 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStruProKGR: A Structural and Probabilistic Framework for Sparse Knowledge Graph Reasoning
Dec 14, 2025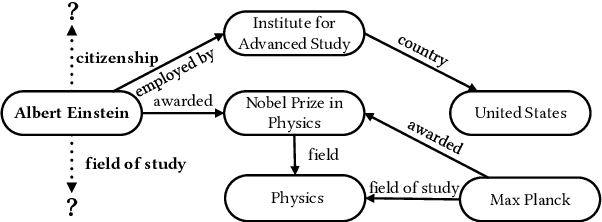
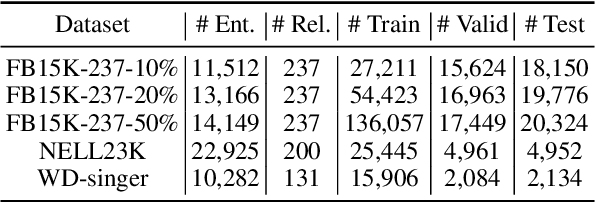
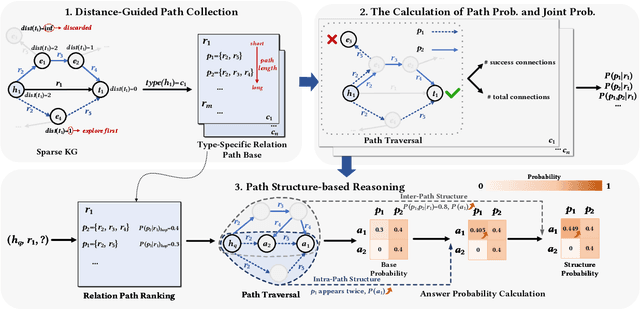
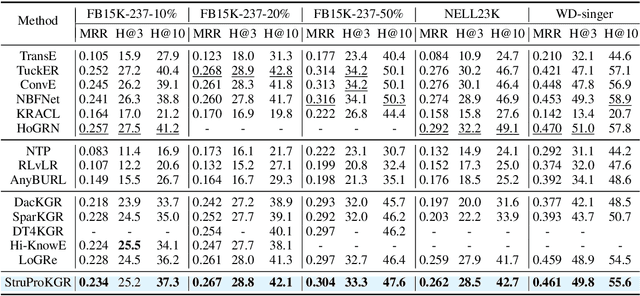
Sparse Knowledge Graphs (KGs) are commonly encountered in real-world applications, where knowledge is often incomplete or limited. Sparse KG reasoning, the task of inferring missing knowledge over sparse KGs, is inherently challenging due to the scarcity of knowledge and the difficulty of capturing relational patterns in sparse scenarios. Among all sparse KG reasoning methods, path-based ones have attracted plenty of attention due to their interpretability. Existing path-based methods typically rely on computationally intensive random walks to collect paths, producing paths of variable quality. Additionally, these methods fail to leverage the structured nature of graphs by treating paths independently. To address these shortcomings, we propose a Structural and Probabilistic framework named StruProKGR, tailored for efficient and interpretable reasoning on sparse KGs. StruProKGR utilizes a distance-guided path collection mechanism to significantly reduce computational costs while exploring more relevant paths. It further enhances the reasoning process by incorporating structural information through probabilistic path aggregation, which prioritizes paths that reinforce each other. Extensive experiments on five sparse KG reasoning benchmarks reveal that StruProKGR surpasses existing path-based methods in both effectiveness and efficiency, providing an effective, efficient, and interpretable solution for sparse KG reasoning.
RouteRAG: Efficient Retrieval-Augmented Generation from Text and Graph via Reinforcement Learning
Dec 10, 2025Retrieval-Augmented Generation (RAG) integrates non-parametric knowledge into Large Language Models (LLMs), typically from unstructured texts and structured graphs. While recent progress has advanced text-based RAG to multi-turn reasoning through Reinforcement Learning (RL), extending these advances to hybrid retrieval introduces additional challenges. Existing graph-based or hybrid systems typically depend on fixed or handcrafted retrieval pipelines, lacking the ability to integrate supplementary evidence as reasoning unfolds. Besides, while graph evidence provides relational structures crucial for multi-hop reasoning, it is substantially more expensive to retrieve. To address these limitations, we introduce \model{}, an RL-based framework that enables LLMs to perform multi-turn and adaptive graph-text hybrid RAG. \model{} jointly optimizes the entire generation process via RL, allowing the model to learn when to reason, what to retrieve from either texts or graphs, and when to produce final answers, all within a unified generation policy. To guide this learning process, we design a two-stage training framework that accounts for both task outcome and retrieval efficiency, enabling the model to exploit hybrid evidence while avoiding unnecessary retrieval overhead. Experimental results across five question answering benchmarks demonstrate that \model{} significantly outperforms existing RAG baselines, highlighting the benefits of end-to-end RL in supporting adaptive and efficient retrieval for complex reasoning.
A Survey of Link Prediction in N-ary Knowledge Graphs
Jun 10, 2025



N-ary Knowledge Graphs (NKGs) are a specialized type of knowledge graph designed to efficiently represent complex real-world facts. Unlike traditional knowledge graphs, where a fact typically involves two entities, NKGs can capture n-ary facts containing more than two entities. Link prediction in NKGs aims to predict missing elements within these n-ary facts, which is essential for completing NKGs and improving the performance of downstream applications. This task has recently gained significant attention. In this paper, we present the first comprehensive survey of link prediction in NKGs, providing an overview of the field, systematically categorizing existing methods, and analyzing their performance and application scenarios. We also outline promising directions for future research.
Look Globally and Reason: Two-stage Path Reasoning over Sparse Knowledge Graphs
Jul 26, 2024



Sparse Knowledge Graphs (KGs), frequently encountered in real-world applications, contain fewer facts in the form of (head entity, relation, tail entity) compared to more populated KGs. The sparse KG completion task, which reasons answers for given queries in the form of (head entity, relation, ?) for sparse KGs, is particularly challenging due to the necessity of reasoning missing facts based on limited facts. Path-based models, known for excellent explainability, are often employed for this task. However, existing path-based models typically rely on external models to fill in missing facts and subsequently perform path reasoning. This approach introduces unexplainable factors or necessitates meticulous rule design. In light of this, this paper proposes an alternative approach by looking inward instead of seeking external assistance. We introduce a two-stage path reasoning model called LoGRe (Look Globally and Reason) over sparse KGs. LoGRe constructs a relation-path reasoning schema by globally analyzing the training data to alleviate the sparseness problem. Based on this schema, LoGRe then aggregates paths to reason out answers. Experimental results on five benchmark sparse KG datasets demonstrate the effectiveness of the proposed LoGRe model.
An In-Context Schema Understanding Method for Knowledge Base Question Answering
Oct 22, 2023


The Knowledge Base Question Answering (KBQA) task aims to answer natural language questions based on a given knowledge base. As a kind of common method for this task, semantic parsing-based ones first convert natural language questions to logical forms (e.g., SPARQL queries) and then execute them on knowledge bases to get answers. Recently, Large Language Models (LLMs) have shown strong abilities in language understanding and may be adopted as semantic parsers in such kinds of methods. However, in doing so, a great challenge for LLMs is to understand the schema of knowledge bases. Therefore, in this paper, we propose an In-Context Schema Understanding (ICSU) method for facilitating LLMs to be used as a semantic parser in KBQA. Specifically, ICSU adopts the In-context Learning mechanism to instruct LLMs to generate SPARQL queries with examples. In order to retrieve appropriate examples from annotated question-query pairs, which contain comprehensive schema information related to questions, ICSU explores four different retrieval strategies. Experimental results on the largest KBQA benchmark, KQA Pro, show that ICSU with all these strategies outperforms that with a random retrieval strategy significantly (from 12\% to 78.76\% in accuracy).
Nested Event Extraction upon Pivot Element Recogniton
Sep 22, 2023



Nested Event Extraction (NEE) aims to extract complex event structures where an event contains other events as its arguments recursively. Nested events involve a kind of Pivot Elements (PEs) that simultaneously act as arguments of outer events and as triggers of inner events, and thus connect them into nested structures. This special characteristic of PEs brings challenges to existing NEE methods, as they cannot well cope with the dual identities of PEs. Therefore, this paper proposes a new model, called PerNee, which extracts nested events mainly based on recognizing PEs. Specifically, PerNee first recognizes the triggers of both inner and outer events and further recognizes the PEs via classifying the relation type between trigger pairs. In order to obtain better representations of triggers and arguments to further improve NEE performance, it incorporates the information of both event types and argument roles into PerNee through prompt learning. Since existing NEE datasets (e.g., Genia11) are limited to specific domains and contain a narrow range of event types with nested structures, we systematically categorize nested events in generic domain and construct a new NEE dataset, namely ACE2005-Nest. Experimental results demonstrate that PerNee consistently achieves state-of-the-art performance on ACE2005-Nest, Genia11 and Genia13.
Semantic Structure Enhanced Event Causality Identification
May 22, 2023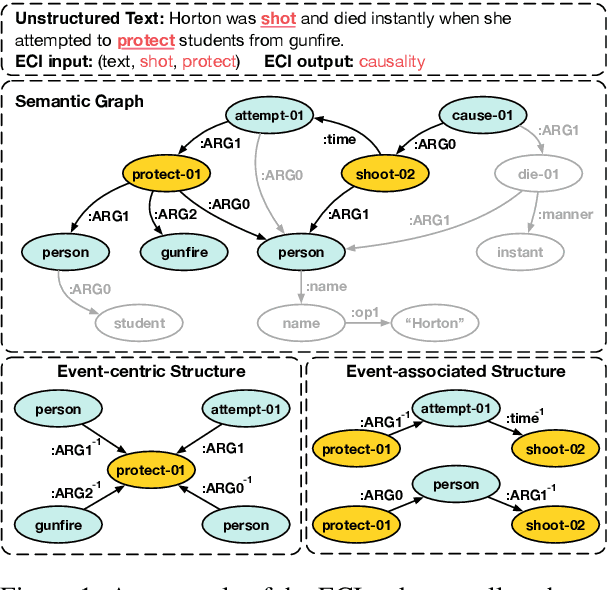
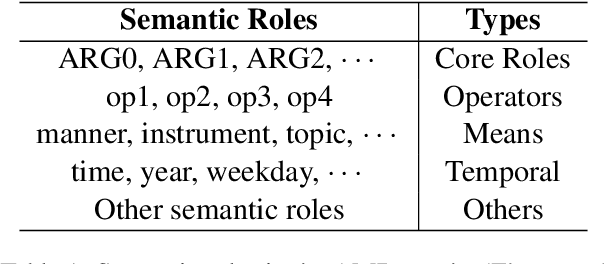
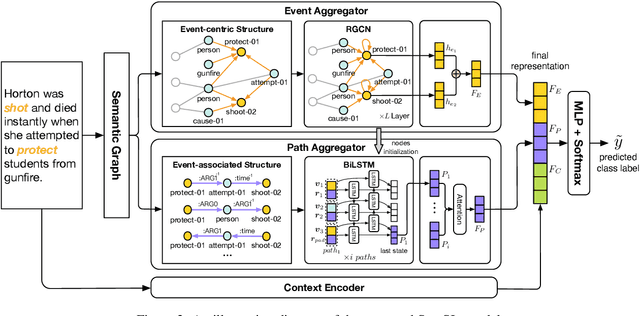
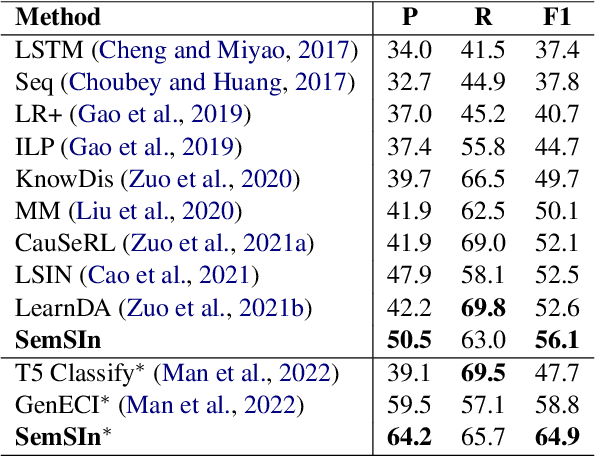
Event Causality Identification (ECI) aims to identify causal relations between events in unstructured texts. This is a very challenging task, because causal relations are usually expressed by implicit associations between events. Existing methods usually capture such associations by directly modeling the texts with pre-trained language models, which underestimate two kinds of semantic structures vital to the ECI task, namely, event-centric structure and event-associated structure. The former includes important semantic elements related to the events to describe them more precisely, while the latter contains semantic paths between two events to provide possible supports for ECI. In this paper, we study the implicit associations between events by modeling the above explicit semantic structures, and propose a Semantic Structure Integration model (SemSIn). It utilizes a GNN-based event aggregator to integrate the event-centric structure information, and employs an LSTM-based path aggregator to capture the event-associated structure information between two events. Experimental results on three widely used datasets show that SemSIn achieves significant improvements over baseline methods.
Few-shot Link Prediction on N-ary Facts
May 10, 2023N-ary facts composed of a primary triple (head entity, relation, tail entity) and an arbitrary number of auxiliary attribute-value pairs, are prevalent in real-world knowledge graphs (KGs). Link prediction on n-ary facts is to predict a missing element in an n-ary fact. This helps populate and enrich KGs and further promotes numerous downstream applications. Previous studies usually require a substantial amount of high-quality data to understand the elements in n-ary facts. However, these studies overlook few-shot relations, which have limited labeled instances, yet are common in real-world scenarios. Thus, this paper introduces a new task, few-shot link prediction on n-ary facts. It aims to predict a missing entity in an n-ary fact with limited labeled instances. We further propose a model for Few-shot Link prEdict on N-ary facts, thus called FLEN, which consists of three modules: the relation learning, support-specific adjusting, and query inference modules. FLEN captures relation meta information from limited instances to predict a missing entity in a query instance. To validate the effectiveness of FLEN, we construct three datasets based on existing benchmark data. Our experimental results show that FLEN significantly outperforms existing related models in both few-shot link prediction on n-ary facts and binary facts.
Rich Event Modeling for Script Event Prediction
Dec 16, 2022Script is a kind of structured knowledge extracted from texts, which contains a sequence of events. Based on such knowledge, script event prediction aims to predict the subsequent event. To do so, two aspects should be considered for events, namely, event description (i.e., what the events should contain) and event encoding (i.e., how they should be encoded). Most existing methods describe an event by a verb together with only a few core arguments (i.e., subject, object, and indirect object), which are not precise. In addition, existing event encoders are limited to a fixed number of arguments, which are not flexible to deal with extra information. Thus, in this paper, we propose the Rich Event Prediction (REP) framework for script event prediction. Fundamentally, it is based on the proposed rich event description, which enriches the existing ones with three kinds of important information, namely, the senses of verbs, extra semantic roles, and types of participants. REP contains an event extractor to extract such information from texts. Based on the extracted rich information, a predictor then selects the most probable subsequent event. The core component of the predictor is a transformer-based event encoder to flexibly deal with an arbitrary number of arguments. Experimental results on the widely used Gigaword Corpus show the effectiveness of the proposed framework.
HiSMatch: Historical Structure Matching based Temporal Knowledge Graph Reasoning
Oct 18, 2022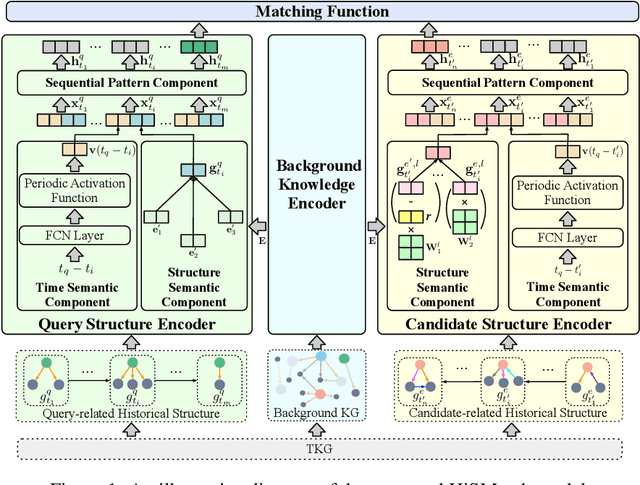
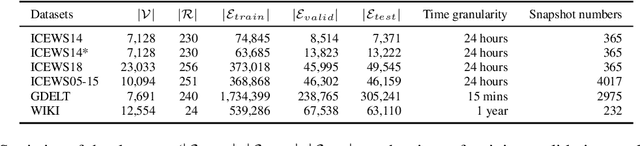
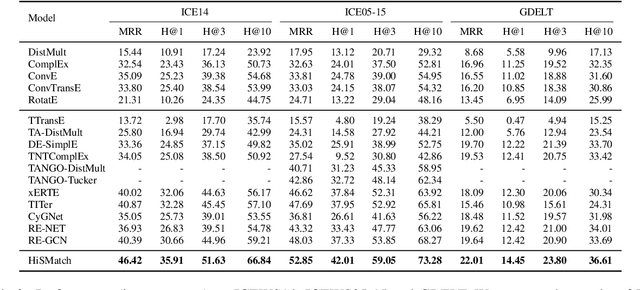
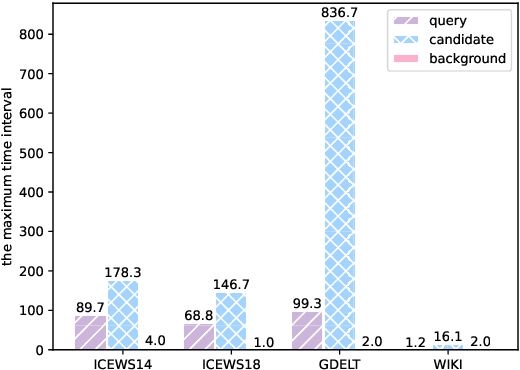
A Temporal Knowledge Graph (TKG) is a sequence of KGs with respective timestamps, which adopts quadruples in the form of (\emph{subject}, \emph{relation}, \emph{object}, \emph{timestamp}) to describe dynamic facts. TKG reasoning has facilitated many real-world applications via answering such queries as (\emph{query entity}, \emph{query relation}, \emph{?}, \emph{future timestamp}) about future. This is actually a matching task between a query and candidate entities based on their historical structures, which reflect behavioral trends of the entities at different timestamps. In addition, recent KGs provide background knowledge of all the entities, which is also helpful for the matching. Thus, in this paper, we propose the \textbf{Hi}storical \textbf{S}tructure \textbf{Match}ing (\textbf{HiSMatch}) model. It applies two structure encoders to capture the semantic information contained in the historical structures of the query and candidate entities. Besides, it adopts another encoder to integrate the background knowledge into the model. TKG reasoning experiments on six benchmark datasets demonstrate the significant improvement of the proposed HiSMatch model, with up to 5.6\% performance improvement in MRR, compared to the state-of-the-art baselines.