 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing False Positives in Static Bug Detection with LLMs: An Empirical Study in Industry
Jan 26, 2026Static analysis tools (SATs) are widely adopted in both academia and industry for improving software quality, yet their practical use is often hindered by high false positive rates, especially in large-scale enterprise systems. These false alarms demand substantial manual inspection, creating severe inefficiencies in industrial code review. While recent work has demonstrated the potential of large language models (LLMs) for false alarm reduction on open-source benchmarks, their effectiveness in real-world enterprise settings remains unclear. To bridge this gap, we conduct the first comprehensive empirical study of diverse LLM-based false alarm reduction techniques in an industrial context at Tencent, one of the largest IT companies in China. Using data from Tencent's enterprise-customized SAT on its large-scale Advertising and Marketing Services software, we construct a dataset of 433 alarms (328 false positives, 105 true positives) covering three common bug types. Through interviewing developers and analyzing the data, our results highlight the prevalence of false positives, which wastes substantial manual effort (e.g., 10-20 minutes of manual inspection per alarm). Meanwhile, our results show the huge potential of LLMs for reducing false alarms in industrial settings (e.g., hybrid techniques of LLM and static analysis eliminate 94-98% of false positives with high recall). Furthermore, LLM-based techniques are cost-effective, with per-alarm costs as low as 2.1-109.5 seconds and $0.0011-$0.12, representing orders-of-magnitude savings compared to manual review. Finally, our case analysis further identifies key limitations of LLM-based false alarm reduction in industrial settings.
Vul-RAG: Enhancing LLM-based Vulnerability Detection via Knowledge-level RAG
Jun 17, 2024

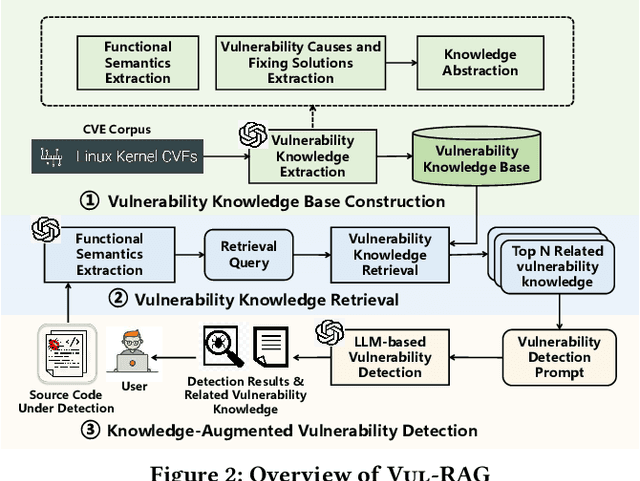
Vulnerability detection is essential for software quality assurance. In recent years, deep learning models (especially large language models) have shown promise in vulnerability detection. In this work, we propose a novel LLM-based vulnerability detection technique Vul-RAG, which leverages knowledge-level retrieval-augmented generation (RAG) framework to detect vulnerability for the given code in three phases. First, Vul-RAG constructs a vulnerability knowledge base by extracting multi-dimension knowledge via LLMs from existing CVE instances; second, for a given code snippet, Vul-RAG} retrieves the relevant vulnerability knowledge from the constructed knowledge base based on functional semantics; third, Vul-RAG leverages LLMs to check the vulnerability of the given code snippet by reasoning the presence of vulnerability causes and fixing solutions of the retrieved vulnerability knowledge. Our evaluation of Vul-RAG on our constructed benchmark PairVul shows that Vul-RAG substantially outperforms all baselines by 12.96\%/110\% relative improvement in accuracy/pairwise-accuracy. In addition, our user study shows that the vulnerability knowledge generated by Vul-RAG can serve as high-quality explanations which can improve the manual detection accuracy from 0.60 to 0.77.
ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation
Aug 14, 2023



In this work, we make the first attempt to evaluate LLMs in a more challenging code generation scenario, i.e. class-level code generation. We first manually construct the first class-level code generation benchmark ClassEval of 100 class-level Python code generation tasks with approximately 500 person-hours. Based on it, we then perform the first study of 11 state-of-the-art LLMs on class-level code generation. Based on our results, we have the following main findings. First, we find that all existing LLMs show much worse performance on class-level code generation compared to on standalone method-level code generation benchmarks like HumanEval; and the method-level coding ability cannot equivalently reflect the class-level coding ability among LLMs. Second, we find that GPT-4 and GPT-3.5 still exhibit dominate superior than other LLMs on class-level code generation, and the second-tier models includes Instruct-Starcoder, Instruct-Codegen, and Wizardcoder with very similar performance. Third, we find that generating the entire class all at once (i.e. holistic generation strategy) is the best generation strategy only for GPT-4 and GPT-3.5, while method-by-method generation (i.e. incremental and compositional) is better strategies for the other models with limited ability of understanding long instructions and utilizing the middle information. Lastly, we find the limited model ability of generating method-dependent code and discuss the frequent error types in generated classes. Our benchmark is available at https://github.com/FudanSELab/ClassEval.
On the Relations of Correlation Filter Based Trackers and Struck
Nov 25, 2017
In recent years, two types of trackers, namely correlation filter based tracker (CF tracker) and structured output tracker (Struck), have exhibited the state-of-the-art performance. However, there seems to be lack of analytic work on their relations in the computer vision community. In this paper, we investigate two state-of-the-art CF trackers, i.e., spatial regularization discriminative correlation filter (SRDCF) and correlation filter with limited boundaries (CFLB), and Struck, and reveal their relations. Specifically, after extending the CFLB to its multiple channel version we prove the relation between SRDCF and CFLB on the condition that the spatial regularization factor of SRDCF is replaced by the masking matrix of CFLB. We also prove the asymptotical approximate relation between SRDCF and Struck on the conditions that the spatial regularization factor of SRDCF is replaced by an indicator function of object bounding box, the weights of SRDCF in its loss item are replaced by those of Struck, the linear kernel is employed by Struck, and the search region tends to infinity. Extensive experiments on public benchmarks OTB50 and OTB100 are conducted to verify our theoretical results. Moreover, we explain how detailed differences among SRDCF, CFLB, and Struck would give rise to slightly different performances on visual sequences