 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni IIE Bench: Benchmarking the Practical Capabilities of Image Editing Models
Mar 16, 2026While Instruction-based Image Editing (IIE) has achieved significant progress, existing benchmarks pursue task breadth via mixed evaluations. This paradigm obscures a critical failure mode crucial in professional applications: the inconsistent performance of models across tasks of varying semantic scales. To address this gap, we introduce Omni IIE Bench, a high-quality, human-annotated benchmark specifically designed to diagnose the editing consistency of IIE models in practical application scenarios. Omni IIE Bench features an innovative dual-track diagnostic design: (1) Single-turn Consistency, comprising shared-context task pairs of attribute modification and entity replacement; and (2) Multi-turn Coordination, involving continuous dialogue tasks that traverse semantic scales. The benchmark is constructed via an exceptionally rigorous multi-stage human filtering process, incorporating a quality standard enforced by computer vision graduate students and an industry relevance review conducted by professional designers. We perform a comprehensive evaluation of 8 mainstream IIE models using Omni IIE Bench. Our analysis quantifies, for the first time, a prevalent performance gap: nearly all models exhibit a significant performance degradation when transitioning from low-semantic-scale to high-semantic-scale tasks. Omni IIE Bench provides critical diagnostic tools and insights for the development of next-generation, more reliable, and stable IIE models.
Beyond Closed-Pool Video Retrieval: A Benchmark and Agent Framework for Real-World Video Search and Moment Localization
Feb 10, 2026Traditional video retrieval benchmarks focus on matching precise descriptions to closed video pools, failing to reflect real-world searches characterized by fuzzy, multi-dimensional memories on the open web. We present \textbf{RVMS-Bench}, a comprehensive system for evaluating real-world video memory search. It consists of \textbf{1,440 samples} spanning \textbf{20 diverse categories} and \textbf{four duration groups}, sourced from \textbf{real-world open-web videos}. RVMS-Bench utilizes a hierarchical description framework encompassing \textbf{Global Impression, Key Moment, Temporal Context, and Auditory Memory} to mimic realistic multi-dimensional search cues, with all samples strictly verified via a human-in-the-loop protocol. We further propose \textbf{RACLO}, an agentic framework that employs abductive reasoning to simulate the human ``Recall-Search-Verify'' cognitive process, effectively addressing the challenge of searching for videos via fuzzy memories in the real world. Experiments reveal that existing MLLMs still demonstrate insufficient capabilities in real-world Video Retrieval and Moment Localization based on fuzzy memories. We believe this work will facilitate the advancement of video retrieval robustness in real-world unstructured scenarios.
VDE Bench: Evaluating The Capability of Image Editing Models to Modify Visual Documents
Jan 27, 2026In recent years, multimodal image editing models have achieved substantial progress, enabling users to manipulate visual content through natural language in a flexible and interactive manner. Nevertheless, an important yet insufficiently explored research direction remains visual document image editing, which involves modifying textual content within images while faithfully preserving the original text style and background context. Existing approaches, including AnyText, GlyphControl, and TextCtrl, predominantly focus on English-language scenarios and documents with relatively sparse textual layouts, thereby failing to adequately address dense, structurally complex documents or non-Latin scripts such as Chinese. To bridge this gap, we propose \textbf{V}isual \textbf{D}oc \textbf{E}dit Bench(VDE Bench), a rigorously human-annotated and evaluated benchmark specifically designed to assess image editing models on multilingual and complex visual document editing tasks. The benchmark comprises a high-quality dataset encompassing densely textual documents in both English and Chinese, including academic papers, posters, presentation slides, examination materials, and newspapers. Furthermore, we introduce a decoupled evaluation framework that systematically quantifies editing performance at the OCR parsing level, enabling fine-grained assessment of text modification accuracy. Based on this benchmark, we conduct a comprehensive evaluation of representative state-of-the-art image editing models. Manual verification demonstrates a strong consistency between human judgments and automated evaluation metrics. VDE Bench constitutes the first systematic benchmark for evaluating image editing models on multilingual and densely textual visual documents.
Rank4Gen: RAG-Preference-Aligned Document Set Selection and Ranking
Jan 16, 2026In the RAG paradigm, the information retrieval module provides context for generators by retrieving and ranking multiple documents to support the aggregation of evidence. However, existing ranking models are primarily optimized for query--document relevance, which often misaligns with generators' preferences for evidence selection and citation, limiting their impact on response quality. Moreover, most approaches do not account for preference differences across generators, resulting in unstable cross-generator performance. We propose \textbf{Rank4Gen}, a generator-aware ranker for RAG that targets the goal of \emph{Ranking for Generators}. Rank4Gen introduces two key preference modeling strategies: (1) \textbf{From Ranking Relevance to Response Quality}, which optimizes ranking with respect to downstream response quality rather than query--document relevance; and (2) \textbf{Generator-Specific Preference Modeling}, which conditions a single ranker on different generators to capture their distinct ranking preferences. To enable such modeling, we construct \textbf{PRISM}, a dataset built from multiple open-source corpora and diverse downstream generators. Experiments on five challenging and recent RAG benchmarks demonstrate that RRank4Gen achieves strong and competitive performance for complex evidence composition in RAG.
Best Practices for Distilling Large Language Models into BERT for Web Search Ranking
Nov 07, 2024Recent studies have highlighted the significant potential of Large Language Models (LLMs) as zero-shot relevance rankers. These methods predominantly utilize prompt learning to assess the relevance between queries and documents by generating a ranked list of potential documents. Despite their promise, the substantial costs associated with LLMs pose a significant challenge for their direct implementation in commercial search systems. To overcome this barrier and fully exploit the capabilities of LLMs for text ranking, we explore techniques to transfer the ranking expertise of LLMs to a more compact model similar to BERT, using a ranking loss to enable the deployment of less resource-intensive models. Specifically, we enhance the training of LLMs through Continued Pre-Training, taking the query as input and the clicked title and summary as output. We then proceed with supervised fine-tuning of the LLM using a rank loss, assigning the final token as a representative of the entire sentence. Given the inherent characteristics of autoregressive language models, only the final token </s> can encapsulate all preceding tokens. Additionally, we introduce a hybrid point-wise and margin MSE loss to transfer the ranking knowledge from LLMs to smaller models like BERT. This method creates a viable solution for environments with strict resource constraints. Both offline and online evaluations have confirmed the efficacy of our approach, and our model has been successfully integrated into a commercial web search engine as of February 2024.
Type-enriched Hierarchical Contrastive Strategy for Fine-Grained Entity Typing
Aug 22, 2022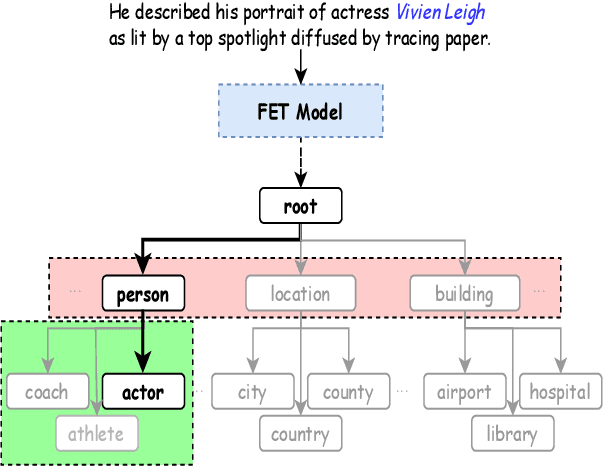
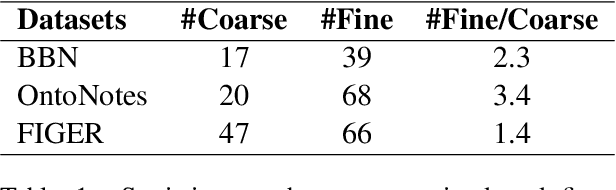
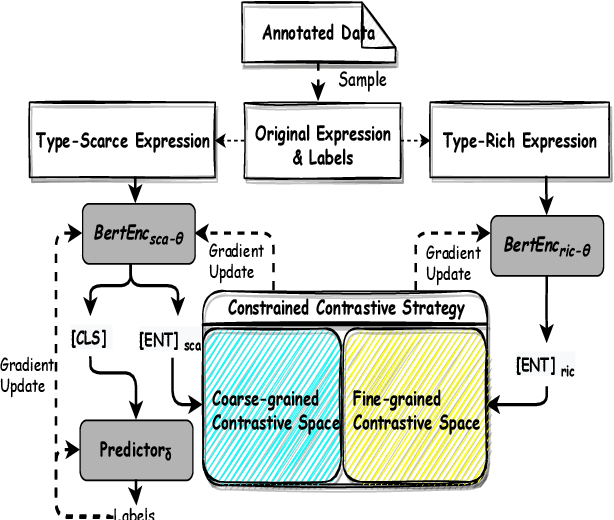
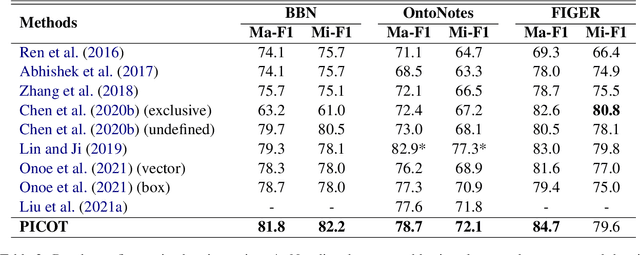
Fine-grained entity typing (FET) aims to deduce specific semantic types of the entity mentions in text. Modern methods for FET mainly focus on learning what a certain type looks like. And few works directly model the type differences, that is, let models know the extent that one type is different from others. To alleviate this problem, we propose a type-enriched hierarchical contrastive strategy for FET. Our method can directly model the differences between hierarchical types and improve the ability to distinguish multi-grained similar types. On the one hand, we embed type into entity contexts to make type information directly perceptible. On the other hand, we design a constrained contrastive strategy on the hierarchical structure to directly model the type differences, which can simultaneously perceive the distinguishability between types at different granularity. Experimental results on three benchmarks, BBN, OntoNotes, and FIGER show that our method achieves significant performance on FET by effectively modeling type differences.
ChiQA: A Large Scale Image-based Real-World Question Answering Dataset for Multi-Modal Understanding
Aug 05, 2022
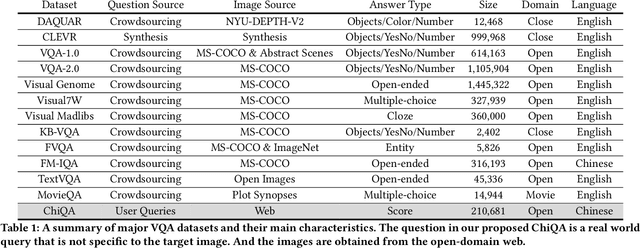

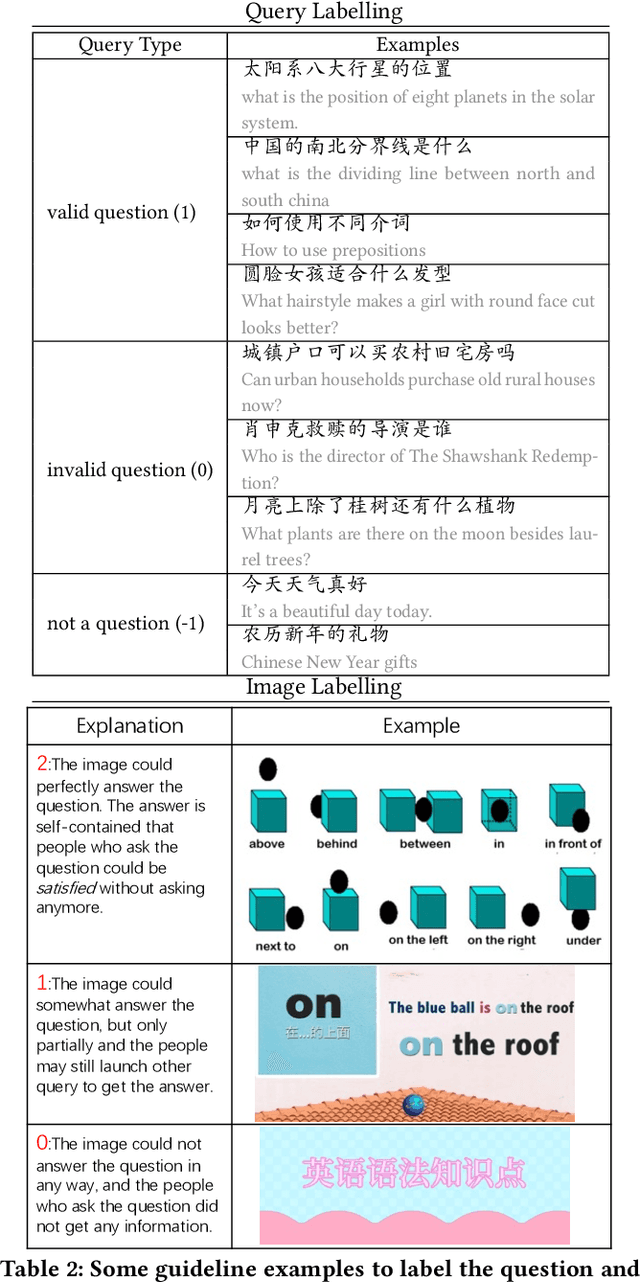
Visual question answering is an important task in both natural language and vision understanding. However, in most of the public visual question answering datasets such as VQA, CLEVR, the questions are human generated that specific to the given image, such as `What color are her eyes?'. The human generated crowdsourcing questions are relatively simple and sometimes have the bias toward certain entities or attributes. In this paper, we introduce a new question answering dataset based on image-ChiQA. It contains the real-world queries issued by internet users, combined with several related open-domain images. The system should determine whether the image could answer the question or not. Different from previous VQA datasets, the questions are real-world image-independent queries that are more various and unbiased. Compared with previous image-retrieval or image-caption datasets, the ChiQA not only measures the relatedness but also measures the answerability, which demands more fine-grained vision and language reasoning. ChiQA contains more than 40K questions and more than 200K question-images pairs. A three-level 2/1/0 label is assigned to each pair indicating perfect answer, partially answer and irrelevant. Data analysis shows ChiQA requires a deep understanding of both language and vision, including grounding, comparisons, and reading. We evaluate several state-of-the-art visual-language models such as ALBEF, demonstrating that there is still a large room for improvements on ChiQA.
Bridging the Gap Between Training and Inference of Bayesian Controllable Language Models
Jun 11, 2022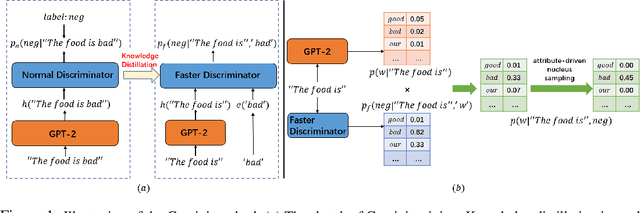

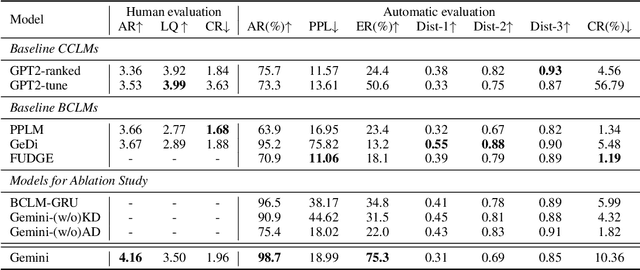
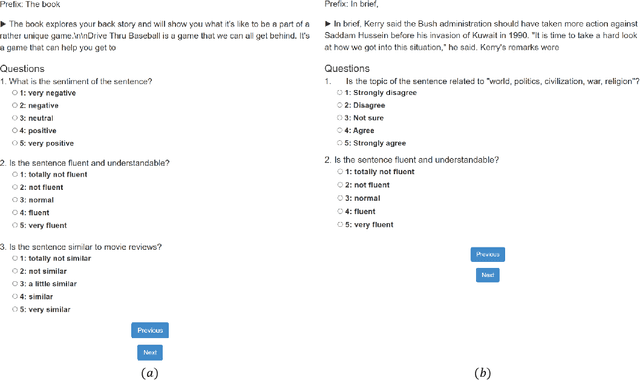
Large-scale pre-trained language models have achieved great success on natural language generation tasks. However, it is difficult to control the pre-trained language models to generate sentences with the desired attribute such as topic and sentiment, etc. Recently, Bayesian Controllable Language Models (BCLMs) have been shown to be efficient in controllable language generation. Rather than fine-tuning the parameters of pre-trained language models, BCLMs use external discriminators to guide the generation of pre-trained language models. However, the mismatch between training and inference of BCLMs limits the performance of the models. To address the problem, in this work we propose a "Gemini Discriminator" for controllable language generation which alleviates the mismatch problem with a small computational cost. We tested our method on two controllable language generation tasks: sentiment control and topic control. On both tasks, our method reached achieved new state-of-the-art results in automatic and human evaluations.