 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness-enhanced Myoelectric Control with GAN-based Open-set Recognition
Dec 20, 2024



Electromyography (EMG) signals are widely used in human motion recognition and medical rehabilitation, yet their variability and susceptibility to noise significantly limit the reliability of myoelectric control systems. Existing recognition algorithms often fail to handle unfamiliar actions effectively, leading to system instability and errors. This paper proposes a novel framework based on Generative Adversarial Networks (GANs) to enhance the robustness and usability of myoelectric control systems by enabling open-set recognition. The method incorporates a GAN-based discriminator to identify and reject unknown actions, maintaining system stability by preventing misclassifications. Experimental evaluations on publicly available and self-collected datasets demonstrate a recognition accuracy of 97.6\% for known actions and a 23.6\% improvement in Active Error Rate (AER) after rejecting unknown actions. The proposed approach is computationally efficient and suitable for deployment on edge devices, making it practical for real-world applications.
ChiQA: A Large Scale Image-based Real-World Question Answering Dataset for Multi-Modal Understanding
Aug 05, 2022
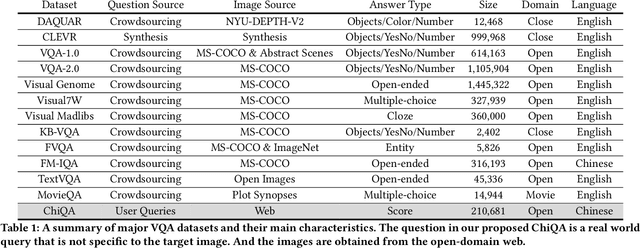

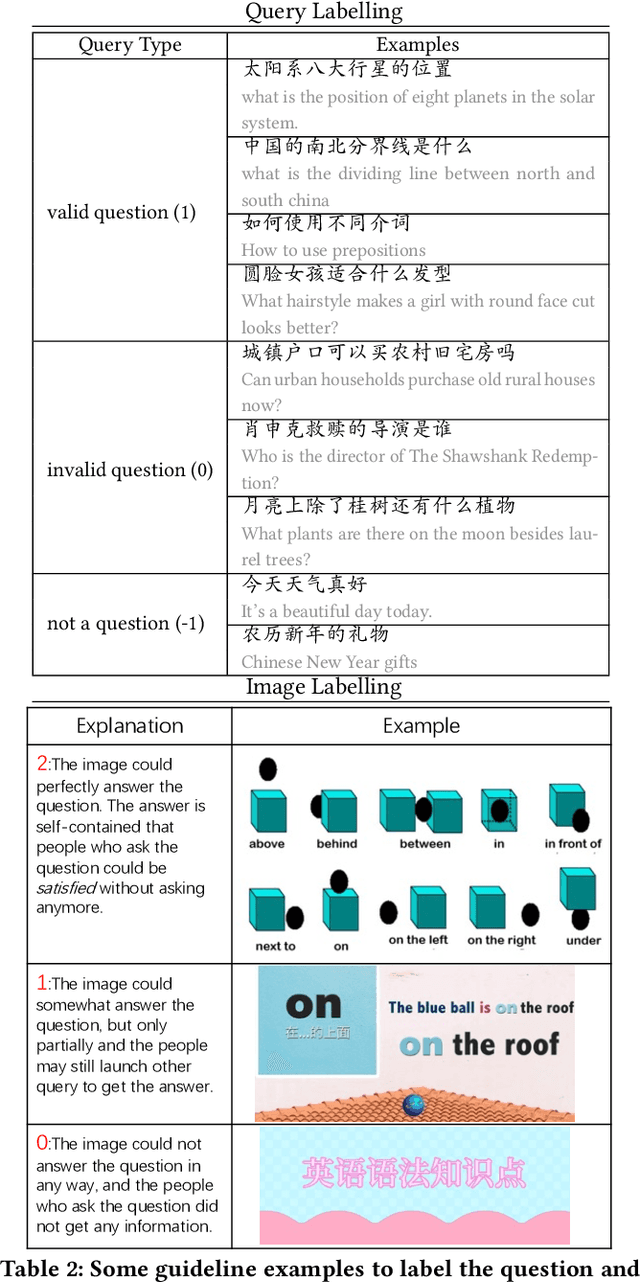
Visual question answering is an important task in both natural language and vision understanding. However, in most of the public visual question answering datasets such as VQA, CLEVR, the questions are human generated that specific to the given image, such as `What color are her eyes?'. The human generated crowdsourcing questions are relatively simple and sometimes have the bias toward certain entities or attributes. In this paper, we introduce a new question answering dataset based on image-ChiQA. It contains the real-world queries issued by internet users, combined with several related open-domain images. The system should determine whether the image could answer the question or not. Different from previous VQA datasets, the questions are real-world image-independent queries that are more various and unbiased. Compared with previous image-retrieval or image-caption datasets, the ChiQA not only measures the relatedness but also measures the answerability, which demands more fine-grained vision and language reasoning. ChiQA contains more than 40K questions and more than 200K question-images pairs. A three-level 2/1/0 label is assigned to each pair indicating perfect answer, partially answer and irrelevant. Data analysis shows ChiQA requires a deep understanding of both language and vision, including grounding, comparisons, and reading. We evaluate several state-of-the-art visual-language models such as ALBEF, demonstrating that there is still a large room for improvements on ChiQA.