 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSception: A Deep Learning Framework for Emotion Detection Using EEG
Apr 08, 2020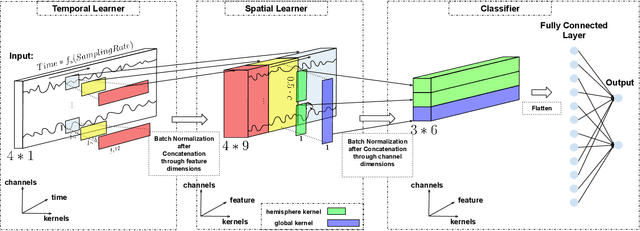



In this paper, we propose a deep learning framework, TSception, for emotion detection from electroencephalogram (EEG). TSception consists of temporal and spatial convolutional layers, which learn discriminative representations in the time and channel domains simultaneously. The temporal learner consists of multi-scale 1D convolutional kernels whose lengths are related to the sampling rate of the EEG signal, which learns multiple temporal and frequency representations. The spatial learner takes advantage of the asymmetry property of emotion responses at the frontal brain area to learn the discriminative representations from the left and right hemispheres of the brain. In our study, a system is designed to study the emotional arousal in an immersive virtual reality (VR) environment. EEG data were collected from 18 healthy subjects using this system to evaluate the performance of the proposed deep learning network for the classification of low and high emotional arousal states. The proposed method is compared with SVM, EEGNet, and LSTM. TSception achieves a high classification accuracy of 86.03%, which outperforms the prior methods significantly (p<0.05). The code is available at https://github.com/deepBrains/TSception
Towards a Fast Steady-State Visual Evoked Potentials Brain-Computer Interface
Feb 04, 2020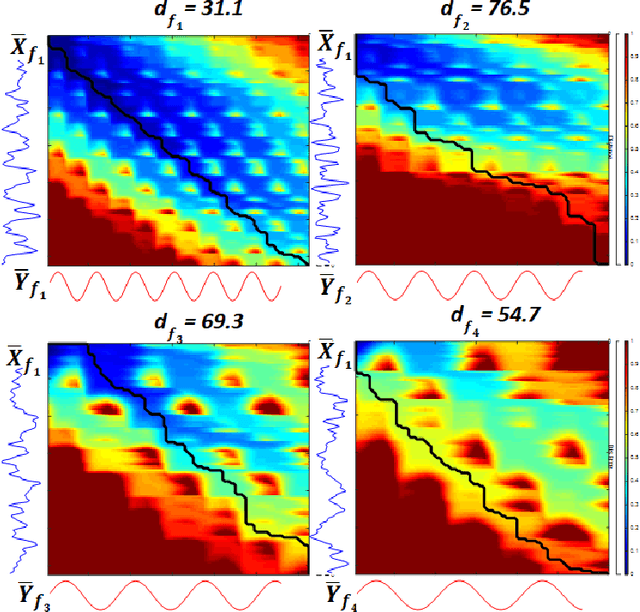
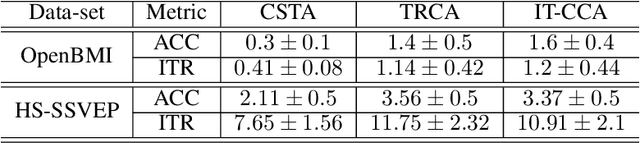
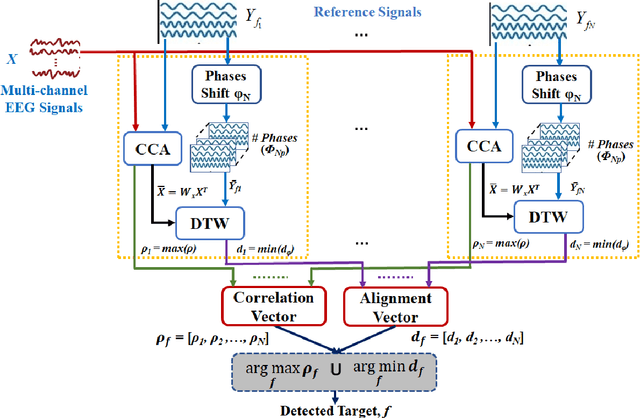
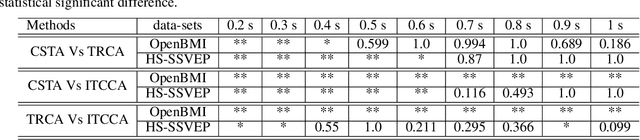
Steady-state visual evoked potentials (SSVEP) brain-computer interface (BCI) provides reliable responses leading to high accuracy and information throughput. But achieving high accuracy typically requires a relatively long time window of one second or more. Various methods were proposed to improve sub-second response accuracy through subject-specific training and calibration. Substantial performance improvements were achieved with tedious calibration and subject-specific training; resulting in the user's discomfort. So, we propose a training-free method by combining spatial-filtering and temporal alignment (CSTA) to recognize SSVEP responses in sub-second response time. CSTA exploits linear correlation and non-linear similarity between steady-state responses and stimulus templates with complementary fusion to achieve desirable performance improvements. We evaluated the performance of CSTA in terms of accuracy and Information Transfer Rate (ITR) in comparison with both training-based and training-free methods using two SSVEP data-sets. We observed that CSTA achieves the maximum mean accuracy of 97.43$\pm$2.26 % and 85.71$\pm$13.41 % with four-class and forty-class SSVEP data-sets respectively in sub-second response time in offline analysis. CSTA yields significantly higher mean performance (p<0.001) than the training-free method on both data-sets. Compared with training-based methods, CSTA shows 29.33$\pm$19.65 % higher mean accuracy with statistically significant differences in time window less than 0.5 s. In longer time windows, CSTA exhibits either better or comparable performance though not statistically significantly better than training-based methods. We show that the proposed method brings advantages of subject-independent SSVEP classification without requiring training while enabling high target recognition performance in sub-second response time.