 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Misalignment in Vision-Language Models under Perceptual Degradation
Jan 13, 2026Vision-Language Models (VLMs) are increasingly deployed in autonomous driving and embodied AI systems, where reliable perception is critical for safe semantic reasoning and decision-making. While recent VLMs demonstrate strong performance on multimodal benchmarks, their robustness to realistic perception degradation remains poorly understood. In this work, we systematically study semantic misalignment in VLMs under controlled degradation of upstream visual perception, using semantic segmentation on the Cityscapes dataset as a representative perception module. We introduce perception-realistic corruptions that induce only moderate drops in conventional segmentation metrics, yet observe severe failures in downstream VLM behavior, including hallucinated object mentions, omission of safety-critical entities, and inconsistent safety judgments. To quantify these effects, we propose a set of language-level misalignment metrics that capture hallucination, critical omission, and safety misinterpretation, and analyze their relationship with segmentation quality across multiple contrastive and generative VLMs. Our results reveal a clear disconnect between pixel-level robustness and multimodal semantic reliability, highlighting a critical limitation of current VLM-based systems and motivating the need for evaluation frameworks that explicitly account for perception uncertainty in safety-critical applications.
RealDPO: Real or Not Real, that is the Preference
Oct 16, 2025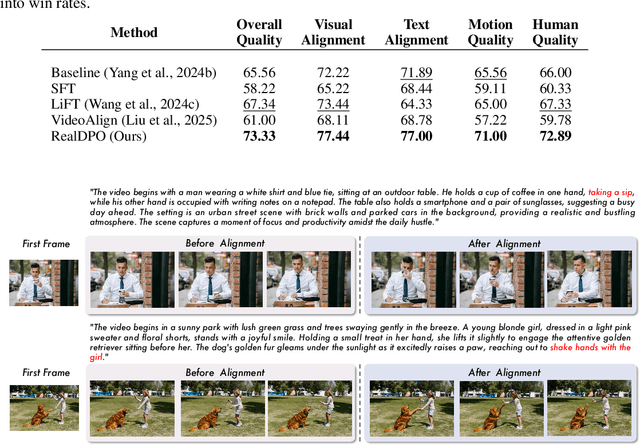

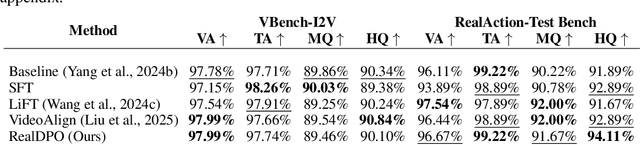
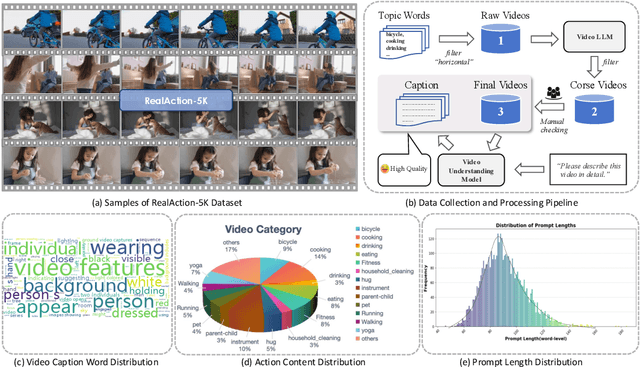
Video generative models have recently achieved notable advancements in synthesis quality. However, generating complex motions remains a critical challenge, as existing models often struggle to produce natural, smooth, and contextually consistent movements. This gap between generated and real-world motions limits their practical applicability. To address this issue, we introduce RealDPO, a novel alignment paradigm that leverages real-world data as positive samples for preference learning, enabling more accurate motion synthesis. Unlike traditional supervised fine-tuning (SFT), which offers limited corrective feedback, RealDPO employs Direct Preference Optimization (DPO) with a tailored loss function to enhance motion realism. By contrasting real-world videos with erroneous model outputs, RealDPO enables iterative self-correction, progressively refining motion quality. To support post-training in complex motion synthesis, we propose RealAction-5K, a curated dataset of high-quality videos capturing human daily activities with rich and precise motion details. Extensive experiments demonstrate that RealDPO significantly improves video quality, text alignment, and motion realism compared to state-of-the-art models and existing preference optimization techniques.
TASAM: Terrain-and-Aware Segment Anything Model for Temporal-Scale Remote Sensing Segmentation
Sep 19, 2025Segment Anything Model (SAM) has demonstrated impressive zero-shot segmentation capabilities across natural image domains, but it struggles to generalize to the unique challenges of remote sensing data, such as complex terrain, multi-scale objects, and temporal dynamics. In this paper, we introduce TASAM, a terrain and temporally-aware extension of SAM designed specifically for high-resolution remote sensing image segmentation. TASAM integrates three lightweight yet effective modules: a terrain-aware adapter that injects elevation priors, a temporal prompt generator that captures land-cover changes over time, and a multi-scale fusion strategy that enhances fine-grained object delineation. Without retraining the SAM backbone, our approach achieves substantial performance gains across three remote sensing benchmarks-LoveDA, iSAID, and WHU-CD-outperforming both zero-shot SAM and task-specific models with minimal computational overhead. Our results highlight the value of domain-adaptive augmentation for foundation models and offer a scalable path toward more robust geospatial segmentation.
Boosting Active Learning with Knowledge Transfer
Sep 19, 2025Uncertainty estimation is at the core of Active Learning (AL). Most existing methods resort to complex auxiliary models and advanced training fashions to estimate uncertainty for unlabeled data. These models need special design and hence are difficult to train especially for domain tasks, such as Cryo-Electron Tomography (cryo-ET) classification in computational biology. To address this challenge, we propose a novel method using knowledge transfer to boost uncertainty estimation in AL. Specifically, we exploit the teacher-student mode where the teacher is the task model in AL and the student is an auxiliary model that learns from the teacher. We train the two models simultaneously in each AL cycle and adopt a certain distance between the model outputs to measure uncertainty for unlabeled data. The student model is task-agnostic and does not rely on special training fashions (e.g. adversarial), making our method suitable for various tasks. More importantly, we demonstrate that data uncertainty is not tied to concrete value of task loss but closely related to the upper-bound of task loss. We conduct extensive experiments to validate the proposed method on classical computer vision tasks and cryo-ET challenges. The results demonstrate its efficacy and efficiency.
AsyMoE: Leveraging Modal Asymmetry for Enhanced Expert Specialization in Large Vision-Language Models
Sep 16, 2025Large Vision-Language Models (LVLMs) have demonstrated impressive performance on multimodal tasks through scaled architectures and extensive training. However, existing Mixture of Experts (MoE) approaches face challenges due to the asymmetry between visual and linguistic processing. Visual information is spatially complete, while language requires maintaining sequential context. As a result, MoE models struggle to balance modality-specific features and cross-modal interactions. Through systematic analysis, we observe that language experts in deeper layers progressively lose contextual grounding and rely more on parametric knowledge rather than utilizing the provided visual and linguistic information. To address this, we propose AsyMoE, a novel architecture that models this asymmetry using three specialized expert groups. We design intra-modality experts for modality-specific processing, hyperbolic inter-modality experts for hierarchical cross-modal interactions, and evidence-priority language experts to suppress parametric biases and maintain contextual grounding. Extensive experiments demonstrate that AsyMoE achieves 26.58% and 15.45% accuracy improvements over vanilla MoE and modality-specific MoE respectively, with 25.45% fewer activated parameters than dense models.
EXCGEC: A Benchmark of Edit-wise Explainable Chinese Grammatical Error Correction
Jul 01, 2024



Existing studies explore the explainability of Grammatical Error Correction (GEC) in a limited scenario, where they ignore the interaction between corrections and explanations. To bridge the gap, this paper introduces the task of EXplainable GEC (EXGEC), which focuses on the integral role of both correction and explanation tasks. To facilitate the task, we propose EXCGEC, a tailored benchmark for Chinese EXGEC consisting of 8,216 explanation-augmented samples featuring the design of hybrid edit-wise explanations. We benchmark several series of LLMs in multiple settings, covering post-explaining and pre-explaining. To promote the development of the task, we introduce a comprehensive suite of automatic metrics and conduct human evaluation experiments to demonstrate the human consistency of the automatic metrics for free-text explanations. All the codes and data will be released after the review.
Shift-Memory Network for Temporal Scene Segmentation
Feb 17, 2022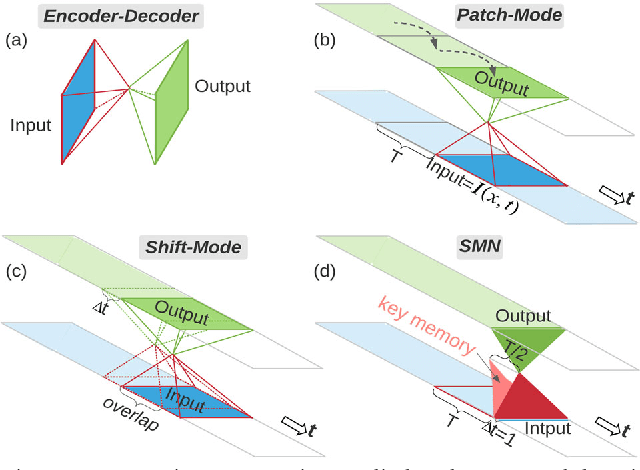

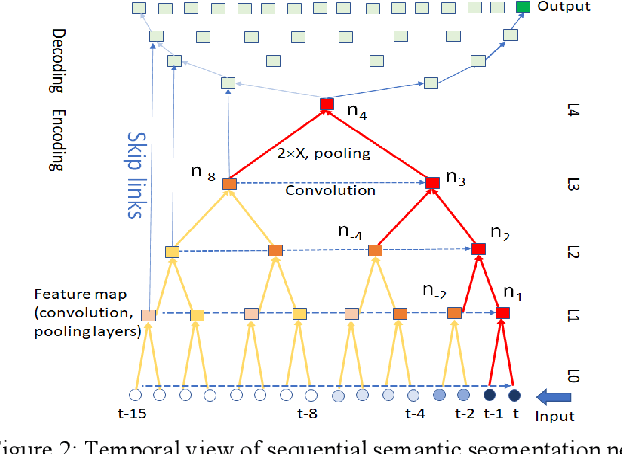
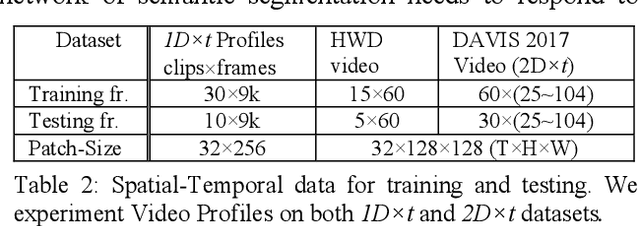
Semantic segmentation has achieved great accuracy in understanding spatial layout. For real-time tasks based on dynamic scenes, we extend semantic segmentation in temporal domain to enhance the spatial accuracy with motion. We utilize a shift-mode network over streaming input to ensure zero-latency output. For the data overlap under shifting network, this paper identifies repeated computation in fixed periods across network layers. To avoid this redundancy, we derive a Shift-Memory Network (SMN) from encoding-decoding baseline to reuse the network values without accuracy loss. Trained in patch-mode, the SMN extracts the network parameters for SMN to perform inference promptly in compact memory. We segment dynamic scenes from 1D scanning input and 2D video. The experiments of SMN achieve equivalent accuracy as shift-mode but in faster inference speeds and much smaller memory. This will facilitate semantic segmentation in real-time application on edge devices.