 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Sign Language Translation with Monolingual Data by Sign Back-Translation
Paper and Code
May 26, 2021
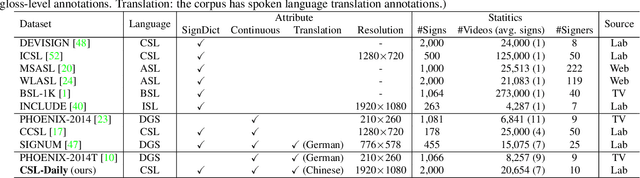
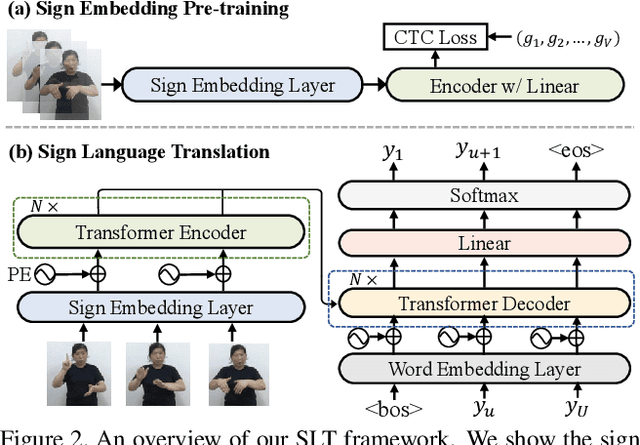
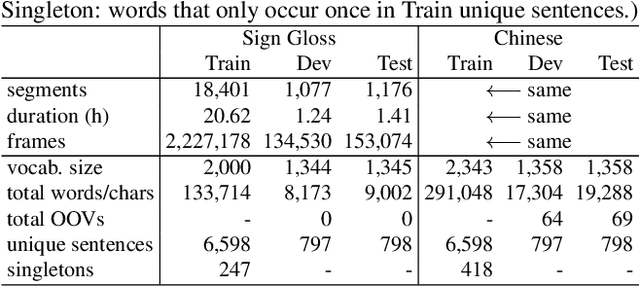
Despite existing pioneering works on sign language translation (SLT), there is a non-trivial obstacle, i.e., the limited quantity of parallel sign-text data. To tackle this parallel data bottleneck, we propose a sign back-translation (SignBT) approach, which incorporates massive spoken language texts into SLT training. With a text-to-gloss translation model, we first back-translate the monolingual text to its gloss sequence. Then, the paired sign sequence is generated by splicing pieces from an estimated gloss-to-sign bank at the feature level. Finally, the synthetic parallel data serves as a strong supplement for the end-to-end training of the encoder-decoder SLT framework. To promote the SLT research, we further contribute CSL-Daily, a large-scale continuous SLT dataset. It provides both spoken language translations and gloss-level annotations. The topic revolves around people's daily lives (e.g., travel, shopping, medical care), the most likely SLT application scenario. Extensive experimental results and analysis of SLT methods are reported on CSL-Daily. With the proposed sign back-translation method, we obtain a substantial improvement over previous state-of-the-art SLT methods.