 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing False Positives in Static Bug Detection with LLMs: An Empirical Study in Industry
Jan 26, 2026Static analysis tools (SATs) are widely adopted in both academia and industry for improving software quality, yet their practical use is often hindered by high false positive rates, especially in large-scale enterprise systems. These false alarms demand substantial manual inspection, creating severe inefficiencies in industrial code review. While recent work has demonstrated the potential of large language models (LLMs) for false alarm reduction on open-source benchmarks, their effectiveness in real-world enterprise settings remains unclear. To bridge this gap, we conduct the first comprehensive empirical study of diverse LLM-based false alarm reduction techniques in an industrial context at Tencent, one of the largest IT companies in China. Using data from Tencent's enterprise-customized SAT on its large-scale Advertising and Marketing Services software, we construct a dataset of 433 alarms (328 false positives, 105 true positives) covering three common bug types. Through interviewing developers and analyzing the data, our results highlight the prevalence of false positives, which wastes substantial manual effort (e.g., 10-20 minutes of manual inspection per alarm). Meanwhile, our results show the huge potential of LLMs for reducing false alarms in industrial settings (e.g., hybrid techniques of LLM and static analysis eliminate 94-98% of false positives with high recall). Furthermore, LLM-based techniques are cost-effective, with per-alarm costs as low as 2.1-109.5 seconds and $0.0011-$0.12, representing orders-of-magnitude savings compared to manual review. Finally, our case analysis further identifies key limitations of LLM-based false alarm reduction in industrial settings.
Code Copycat Conundrum: Demystifying Repetition in LLM-based Code Generation
Apr 17, 2025Despite recent advances in Large Language Models (LLMs) for code generation, the quality of LLM-generated code still faces significant challenges. One significant issue is code repetition, which refers to the model's tendency to generate structurally redundant code, resulting in inefficiencies and reduced readability. To address this, we conduct the first empirical study to investigate the prevalence and nature of repetition across 19 state-of-the-art code LLMs using three widely-used benchmarks. Our study includes both quantitative and qualitative analyses, revealing that repetition is pervasive and manifests at various granularities and extents, including character, statement, and block levels. We further summarize a taxonomy of 20 repetition patterns. Building on our findings, we propose DeRep, a rule-based technique designed to detect and mitigate repetition in generated code. We evaluate DeRep using both open-source benchmarks and in an industrial setting. Our results demonstrate that DeRep significantly outperforms baselines in reducing repetition (with an average improvements of 91.3%, 93.5%, and 79.9% in rep-3, rep-line, and sim-line metrics) and enhancing code quality (with a Pass@1 increase of 208.3% over greedy search). Furthermore, integrating DeRep improves the performance of existing repetition mitigation methods, with Pass@1 improvements ranging from 53.7% to 215.7%.
Vul-RAG: Enhancing LLM-based Vulnerability Detection via Knowledge-level RAG
Jun 17, 2024

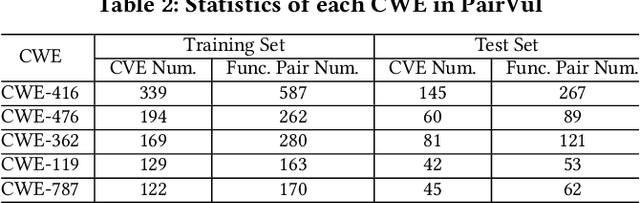
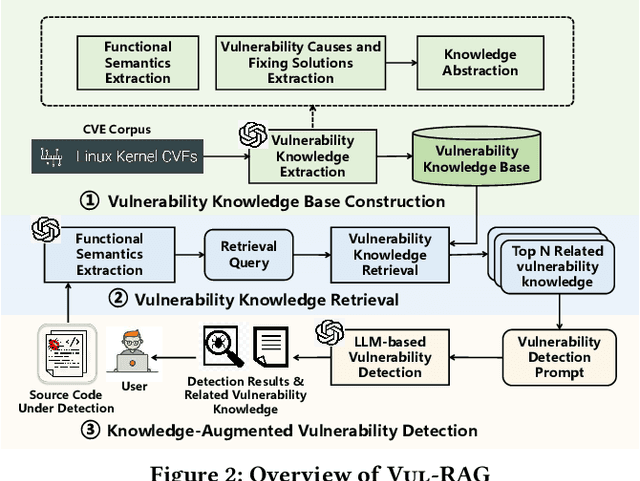
Vulnerability detection is essential for software quality assurance. In recent years, deep learning models (especially large language models) have shown promise in vulnerability detection. In this work, we propose a novel LLM-based vulnerability detection technique Vul-RAG, which leverages knowledge-level retrieval-augmented generation (RAG) framework to detect vulnerability for the given code in three phases. First, Vul-RAG constructs a vulnerability knowledge base by extracting multi-dimension knowledge via LLMs from existing CVE instances; second, for a given code snippet, Vul-RAG} retrieves the relevant vulnerability knowledge from the constructed knowledge base based on functional semantics; third, Vul-RAG leverages LLMs to check the vulnerability of the given code snippet by reasoning the presence of vulnerability causes and fixing solutions of the retrieved vulnerability knowledge. Our evaluation of Vul-RAG on our constructed benchmark PairVul shows that Vul-RAG substantially outperforms all baselines by 12.96\%/110\% relative improvement in accuracy/pairwise-accuracy. In addition, our user study shows that the vulnerability knowledge generated by Vul-RAG can serve as high-quality explanations which can improve the manual detection accuracy from 0.60 to 0.77.
Resolving Crash Bugs via Large Language Models: An Empirical Study
Dec 16, 2023Crash bugs cause unexpected program behaviors or even termination, requiring high-priority resolution. However, manually resolving crash bugs is challenging and labor-intensive, and researchers have proposed various techniques for their automated localization and repair. ChatGPT, a recent large language model (LLM), has garnered significant attention due to its exceptional performance across various domains. This work performs the first investigation into ChatGPT's capability in resolve real-world crash bugs, focusing on its effectiveness in both localizing and repairing code-related and environment-related crash bugs. Specifically, we initially assess ChatGPT's fundamental ability to resolve crash bugs with basic prompts in a single iteration. We observe that ChatGPT performs better at resolving code-related crash bugs compared to environment-related ones, and its primary challenge in resolution lies in inaccurate localization. Additionally, we explore ChatGPT's potential with various advanced prompts. Furthermore, by stimulating ChatGPT's self-planning, it methodically investigates each potential crash-causing environmental factor through proactive inquiry, ultimately identifying the root cause of the crash. Based on our findings, we propose IntDiagSolver, an interaction methodology designed to facilitate precise crash bug resolution through continuous interaction with LLMs. Evaluating IntDiagSolver on multiple LLMs reveals consistent enhancement in the accuracy of crash bug resolution, including ChatGPT, Claude, and CodeLlama.
ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation
Aug 14, 2023



In this work, we make the first attempt to evaluate LLMs in a more challenging code generation scenario, i.e. class-level code generation. We first manually construct the first class-level code generation benchmark ClassEval of 100 class-level Python code generation tasks with approximately 500 person-hours. Based on it, we then perform the first study of 11 state-of-the-art LLMs on class-level code generation. Based on our results, we have the following main findings. First, we find that all existing LLMs show much worse performance on class-level code generation compared to on standalone method-level code generation benchmarks like HumanEval; and the method-level coding ability cannot equivalently reflect the class-level coding ability among LLMs. Second, we find that GPT-4 and GPT-3.5 still exhibit dominate superior than other LLMs on class-level code generation, and the second-tier models includes Instruct-Starcoder, Instruct-Codegen, and Wizardcoder with very similar performance. Third, we find that generating the entire class all at once (i.e. holistic generation strategy) is the best generation strategy only for GPT-4 and GPT-3.5, while method-by-method generation (i.e. incremental and compositional) is better strategies for the other models with limited ability of understanding long instructions and utilizing the middle information. Lastly, we find the limited model ability of generating method-dependent code and discuss the frequent error types in generated classes. Our benchmark is available at https://github.com/FudanSELab/ClassEval.
Learning Diverse Policies in MOBA Games via Macro-Goals
Oct 27, 2021

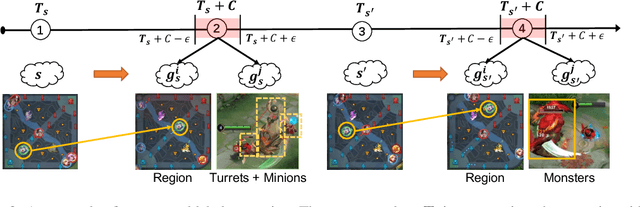
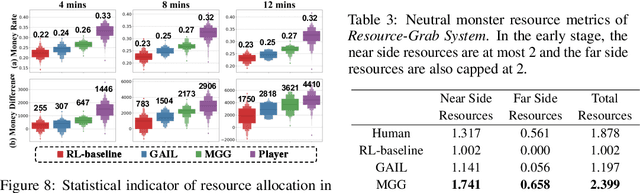
Recently, many researchers have made successful progress in building the AI systems for MOBA-game-playing with deep reinforcement learning, such as on Dota 2 and Honor of Kings. Even though these AI systems have achieved or even exceeded human-level performance, they still suffer from the lack of policy diversity. In this paper, we propose a novel Macro-Goals Guided framework, called MGG, to learn diverse policies in MOBA games. MGG abstracts strategies as macro-goals from human demonstrations and trains a Meta-Controller to predict these macro-goals. To enhance policy diversity, MGG samples macro-goals from the Meta-Controller prediction and guides the training process towards these goals. Experimental results on the typical MOBA game Honor of Kings demonstrate that MGG can execute diverse policies in different matches and lineups, and also outperform the state-of-the-art methods over 102 heroes.