 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Generate, Annotate, and Learn: Generative Models Advance Self-Training and Knowledge Distillation
Jun 11, 2021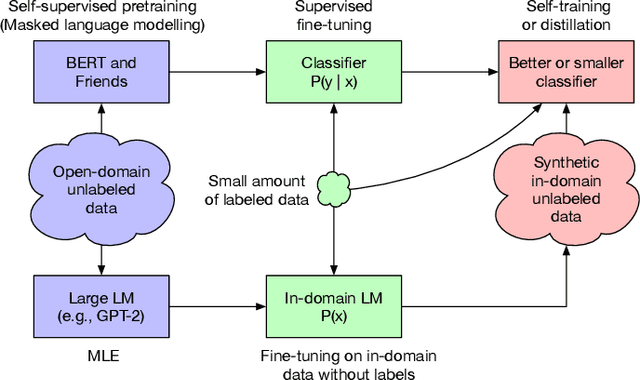
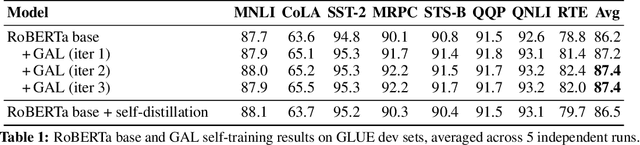
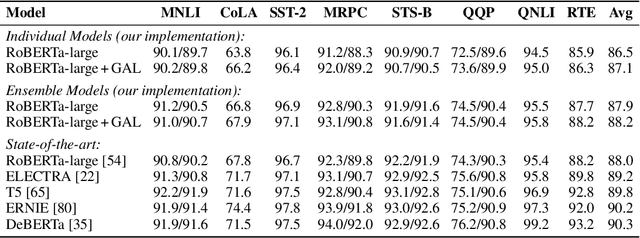
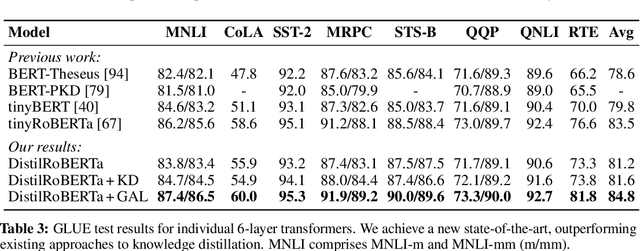
Semi-Supervised Learning (SSL) has seen success in many application domains, but this success often hinges on the availability of task-specific unlabeled data. Knowledge distillation (KD) has enabled compressing deep networks and ensembles, achieving the best results when distilling knowledge on fresh task-specific unlabeled examples. However, task-specific unlabeled data can be challenging to find. We present a general framework called "generate, annotate, and learn (GAL)" that uses unconditional generative models to synthesize in-domain unlabeled data, helping advance SSL and KD on different tasks. To obtain strong task-specific generative models, we adopt generic generative models, pretrained on open-domain data, and fine-tune them on inputs from specific tasks. Then, we use existing classifiers to annotate generated unlabeled examples with soft pseudo labels, which are used for additional training. When self-training is combined with samples generated from GPT2-large, fine-tuned on the inputs of each GLUE task, we outperform a strong RoBERTa-large baseline on the GLUE benchmark. Moreover, KD on GPT-2 samples yields a new state-of-the-art for 6-layer transformers on the GLUE leaderboard. Finally, self-training with GAL offers significant gains on image classification on CIFAR-10 and four tabular tasks from the UCI repository
Multichannel Generative Language Model: Learning All Possible Factorizations Within and Across Channels
Oct 09, 2020
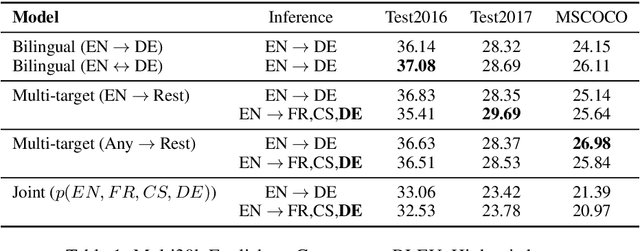
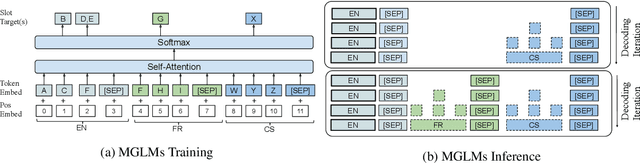
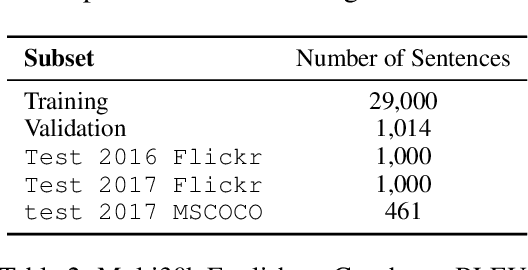
A channel corresponds to a viewpoint or transformation of an underlying meaning. A pair of parallel sentences in English and French express the same underlying meaning, but through two separate channels corresponding to their languages. In this work, we present the Multichannel Generative Language Model (MGLM). MGLM is a generative joint distribution model over channels. MGLM marginalizes over all possible factorizations within and across all channels. MGLM endows flexible inference, including unconditional generation, conditional generation (where 1 channel is observed and other channels are generated), and partially observed generation (where incomplete observations are spread across all the channels). We experiment with the Multi30K dataset containing English, French, Czech, and German. We demonstrate experiments with unconditional, conditional, and partially conditional generation. We provide qualitative samples sampled unconditionally from the generative joint distribution. We also quantitatively analyze the quality-diversity trade-offs and find MGLM outperforms traditional bilingual discriminative models.
Contextual Lensing of Universal Sentence Representations
Feb 20, 2020
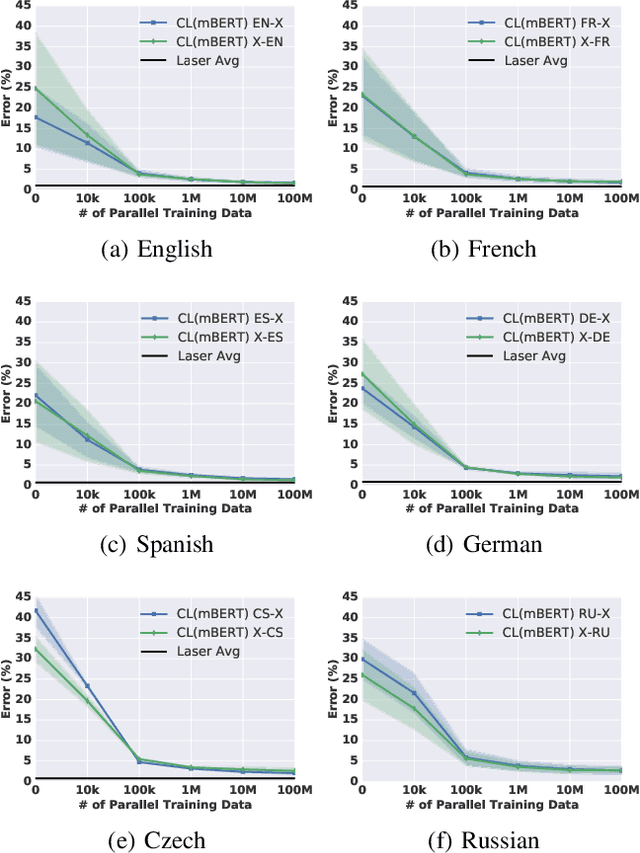
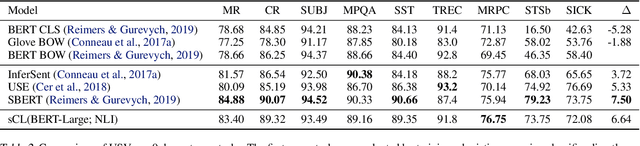

What makes a universal sentence encoder universal? The notion of a generic encoder of text appears to be at odds with the inherent contextualization and non-permanence of language use in a dynamic world. However, mapping sentences into generic fixed-length vectors for downstream similarity and retrieval tasks has been fruitful, particularly for multilingual applications. How do we manage this dilemma? In this work we propose Contextual Lensing, a methodology for inducing context-oriented universal sentence vectors. We break the construction of universal sentence vectors into a core, variable length, sentence matrix representation equipped with an adaptable `lens' from which fixed-length vectors can be induced as a function of the lens context. We show that it is possible to focus notions of language similarity into a small number of lens parameters given a core universal matrix representation. For example, we demonstrate the ability to encode translation similarity of sentences across several languages into a single weight matrix, even when the core encoder has not seen parallel data.
An Empirical Study of Generation Order for Machine Translation
Oct 29, 2019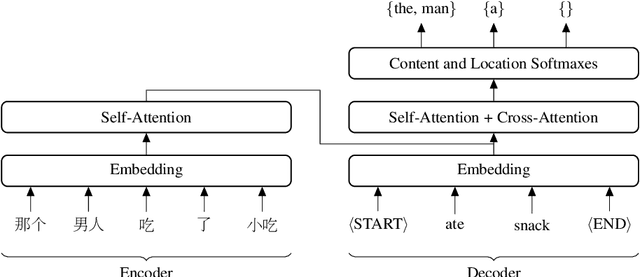


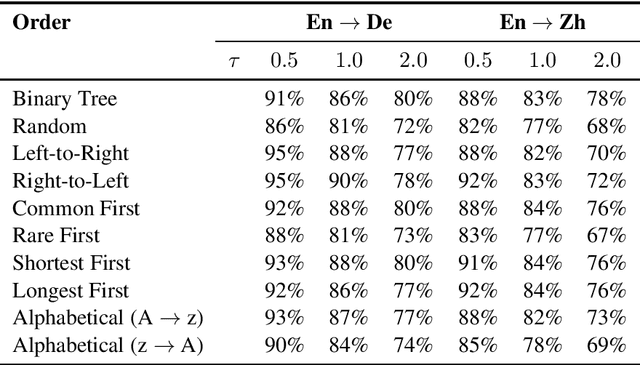
In this work, we present an empirical study of generation order for machine translation. Building on recent advances in insertion-based modeling, we first introduce a soft order-reward framework that enables us to train models to follow arbitrary oracle generation policies. We then make use of this framework to explore a large variety of generation orders, including uninformed orders, location-based orders, frequency-based orders, content-based orders, and model-based orders. Curiously, we find that for the WMT'14 English $\to$ German translation task, order does not have a substantial impact on output quality, with unintuitive orderings such as alphabetical and shortest-first matching the performance of a standard Transformer. This demonstrates that traditional left-to-right generation is not strictly necessary to achieve high performance. On the other hand, results on the WMT'18 English $\to$ Chinese task tend to vary more widely, suggesting that translation for less well-aligned language pairs may be more sensitive to generation order.
Graph Normalizing Flows
May 30, 2019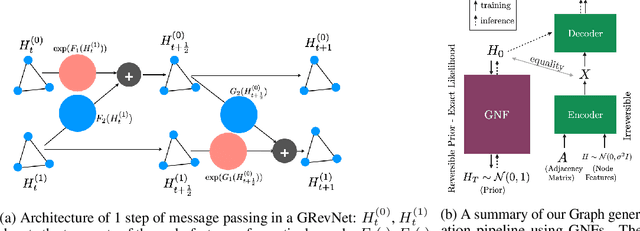
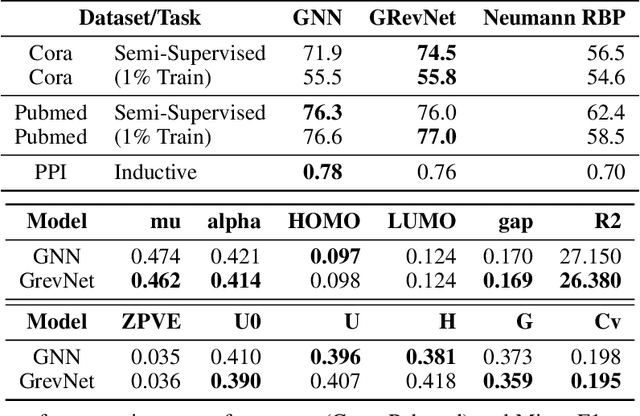

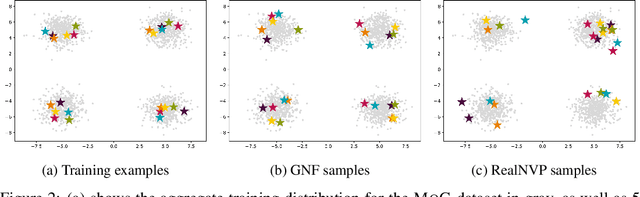
We introduce graph normalizing flows: a new, reversible graph neural network model for prediction and generation. On supervised tasks, graph normalizing flows perform similarly to message passing neural networks, but at a significantly reduced memory footprint, allowing them to scale to larger graphs. In the unsupervised case, we combine graph normalizing flows with a novel graph auto-encoder to create a generative model of graph structures. Our model is permutation-invariant, generating entire graphs with a single feed-forward pass, and achieves competitive results with the state-of-the art auto-regressive models, while being better suited to parallel computing architectures.
DOM-Q-NET: Grounded RL on Structured Language
Feb 19, 2019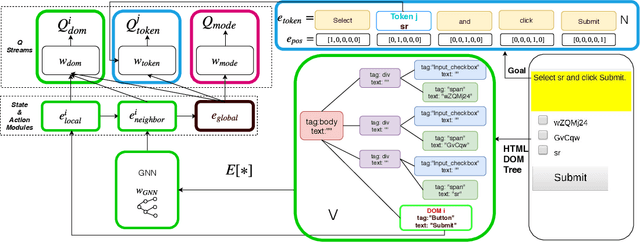
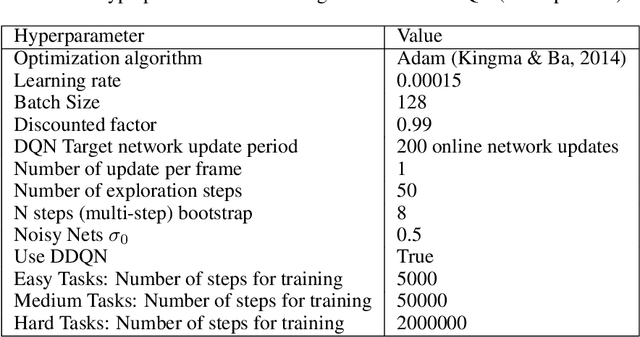
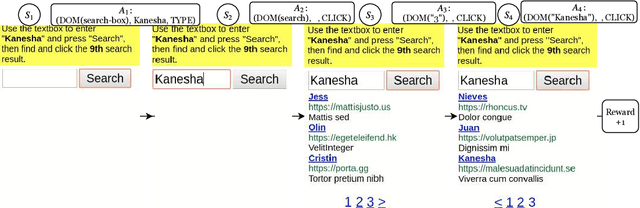
Building agents to interact with the web would allow for significant improvements in knowledge understanding and representation learning. However, web navigation tasks are difficult for current deep reinforcement learning (RL) models due to the large discrete action space and the varying number of actions between the states. In this work, we introduce DOM-Q-NET, a novel architecture for RL-based web navigation to address both of these problems. It parametrizes Q functions with separate networks for different action categories: clicking a DOM element and typing a string input. Our model utilizes a graph neural network to represent the tree-structured HTML of a standard web page. We demonstrate the capabilities of our model on the MiniWoB environment where we can match or outperform existing work without the use of expert demonstrations. Furthermore, we show 2x improvements in sample efficiency when training in the multi-task setting, allowing our model to transfer learned behaviours across tasks.
ACTRCE: Augmenting Experience via Teacher's Advice For Multi-Goal Reinforcement Learning
Feb 12, 2019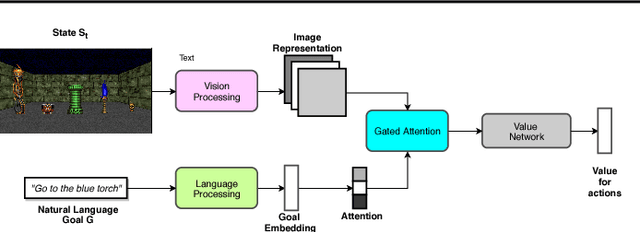
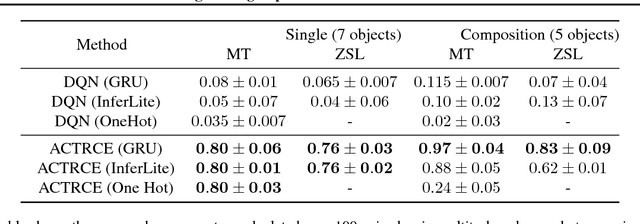
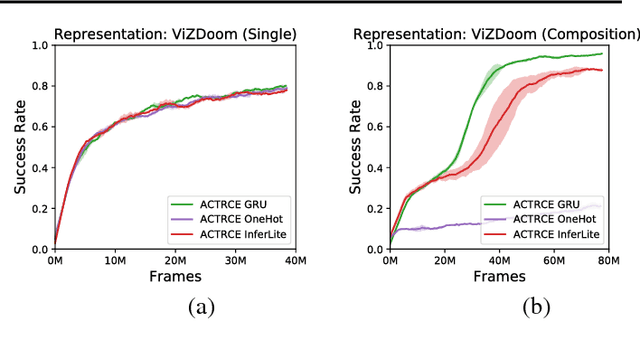

Sparse reward is one of the most challenging problems in reinforcement learning (RL). Hindsight Experience Replay (HER) attempts to address this issue by converting a failed experience to a successful one by relabeling the goals. Despite its effectiveness, HER has limited applicability because it lacks a compact and universal goal representation. We present Augmenting experienCe via TeacheR's adviCE (ACTRCE), an efficient reinforcement learning technique that extends the HER framework using natural language as the goal representation. We first analyze the differences among goal representation, and show that ACTRCE can efficiently solve difficult reinforcement learning problems in challenging 3D navigation tasks, whereas HER with non-language goal representation failed to learn. We also show that with language goal representations, the agent can generalize to unseen instructions, and even generalize to instructions with unseen lexicons. We further demonstrate it is crucial to use hindsight advice to solve challenging tasks, and even small amount of advice is sufficient for the agent to achieve good performance.
Insertion Transformer: Flexible Sequence Generation via Insertion Operations
Feb 08, 2019
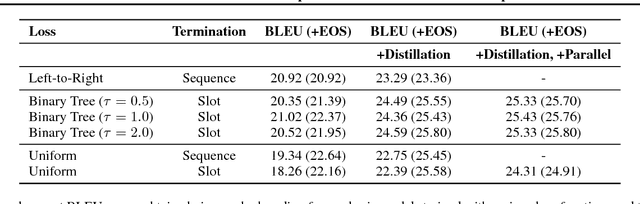
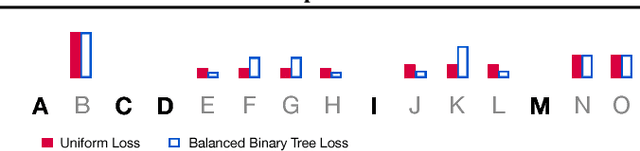
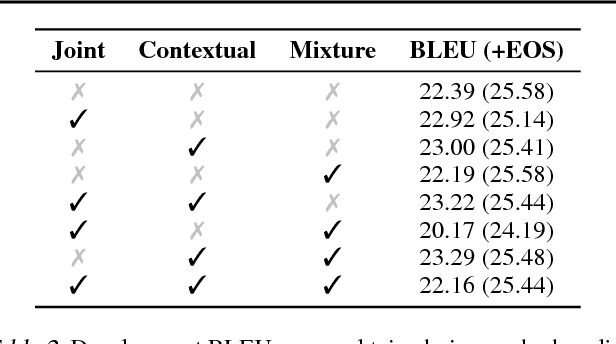
We present the Insertion Transformer, an iterative, partially autoregressive model for sequence generation based on insertion operations. Unlike typical autoregressive models which rely on a fixed, often left-to-right ordering of the output, our approach accommodates arbitrary orderings by allowing for tokens to be inserted anywhere in the sequence during decoding. This flexibility confers a number of advantages: for instance, not only can our model be trained to follow specific orderings such as left-to-right generation or a binary tree traversal, but it can also be trained to maximize entropy over all valid insertions for robustness. In addition, our model seamlessly accommodates both fully autoregressive generation (one insertion at a time) and partially autoregressive generation (simultaneous insertions at multiple locations). We validate our approach by analyzing its performance on the WMT 2014 English-German machine translation task under various settings for training and decoding. We find that the Insertion Transformer outperforms many prior non-autoregressive approaches to translation at comparable or better levels of parallelism, and successfully recovers the performance of the original Transformer while requiring only logarithmically many iterations during decoding.