 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint graph entropy knowledge distillation for point cloud classification and robustness against corruptions
Sep 26, 2025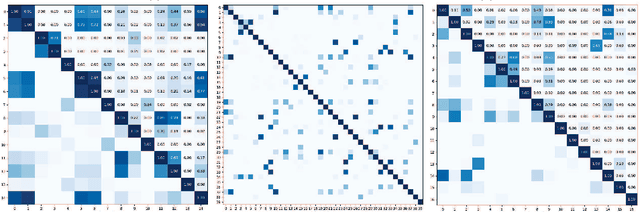



Classification tasks in 3D point clouds often assume that class events \replaced{are }{follow }independent and identically distributed (IID), although this assumption destroys the correlation between classes. This \replaced{study }{paper }proposes a classification strategy, \textbf{J}oint \textbf{G}raph \textbf{E}ntropy \textbf{K}nowledge \textbf{D}istillation (JGEKD), suitable for non-independent and identically distributed 3D point cloud data, \replaced{which }{the strategy } achieves knowledge transfer of class correlations through knowledge distillation by constructing a loss function based on joint graph entropy. First\deleted{ly}, we employ joint graphs to capture add{the }hidden relationships between classes\replaced{ and}{,} implement knowledge distillation to train our model by calculating the entropy of add{add }graph.\replaced{ Subsequently}{ Then}, to handle 3D point clouds \deleted{that is }invariant to spatial transformations, we construct \replaced{S}{s}iamese structures and develop two frameworks, self-knowledge distillation and teacher-knowledge distillation, to facilitate information transfer between different transformation forms of the same data. \replaced{In addition}{ Additionally}, we use the above framework to achieve knowledge transfer between point clouds and their corrupted forms, and increase the robustness against corruption of model. Extensive experiments on ScanObject, ModelNet40, ScanntV2\_cls and ModelNet-C demonstrate that the proposed strategy can achieve competitive results.
Rule-Assisted Attribute Embedding
Jun 10, 2025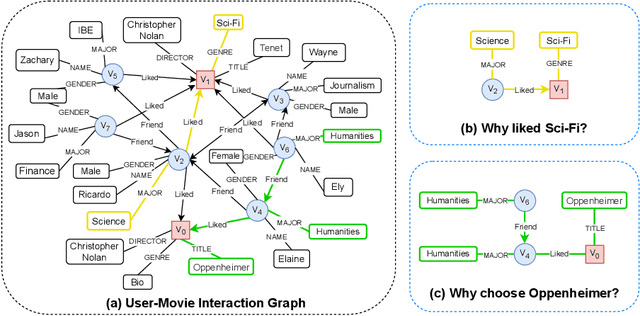
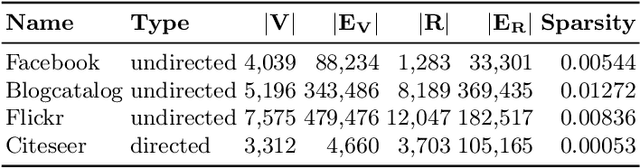
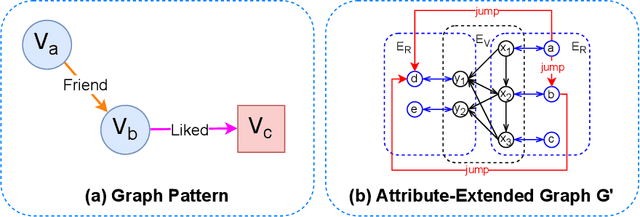
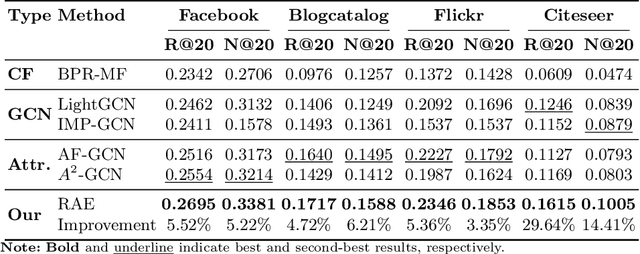
Recommendation systems often overlook the rich attribute information embedded in property graphs, limiting their effectiveness. Existing graph convolutional network (GCN) models either ignore attributes or rely on simplistic <user, item, attribute> triples, failing to capture deeper semantic structures. We propose RAE (Rule- Assisted Approach for Attribute Embedding), a novel method that improves recommendations by mining semantic rules from property graphs to guide attribute embedding. RAE performs rule-based random walks to generate enriched attribute representations, which are integrated into GCNs. Experiments on real-world datasets (BlogCatalog, Flickr) show that RAE outperforms state-of-the-art baselines by 10.6% on average in Recall@20 and NDCG@20. RAE also demonstrates greater robustness to sparse data and missing attributes, highlighting the value of leveraging structured attribute information in recommendation tasks.
Best Practices for Distilling Large Language Models into BERT for Web Search Ranking
Nov 07, 2024Recent studies have highlighted the significant potential of Large Language Models (LLMs) as zero-shot relevance rankers. These methods predominantly utilize prompt learning to assess the relevance between queries and documents by generating a ranked list of potential documents. Despite their promise, the substantial costs associated with LLMs pose a significant challenge for their direct implementation in commercial search systems. To overcome this barrier and fully exploit the capabilities of LLMs for text ranking, we explore techniques to transfer the ranking expertise of LLMs to a more compact model similar to BERT, using a ranking loss to enable the deployment of less resource-intensive models. Specifically, we enhance the training of LLMs through Continued Pre-Training, taking the query as input and the clicked title and summary as output. We then proceed with supervised fine-tuning of the LLM using a rank loss, assigning the final token as a representative of the entire sentence. Given the inherent characteristics of autoregressive language models, only the final token </s> can encapsulate all preceding tokens. Additionally, we introduce a hybrid point-wise and margin MSE loss to transfer the ranking knowledge from LLMs to smaller models like BERT. This method creates a viable solution for environments with strict resource constraints. Both offline and online evaluations have confirmed the efficacy of our approach, and our model has been successfully integrated into a commercial web search engine as of February 2024.
GIG: Graph Data Imputation With Graph Differential Dependencies
Oct 21, 2024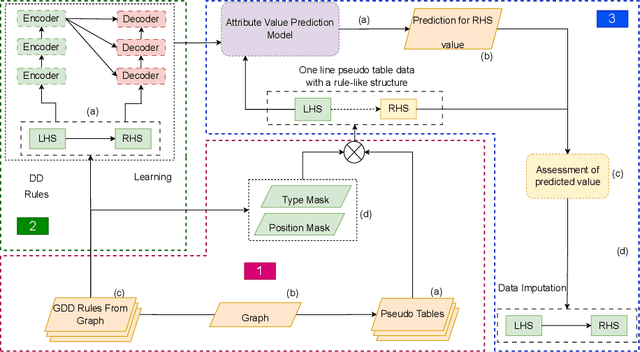

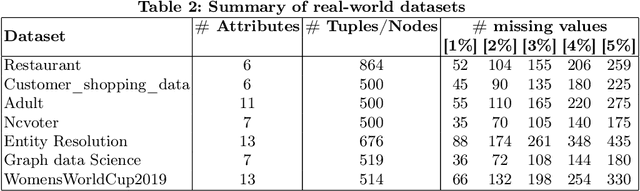
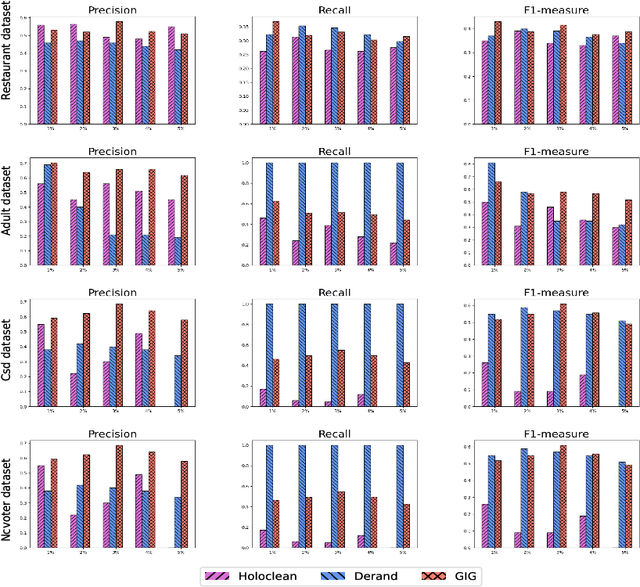
Data imputation addresses the challenge of imputing missing values in database instances, ensuring consistency with the overall semantics of the dataset. Although several heuristics which rely on statistical methods, and ad-hoc rules have been proposed. These do not generalise well and often lack data context. Consequently, they also lack explainability. The existing techniques also mostly focus on the relational data context making them unsuitable for wider application contexts such as in graph data. In this paper, we propose a graph data imputation approach called GIG which relies on graph differential dependencies (GDDs). GIG, learns the GDDs from a given knowledge graph, and uses these rules to train a transformer model which then predicts the value of missing data within the graph. By leveraging GDDs, GIG incoporates semantic knowledge into the data imputation process making it more reliable and explainable. Experimental results on seven real-world datasets highlight GIG's effectiveness compared to existing state-of-the-art approaches.