 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Token to Line: Enhancing Code Generation with a Long-Term Perspective
Paper and Code
Apr 10, 2025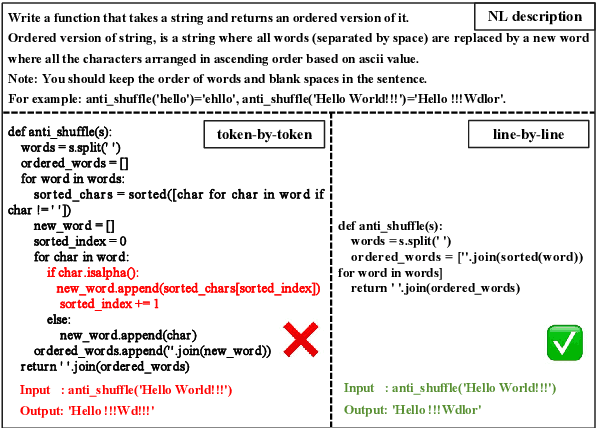
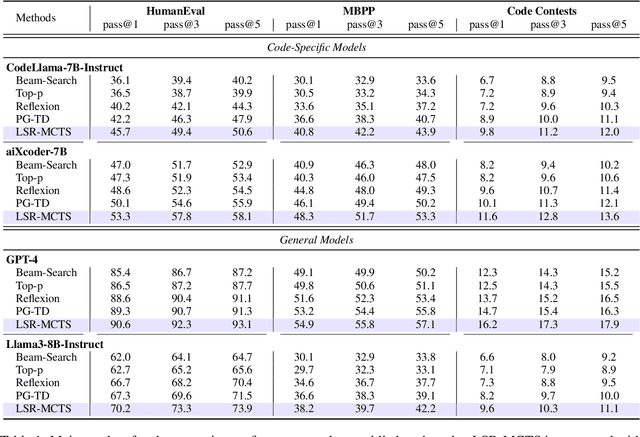
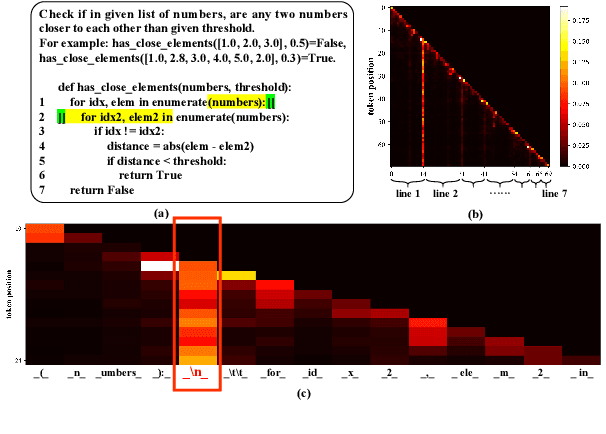
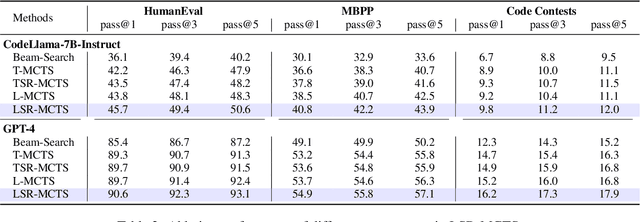
The emergence of large language models (LLMs) has significantly promoted the development of code generation task, sparking a surge in pertinent literature. Current research is hindered by redundant generation results and a tendency to overfit local patterns in the short term. Although existing studies attempt to alleviate the issue by adopting a multi-token prediction strategy, there remains limited focus on choosing the appropriate processing length for generations. By analyzing the attention between tokens during the generation process of LLMs, it can be observed that the high spikes of the attention scores typically appear at the end of lines. This insight suggests that it is reasonable to treat each line of code as a fundamental processing unit and generate them sequentially. Inspired by this, we propose the \textbf{LSR-MCTS} algorithm, which leverages MCTS to determine the code line-by-line and select the optimal path. Further, we integrate a self-refine mechanism at each node to enhance diversity and generate higher-quality programs through error correction. Extensive experiments and comprehensive analyses on three public coding benchmarks demonstrate that our method outperforms the state-of-the-art performance approaches.