 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChiQA: A Large Scale Image-based Real-World Question Answering Dataset for Multi-Modal Understanding
Paper and Code

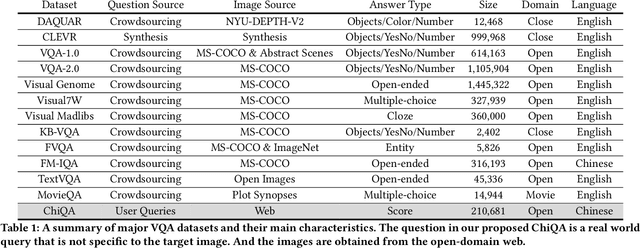

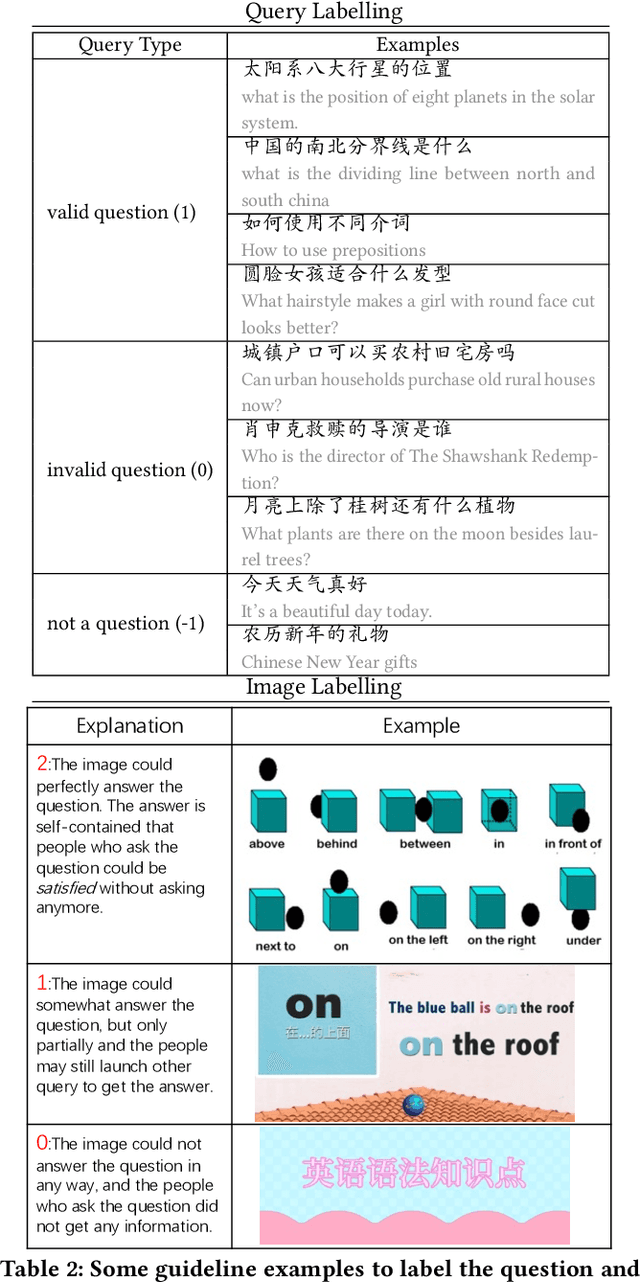
Visual question answering is an important task in both natural language and vision understanding. However, in most of the public visual question answering datasets such as VQA, CLEVR, the questions are human generated that specific to the given image, such as `What color are her eyes?'. The human generated crowdsourcing questions are relatively simple and sometimes have the bias toward certain entities or attributes. In this paper, we introduce a new question answering dataset based on image-ChiQA. It contains the real-world queries issued by internet users, combined with several related open-domain images. The system should determine whether the image could answer the question or not. Different from previous VQA datasets, the questions are real-world image-independent queries that are more various and unbiased. Compared with previous image-retrieval or image-caption datasets, the ChiQA not only measures the relatedness but also measures the answerability, which demands more fine-grained vision and language reasoning. ChiQA contains more than 40K questions and more than 200K question-images pairs. A three-level 2/1/0 label is assigned to each pair indicating perfect answer, partially answer and irrelevant. Data analysis shows ChiQA requires a deep understanding of both language and vision, including grounding, comparisons, and reading. We evaluate several state-of-the-art visual-language models such as ALBEF, demonstrating that there is still a large room for improvements on ChiQA.