utilizing the middle information. Lastly, we find the limited model ability of generating method-dependent code and discuss the frequent error types in generated classes. Our benchmark is available at https://github.com/FudanSELab/ClassEval.
Reinforcement Learning Based Sparse Black-box Adversarial Attack on Video Recognition Models
Aug 29, 2021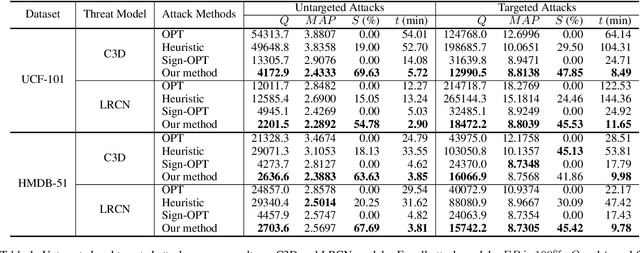

We explore the black-box adversarial attack on video recognition models. Attacks are only performed on selected key regions and key frames to reduce the high computation cost of searching adversarial perturbations on a video due to its high dimensionality. To select key frames, one way is to use heuristic algorithms to evaluate the importance of each frame and choose the essential ones. However, it is time inefficient on sorting and searching. In order to speed up the attack process, we propose a reinforcement learning based frame selection strategy. Specifically, the agent explores the difference between the original class and the target class of videos to make selection decisions. It receives rewards from threat models which indicate the quality of the decisions. Besides, we also use saliency detection to select key regions and only estimate the sign of gradient instead of the gradient itself in zeroth order optimization to further boost the attack process. We can use the trained model directly in the untargeted attack or with little fine-tune in the targeted attack, which saves computation time. A range of empirical results on real datasets demonstrate the effectiveness and efficiency of the proposed method.
* Accepted as a conference paper of IJCAI-21 (the 30th International Joint Conference on Artificial Intelligence)