 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARC-Chapter: Structuring Hour-Long Videos into Navigable Chapters and Hierarchical Summaries
Nov 18, 2025
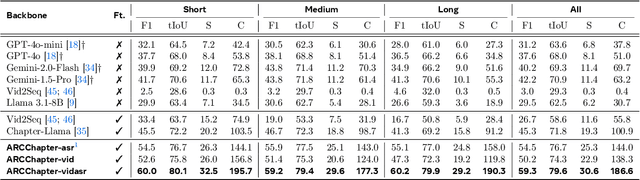
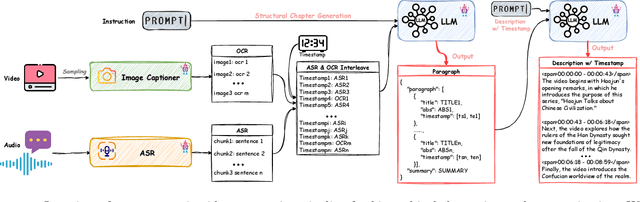
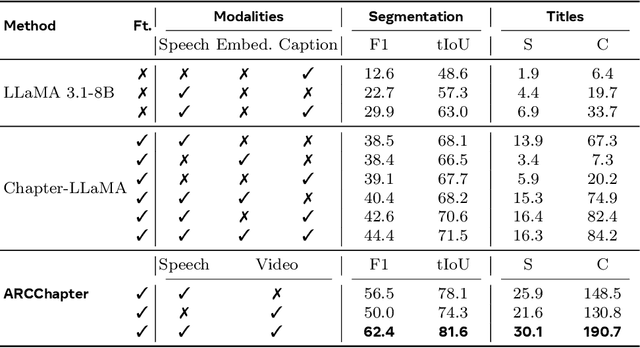
The proliferation of hour-long videos (e.g., lectures, podcasts, documentaries) has intensified demand for efficient content structuring. However, existing approaches are constrained by small-scale training with annotations that are typical short and coarse, restricting generalization to nuanced transitions in long videos. We introduce ARC-Chapter, the first large-scale video chaptering model trained on over million-level long video chapters, featuring bilingual, temporally grounded, and hierarchical chapter annotations. To achieve this goal, we curated a bilingual English-Chinese chapter dataset via a structured pipeline that unifies ASR transcripts, scene texts, visual captions into multi-level annotations, from short title to long summaries. We demonstrate clear performance improvements with data scaling, both in data volume and label intensity. Moreover, we design a new evaluation metric termed GRACE, which incorporates many-to-one segment overlaps and semantic similarity, better reflecting real-world chaptering flexibility. Extensive experiments demonstrate that ARC-Chapter establishes a new state-of-the-art by a significant margin, outperforming the previous best by 14.0% in F1 score and 11.3% in SODA score. Moreover, ARC-Chapter shows excellent transferability, improving the state-of-the-art on downstream tasks like dense video captioning on YouCook2.
ARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
Jul 28, 2025Real-world user-generated short videos, especially those distributed on platforms such as WeChat Channel and TikTok, dominate the mobile internet. However, current large multimodal models lack essential temporally-structured, detailed, and in-depth video comprehension capabilities, which are the cornerstone of effective video search and recommendation, as well as emerging video applications. Understanding real-world shorts is actually challenging due to their complex visual elements, high information density in both visuals and audio, and fast pacing that focuses on emotional expression and viewpoint delivery. This requires advanced reasoning to effectively integrate multimodal information, including visual, audio, and text. In this work, we introduce ARC-Hunyuan-Video, a multimodal model that processes visual, audio, and textual signals from raw video inputs end-to-end for structured comprehension. The model is capable of multi-granularity timestamped video captioning and summarization, open-ended video question answering, temporal video grounding, and video reasoning. Leveraging high-quality data from an automated annotation pipeline, our compact 7B-parameter model is trained through a comprehensive regimen: pre-training, instruction fine-tuning, cold start, reinforcement learning (RL) post-training, and final instruction fine-tuning. Quantitative evaluations on our introduced benchmark ShortVid-Bench and qualitative comparisons demonstrate its strong performance in real-world video comprehension, and it supports zero-shot or fine-tuning with a few samples for diverse downstream applications. The real-world production deployment of our model has yielded tangible and measurable improvements in user engagement and satisfaction, a success supported by its remarkable efficiency, with stress tests indicating an inference time of just 10 seconds for a one-minute video on H20 GPU.
VideoMaker: Zero-shot Customized Video Generation with the Inherent Force of Video Diffusion Models
Dec 27, 2024


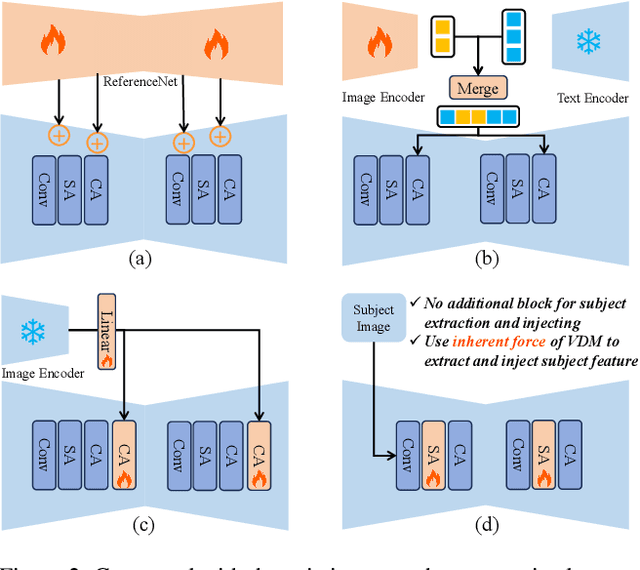
Zero-shot customized video generation has gained significant attention due to its substantial application potential. Existing methods rely on additional models to extract and inject reference subject features, assuming that the Video Diffusion Model (VDM) alone is insufficient for zero-shot customized video generation. However, these methods often struggle to maintain consistent subject appearance due to suboptimal feature extraction and injection techniques. In this paper, we reveal that VDM inherently possesses the force to extract and inject subject features. Departing from previous heuristic approaches, we introduce a novel framework that leverages VDM's inherent force to enable high-quality zero-shot customized video generation. Specifically, for feature extraction, we directly input reference images into VDM and use its intrinsic feature extraction process, which not only provides fine-grained features but also significantly aligns with VDM's pre-trained knowledge. For feature injection, we devise an innovative bidirectional interaction between subject features and generated content through spatial self-attention within VDM, ensuring that VDM has better subject fidelity while maintaining the diversity of the generated video.Experiments on both customized human and object video generation validate the effectiveness of our framework.
Verb Mirage: Unveiling and Assessing Verb Concept Hallucinations in Multimodal Large Language Models
Dec 06, 2024



Multimodal Large Language Models (MLLMs) have garnered significant attention recently and demonstrate outstanding capabilities in various tasks such as OCR, VQA, captioning, $\textit{etc}$. However, hallucination remains a persistent issue. While numerous methods have been proposed to mitigate hallucinations, achieving notable improvements, these methods primarily focus on mitigating hallucinations about $\textbf{object/noun-related}$ concepts. Verb concepts, crucial for understanding human actions, have been largely overlooked. In this paper, to the best of our knowledge, we are the $\textbf{first}$ to investigate the $\textbf{verb hallucination}$ phenomenon of MLLMs from various perspectives. Our findings reveal that most state-of-the-art MLLMs suffer from severe verb hallucination. To assess the effectiveness of existing mitigation methods for object concept hallucination on verb hallucination, we evaluated these methods and found that they do not effectively address verb hallucination. To address this issue, we propose a novel rich verb knowledge-based tuning method to mitigate verb hallucination. The experiment results demonstrate that our method significantly reduces hallucinations related to verbs. $\textit{Our code and data will be made publicly available}$.
mR$^2$AG: Multimodal Retrieval-Reflection-Augmented Generation for Knowledge-Based VQA
Nov 22, 2024



Advanced Multimodal Large Language Models (MLLMs) struggle with recent Knowledge-based VQA tasks, such as INFOSEEK and Encyclopedic-VQA, due to their limited and frozen knowledge scope, often leading to ambiguous and inaccurate responses. Thus, multimodal Retrieval-Augmented Generation (mRAG) is naturally introduced to provide MLLMs with comprehensive and up-to-date knowledge, effectively expanding the knowledge scope. However, current mRAG methods have inherent drawbacks, including: 1) Performing retrieval even when external knowledge is not needed. 2) Lacking of identification of evidence that supports the query. 3) Increasing model complexity due to additional information filtering modules or rules. To address these shortcomings, we propose a novel generalized framework called \textbf{m}ultimodal \textbf{R}etrieval-\textbf{R}eflection-\textbf{A}ugmented \textbf{G}eneration (mR$^2$AG), which achieves adaptive retrieval and useful information localization to enable answers through two easy-to-implement reflection operations, preventing high model complexity. In mR$^2$AG, Retrieval-Reflection is designed to distinguish different user queries and avoids redundant retrieval calls, and Relevance-Reflection is introduced to guide the MLLM in locating beneficial evidence of the retrieved content and generating answers accordingly. In addition, mR$^2$AG can be integrated into any well-trained MLLM with efficient fine-tuning on the proposed mR$^2$AG Instruction-Tuning dataset (mR$^2$AG-IT). mR$^2$AG significantly outperforms state-of-the-art MLLMs (e.g., GPT-4v/o) and RAG-based MLLMs on INFOSEEK and Encyclopedic-VQA, while maintaining the exceptional capabilities of base MLLMs across a wide range of Visual-dependent tasks.
Taming Rectified Flow for Inversion and Editing
Nov 07, 2024



Rectified-flow-based diffusion transformers, such as FLUX and OpenSora, have demonstrated exceptional performance in the field of image and video generation. Despite their robust generative capabilities, these models often suffer from inaccurate inversion, which could further limit their effectiveness in downstream tasks such as image and video editing. To address this issue, we propose RF-Solver, a novel training-free sampler that enhances inversion precision by reducing errors in the process of solving rectified flow ODEs. Specifically, we derive the exact formulation of the rectified flow ODE and perform a high-order Taylor expansion to estimate its nonlinear components, significantly decreasing the approximation error at each timestep. Building upon RF-Solver, we further design RF-Edit, which comprises specialized sub-modules for image and video editing. By sharing self-attention layer features during the editing process, RF-Edit effectively preserves the structural information of the source image or video while achieving high-quality editing results. Our approach is compatible with any pre-trained rectified-flow-based models for image and video tasks, requiring no additional training or optimization. Extensive experiments on text-to-image generation, image & video inversion, and image & video editing demonstrate the robust performance and adaptability of our methods. Code is available at https://github.com/wangjiangshan0725/RF-Solver-Edit.
SynopGround: A Large-Scale Dataset for Multi-Paragraph Video Grounding from TV Dramas and Synopses
Aug 07, 2024
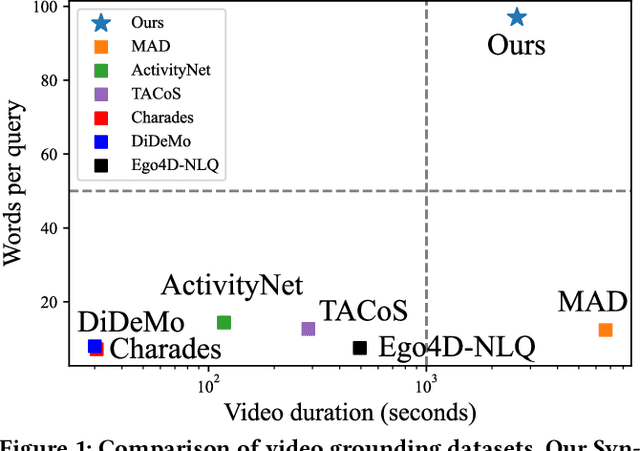
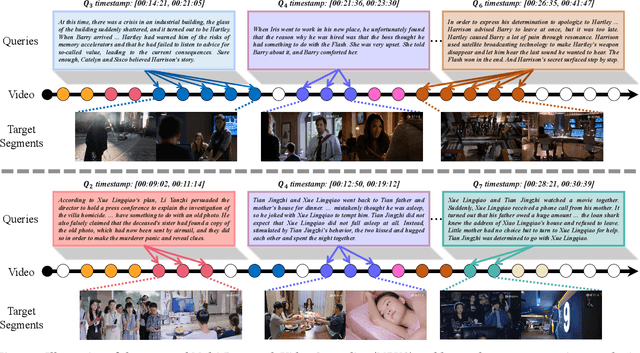
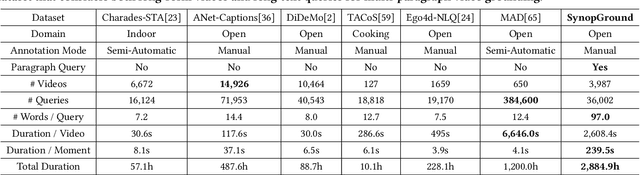
Video grounding is a fundamental problem in multimodal content understanding, aiming to localize specific natural language queries in an untrimmed video. However, current video grounding datasets merely focus on simple events and are either limited to shorter videos or brief sentences, which hinders the model from evolving toward stronger multimodal understanding capabilities. To address these limitations, we present a large-scale video grounding dataset named SynopGround, in which more than 2800 hours of videos are sourced from popular TV dramas and are paired with accurately localized human-written synopses. Each paragraph in the synopsis serves as a language query and is manually annotated with precise temporal boundaries in the long video. These paragraph queries are tightly correlated to each other and contain a wealth of abstract expressions summarizing video storylines and specific descriptions portraying event details, which enables the model to learn multimodal perception on more intricate concepts over longer context dependencies. Based on the dataset, we further introduce a more complex setting of video grounding dubbed Multi-Paragraph Video Grounding (MPVG), which takes as input multiple paragraphs and a long video for grounding each paragraph query to its temporal interval. In addition, we propose a novel Local-Global Multimodal Reasoner (LGMR) to explicitly model the local-global structures of long-term multimodal inputs for MPVG. Our method provides an effective baseline solution to the multi-paragraph video grounding problem. Extensive experiments verify the proposed model's effectiveness as well as its superiority in long-term multi-paragraph video grounding over prior state-of-the-arts. Dataset and code are publicly available. Project page: https://synopground.github.io/.
How to Make Cross Encoder a Good Teacher for Efficient Image-Text Retrieval?
Jul 10, 2024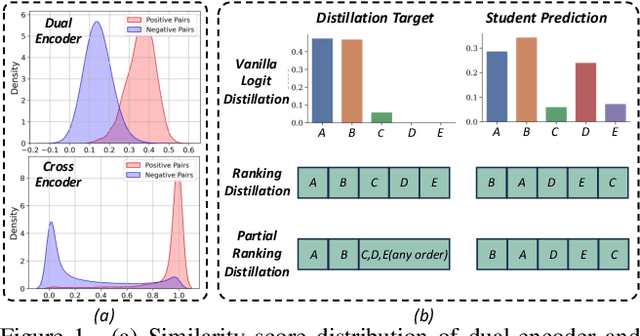
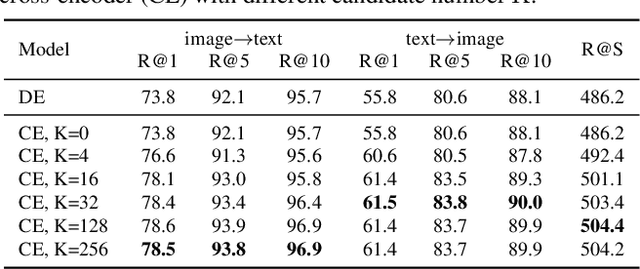
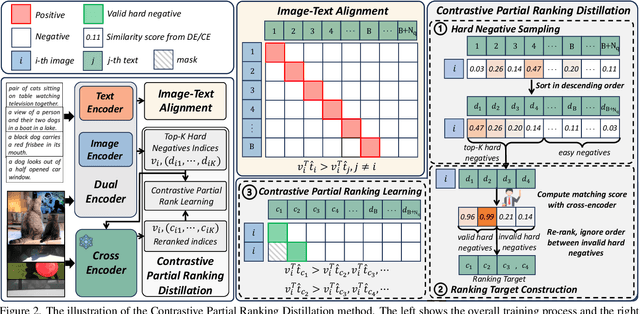
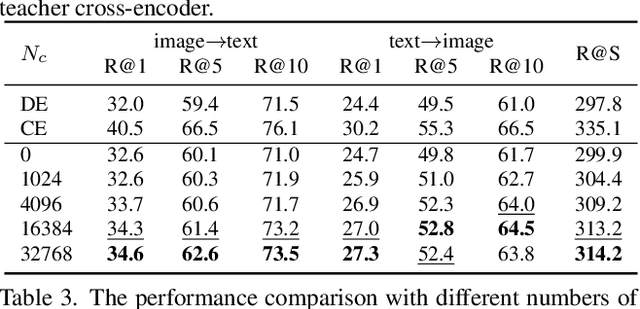
Dominant dual-encoder models enable efficient image-text retrieval but suffer from limited accuracy while the cross-encoder models offer higher accuracy at the expense of efficiency. Distilling cross-modality matching knowledge from cross-encoder to dual-encoder provides a natural approach to harness their strengths. Thus we investigate the following valuable question: how to make cross-encoder a good teacher for dual-encoder? Our findings are threefold:(1) Cross-modal similarity score distribution of cross-encoder is more concentrated while the result of dual-encoder is nearly normal making vanilla logit distillation less effective. However ranking distillation remains practical as it is not affected by the score distribution.(2) Only the relative order between hard negatives conveys valid knowledge while the order information between easy negatives has little significance.(3) Maintaining the coordination between distillation loss and dual-encoder training loss is beneficial for knowledge transfer. Based on these findings we propose a novel Contrastive Partial Ranking Distillation (CPRD) method which implements the objective of mimicking relative order between hard negative samples with contrastive learning. This approach coordinates with the training of the dual-encoder effectively transferring valid knowledge from the cross-encoder to the dual-encoder. Extensive experiments on image-text retrieval and ranking tasks show that our method surpasses other distillation methods and significantly improves the accuracy of dual-encoder.
Music-driven Dance Regeneration with Controllable Key Pose Constraints
Jul 08, 2022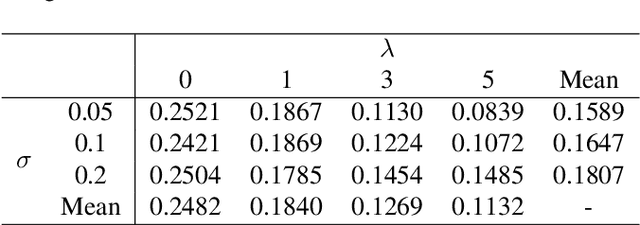
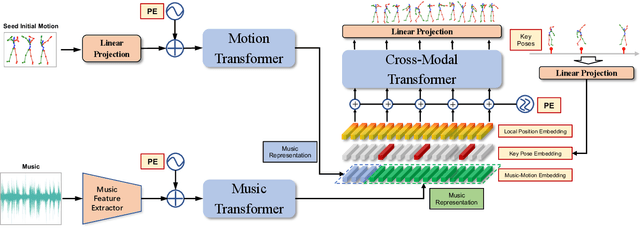
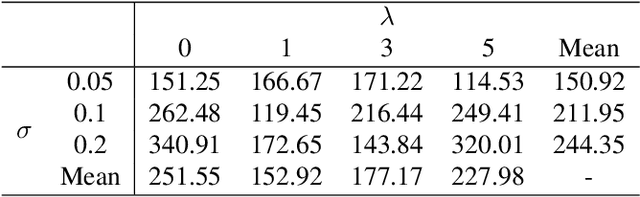
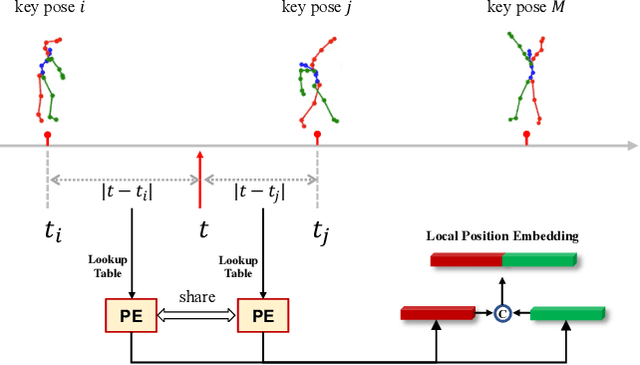
In this paper, we propose a novel framework for music-driven dance motion synthesis with controllable key pose constraint. In contrast to methods that generate dance motion sequences only based on music without any other controllable conditions, this work targets on synthesizing high-quality dance motion driven by music as well as customized poses performed by users. Our model involves two single-modal transformer encoders for music and motion representations and a cross-modal transformer decoder for dance motions generation. The cross-modal transformer decoder achieves the capability of synthesizing smooth dance motion sequences, which keeps a consistency with key poses at corresponding positions, by introducing the local neighbor position embedding. Such mechanism makes the decoder more sensitive to key poses and the corresponding positions. Our dance synthesis model achieves satisfactory performance both on quantitative and qualitative evaluations with extensive experiments, which demonstrates the effectiveness of our proposed method.
Self-Supervised Learning of Music-Dance Representation through Explicit-Implicit Rhythm Synchronization
Jul 07, 2022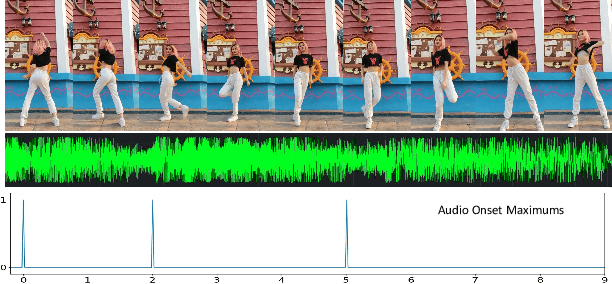
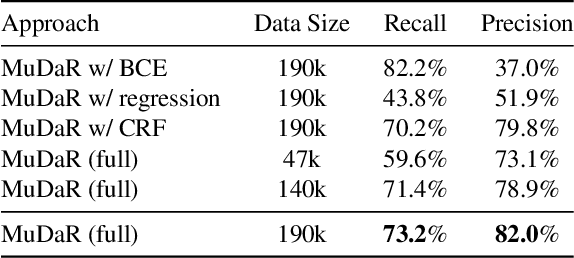
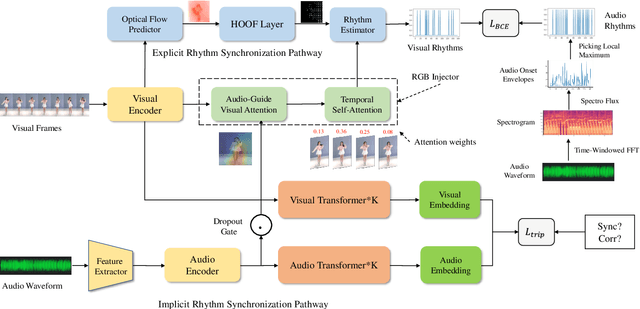
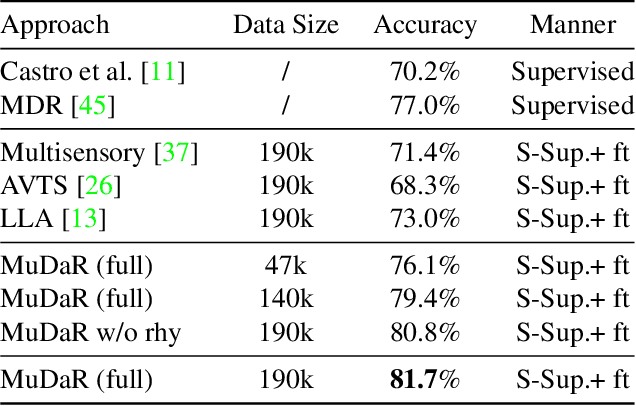
Although audio-visual representation has been proved to be applicable in many downstream tasks, the representation of dancing videos, which is more specific and always accompanied by music with complex auditory contents, remains challenging and uninvestigated. Considering the intrinsic alignment between the cadent movement of dancer and music rhythm, we introduce MuDaR, a novel Music-Dance Representation learning framework to perform the synchronization of music and dance rhythms both in explicit and implicit ways. Specifically, we derive the dance rhythms based on visual appearance and motion cues inspired by the music rhythm analysis. Then the visual rhythms are temporally aligned with the music counterparts, which are extracted by the amplitude of sound intensity. Meanwhile, we exploit the implicit coherence of rhythms implied in audio and visual streams by contrastive learning. The model learns the joint embedding by predicting the temporal consistency between audio-visual pairs. The music-dance representation, together with the capability of detecting audio and visual rhythms, can further be applied to three downstream tasks: (a) dance classification, (b) music-dance retrieval, and (c) music-dance retargeting. Extensive experiments demonstrate that our proposed framework outperforms other self-supervised methods by a large margin.