 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression
Oct 26, 2021
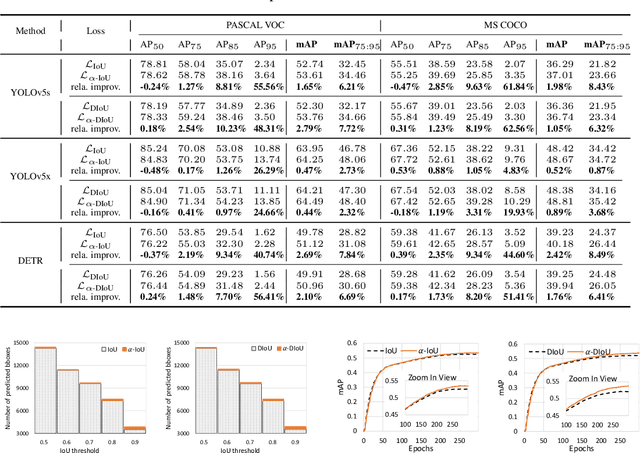
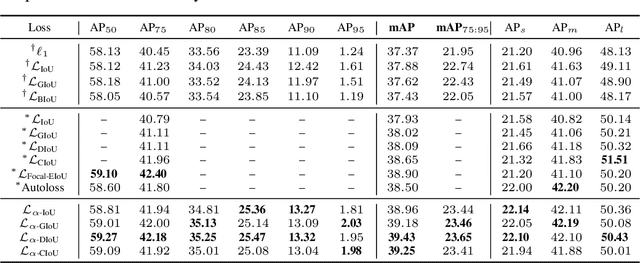
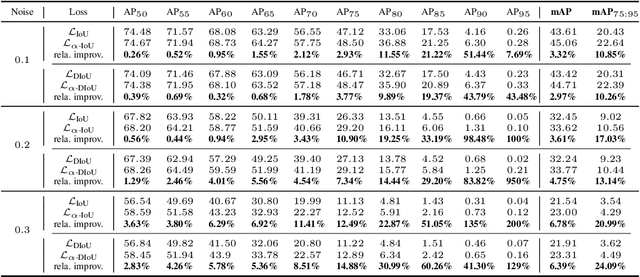
Bounding box (bbox) regression is a fundamental task in computer vision. So far, the most commonly used loss functions for bbox regression are the Intersection over Union (IoU) loss and its variants. In this paper, we generalize existing IoU-based losses to a new family of power IoU losses that have a power IoU term and an additional power regularization term with a single power parameter $\alpha$. We call this new family of losses the $\alpha$-IoU losses and analyze properties such as order preservingness and loss/gradient reweighting. Experiments on multiple object detection benchmarks and models demonstrate that $\alpha$-IoU losses, 1) can surpass existing IoU-based losses by a noticeable performance margin; 2) offer detectors more flexibility in achieving different levels of bbox regression accuracy by modulating $\alpha$; and 3) are more robust to small datasets and noisy bboxes.
CPR-GCN: Conditional Partial-Residual Graph Convolutional Network in Automated Anatomical Labeling of Coronary Arteries
Apr 18, 2020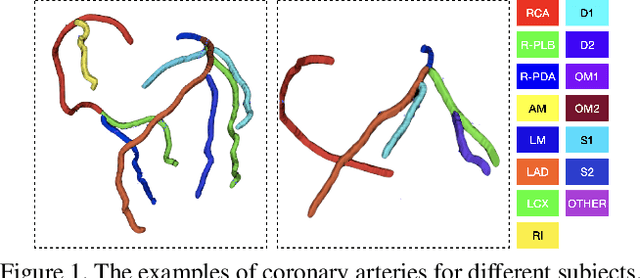
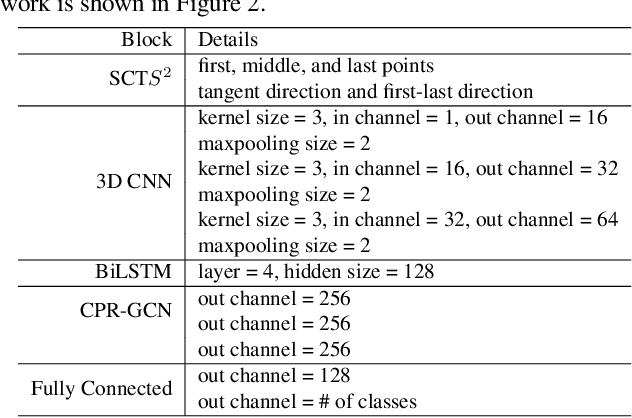
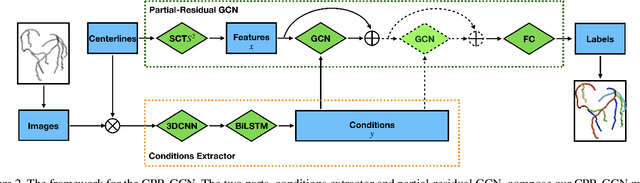
Automated anatomical labeling plays a vital role in coronary artery disease diagnosing procedure. The main challenge in this problem is the large individual variability inherited in human anatomy. Existing methods usually rely on the position information and the prior knowledge of the topology of the coronary artery tree, which may lead to unsatisfactory performance when the main branches are confusing. Motivated by the wide application of the graph neural network in structured data, in this paper, we propose a conditional partial-residual graph convolutional network (CPR-GCN), which takes both position and CT image into consideration, since CT image contains abundant information such as branch size and spanning direction. Two majority parts, a Partial-Residual GCN and a conditions extractor, are included in CPR-GCN. The conditions extractor is a hybrid model containing the 3D CNN and the LSTM, which can extract 3D spatial image features along the branches. On the technical side, the Partial-Residual GCN takes the position features of the branches, with the 3D spatial image features as conditions, to predict the label for each branches. While on the mathematical side, our approach twists the partial differential equation (PDE) into the graph modeling. A dataset with 511 subjects is collected from the clinic and annotated by two experts with a two-phase annotation process. According to the five-fold cross-validation, our CPR-GCN yields 95.8% meanRecall, 95.4% meanPrecision and 0.955 meanF1, which outperforms state-of-the-art approaches.
* This work is done by Xingjian Zhen during internship in Alibaba Damo Academy
Towards a Fast Steady-State Visual Evoked Potentials Brain-Computer Interface
Feb 04, 2020
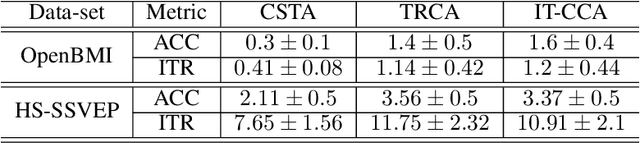
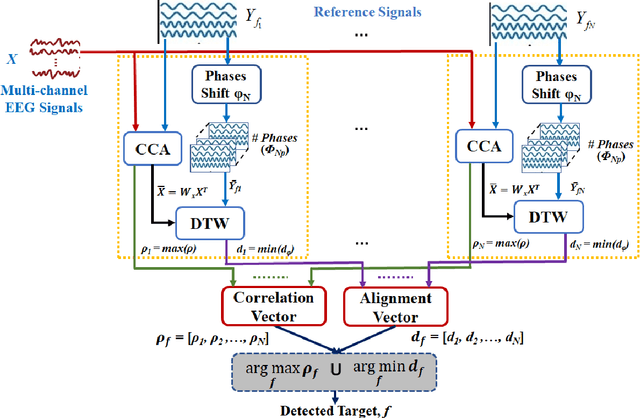
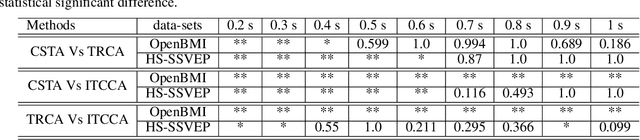
Steady-state visual evoked potentials (SSVEP) brain-computer interface (BCI) provides reliable responses leading to high accuracy and information throughput. But achieving high accuracy typically requires a relatively long time window of one second or more. Various methods were proposed to improve sub-second response accuracy through subject-specific training and calibration. Substantial performance improvements were achieved with tedious calibration and subject-specific training; resulting in the user's discomfort. So, we propose a training-free method by combining spatial-filtering and temporal alignment (CSTA) to recognize SSVEP responses in sub-second response time. CSTA exploits linear correlation and non-linear similarity between steady-state responses and stimulus templates with complementary fusion to achieve desirable performance improvements. We evaluated the performance of CSTA in terms of accuracy and Information Transfer Rate (ITR) in comparison with both training-based and training-free methods using two SSVEP data-sets. We observed that CSTA achieves the maximum mean accuracy of 97.43$\pm$2.26 % and 85.71$\pm$13.41 % with four-class and forty-class SSVEP data-sets respectively in sub-second response time in offline analysis. CSTA yields significantly higher mean performance (p<0.001) than the training-free method on both data-sets. Compared with training-based methods, CSTA shows 29.33$\pm$19.65 % higher mean accuracy with statistically significant differences in time window less than 0.5 s. In longer time windows, CSTA exhibits either better or comparable performance though not statistically significantly better than training-based methods. We show that the proposed method brings advantages of subject-independent SSVEP classification without requiring training while enabling high target recognition performance in sub-second response time.
Automated Segmentation of Pulmonary Lobes using Coordination-Guided Deep Neural Networks
Apr 19, 2019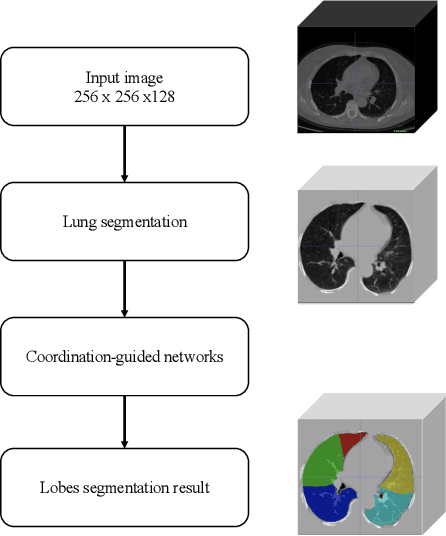
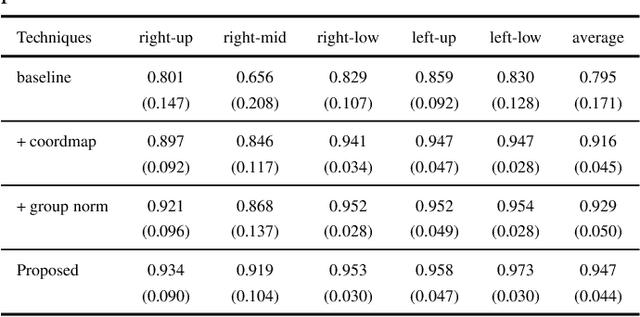
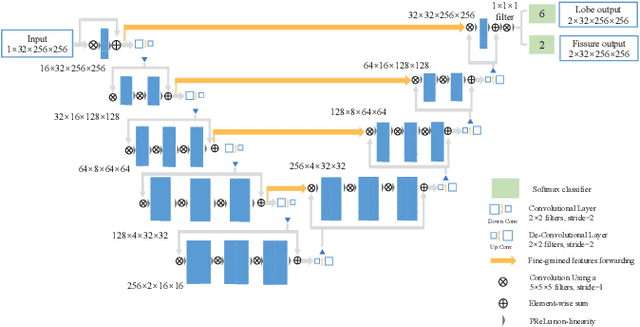
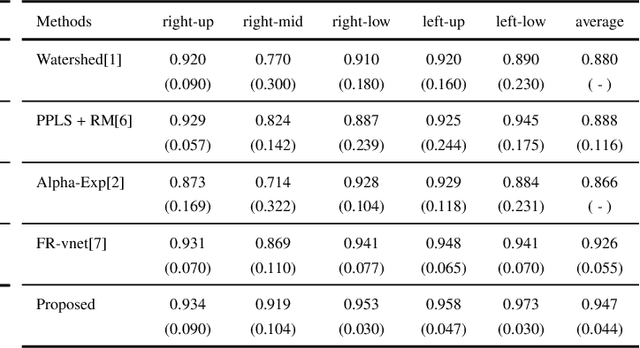
The identification of pulmonary lobes is of great importance in disease diagnosis and treatment. A few lung diseases have regional disorders at lobar level. Thus, an accurate segmentation of pulmonary lobes is necessary. In this work, we propose an automated segmentation of pulmonary lobes using coordination-guided deep neural networks from chest CT images. We first employ an automated lung segmentation to extract the lung area from CT image, then exploit volumetric convolutional neural network (V-net) for segmenting the pulmonary lobes. To reduce the misclassification of different lobes, we therefore adopt coordination-guided convolutional layers (CoordConvs) that generate additional feature maps of the positional information of pulmonary lobes. The proposed model is trained and evaluated on a few publicly available datasets and has achieved the state-of-the-art accuracy with a mean Dice coefficient index of 0.947 $\pm$ 0.044.