 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMYRF: Efficient Attention using Asymmetric Clustering
Oct 11, 2020
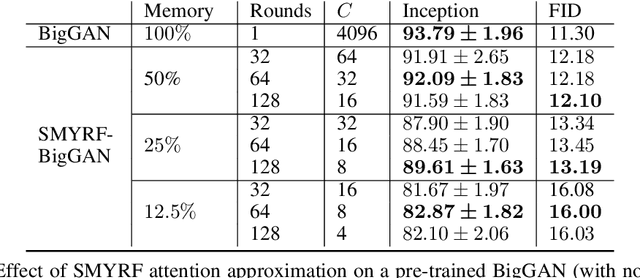


We propose a novel type of balanced clustering algorithm to approximate attention. Attention complexity is reduced from $O(N^2)$ to $O(N \log N)$, where $N$ is the sequence length. Our algorithm, SMYRF, uses Locality Sensitive Hashing (LSH) in a novel way by defining new Asymmetric transformations and an adaptive scheme that produces balanced clusters. The biggest advantage of SMYRF is that it can be used as a drop-in replacement for dense attention layers without any retraining. On the contrary, prior fast attention methods impose constraints (e.g. queries and keys share the same vector representations) and require re-training from scratch. We apply our method to pre-trained state-of-the-art Natural Language Processing and Computer Vision models and we report significant memory and speed benefits. Notably, SMYRF-BERT outperforms (slightly) BERT on GLUE, while using $50\%$ less memory. We also show that SMYRF can be used interchangeably with dense attention before and after training. Finally, we use SMYRF to train GANs with attention in high resolutions. Using a single TPU, we were able to scale attention to 128x128=16k and 256x256=65k tokens on BigGAN on CelebA-HQ.
Unsupervised Parsing via Constituency Tests
Oct 07, 2020
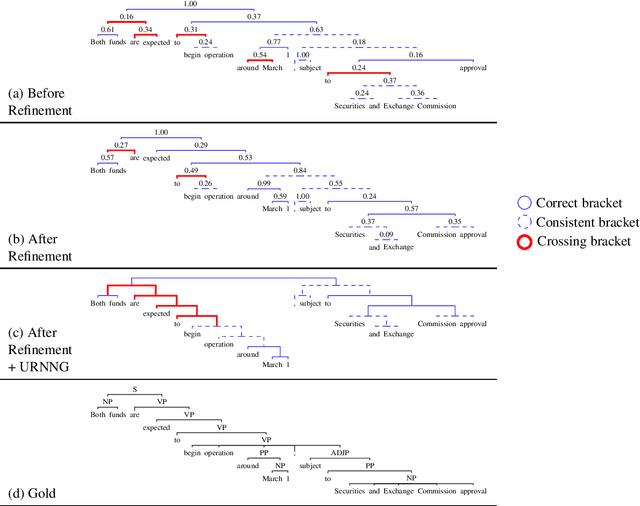

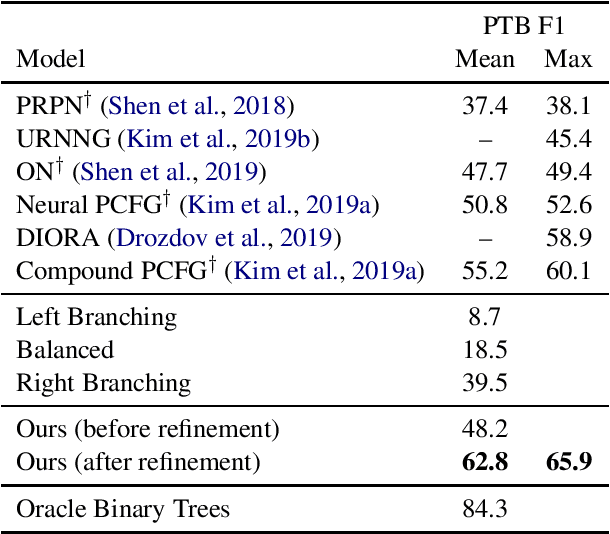
We propose a method for unsupervised parsing based on the linguistic notion of a constituency test. One type of constituency test involves modifying the sentence via some transformation (e.g. replacing the span with a pronoun) and then judging the result (e.g. checking if it is grammatical). Motivated by this idea, we design an unsupervised parser by specifying a set of transformations and using an unsupervised neural acceptability model to make grammaticality decisions. To produce a tree given a sentence, we score each span by aggregating its constituency test judgments, and we choose the binary tree with the highest total score. While this approach already achieves performance in the range of current methods, we further improve accuracy by fine-tuning the grammaticality model through a refinement procedure, where we alternate between improving the estimated trees and improving the grammaticality model. The refined model achieves 62.8 F1 on the Penn Treebank test set, an absolute improvement of 7.6 points over the previous best published result.
Reformer: The Efficient Transformer
Feb 18, 2020
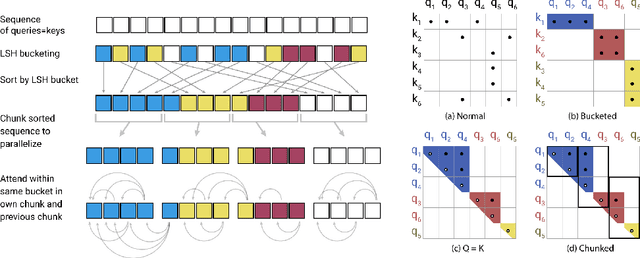
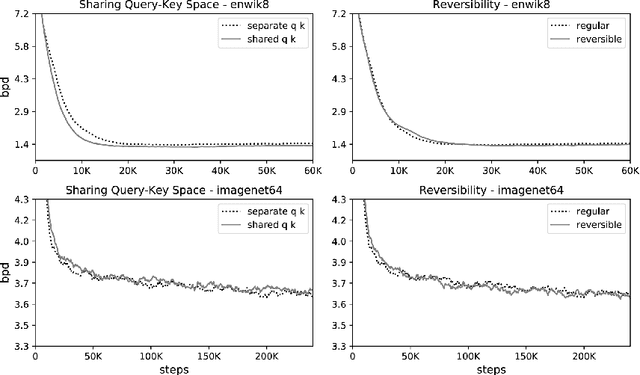
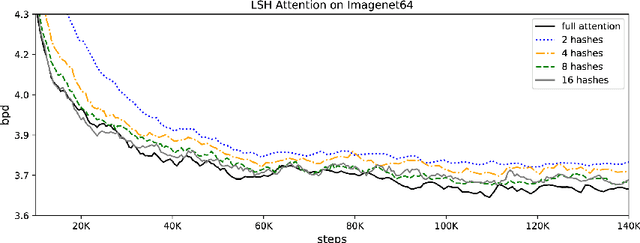
Large Transformer models routinely achieve state-of-the-art results on a number of tasks but training these models can be prohibitively costly, especially on long sequences. We introduce two techniques to improve the efficiency of Transformers. For one, we replace dot-product attention by one that uses locality-sensitive hashing, changing its complexity from O($L^2$) to O($L\log L$), where $L$ is the length of the sequence. Furthermore, we use reversible residual layers instead of the standard residuals, which allows storing activations only once in the training process instead of $N$ times, where $N$ is the number of layers. The resulting model, the Reformer, performs on par with Transformer models while being much more memory-efficient and much faster on long sequences.
Multilingual Alignment of Contextual Word Representations
Feb 12, 2020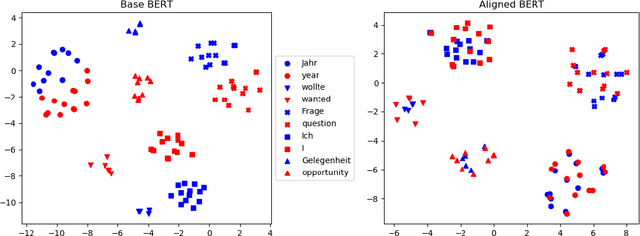
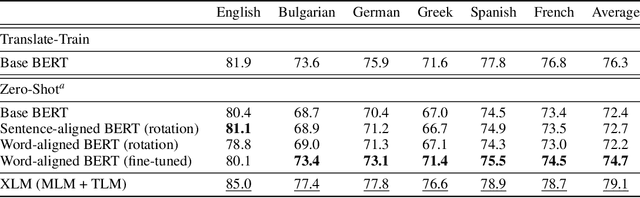
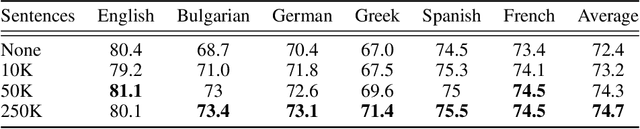
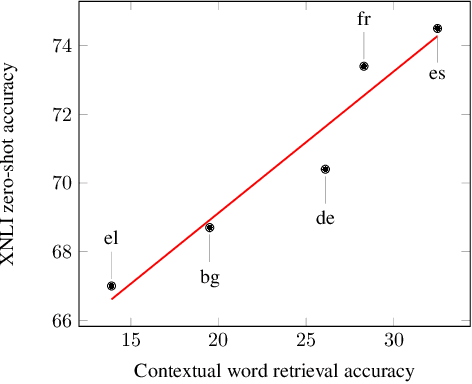
We propose procedures for evaluating and strengthening contextual embedding alignment and show that they are useful in analyzing and improving multilingual BERT. In particular, after our proposed alignment procedure, BERT exhibits significantly improved zero-shot performance on XNLI compared to the base model, remarkably matching pseudo-fully-supervised translate-train models for Bulgarian and Greek. Further, to measure the degree of alignment, we introduce a contextual version of word retrieval and show that it correlates well with downstream zero-shot transfer. Using this word retrieval task, we also analyze BERT and find that it exhibits systematic deficiencies, e.g. worse alignment for open-class parts-of-speech and word pairs written in different scripts, that are corrected by the alignment procedure. These results support contextual alignment as a useful concept for understanding large multilingual pre-trained models.
Cross-Domain Generalization of Neural Constituency Parsers
Jul 09, 2019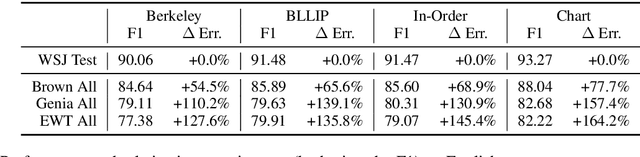
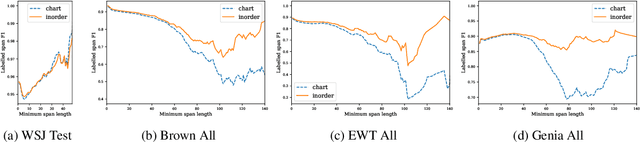
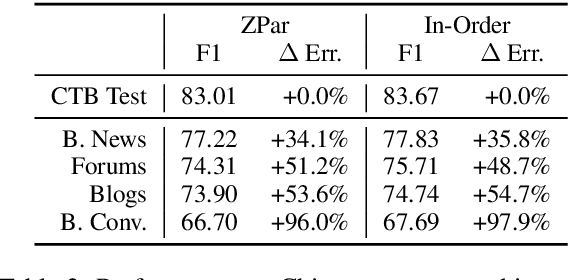
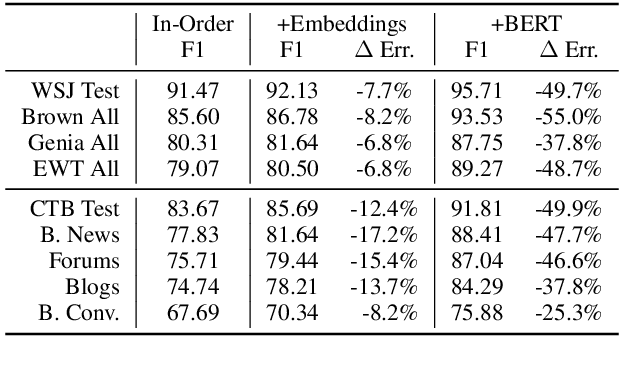
Neural parsers obtain state-of-the-art results on benchmark treebanks for constituency parsing -- but to what degree do they generalize to other domains? We present three results about the generalization of neural parsers in a zero-shot setting: training on trees from one corpus and evaluating on out-of-domain corpora. First, neural and non-neural parsers generalize comparably to new domains. Second, incorporating pre-trained encoder representations into neural parsers substantially improves their performance across all domains, but does not give a larger relative improvement for out-of-domain treebanks. Finally, despite the rich input representations they learn, neural parsers still benefit from structured output prediction of output trees, yielding higher exact match accuracy and stronger generalization both to larger text spans and to out-of-domain corpora. We analyze generalization on English and Chinese corpora, and in the process obtain state-of-the-art parsing results for the Brown, Genia, and English Web treebanks.
KERMIT: Generative Insertion-Based Modeling for Sequences
Jun 04, 2019

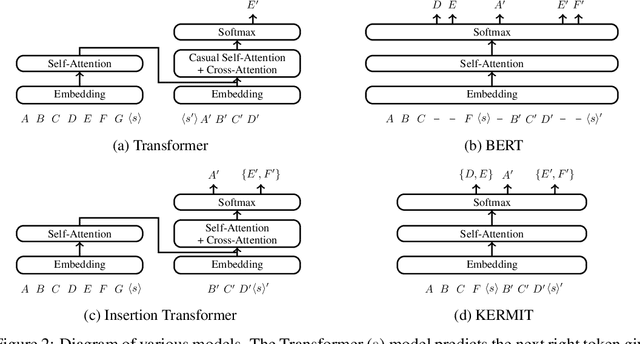
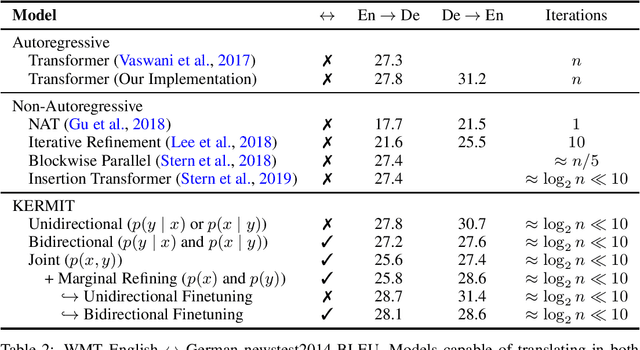
We present KERMIT, a simple insertion-based approach to generative modeling for sequences and sequence pairs. KERMIT models the joint distribution and its decompositions (i.e., marginals and conditionals) using a single neural network and, unlike much prior work, does not rely on a prespecified factorization of the data distribution. During training, one can feed KERMIT paired data $(x, y)$ to learn the joint distribution $p(x, y)$, and optionally mix in unpaired data $x$ or $y$ to refine the marginals $p(x)$ or $p(y)$. During inference, we have access to the conditionals $p(x \mid y)$ and $p(y \mid x)$ in both directions. We can also sample from the joint distribution or the marginals. The model supports both serial fully autoregressive decoding and parallel partially autoregressive decoding, with the latter exhibiting an empirically logarithmic runtime. We demonstrate through experiments in machine translation, representation learning, and zero-shot cloze question answering that our unified approach is capable of matching or exceeding the performance of dedicated state-of-the-art systems across a wide range of tasks without the need for problem-specific architectural adaptation.
Tetra-Tagging: Word-Synchronous Parsing with Linear-Time Inference
Apr 22, 2019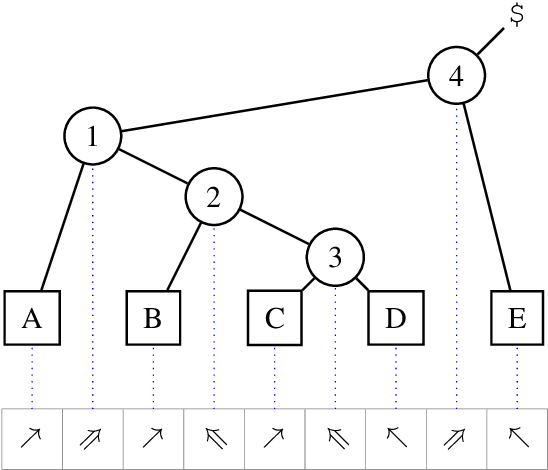

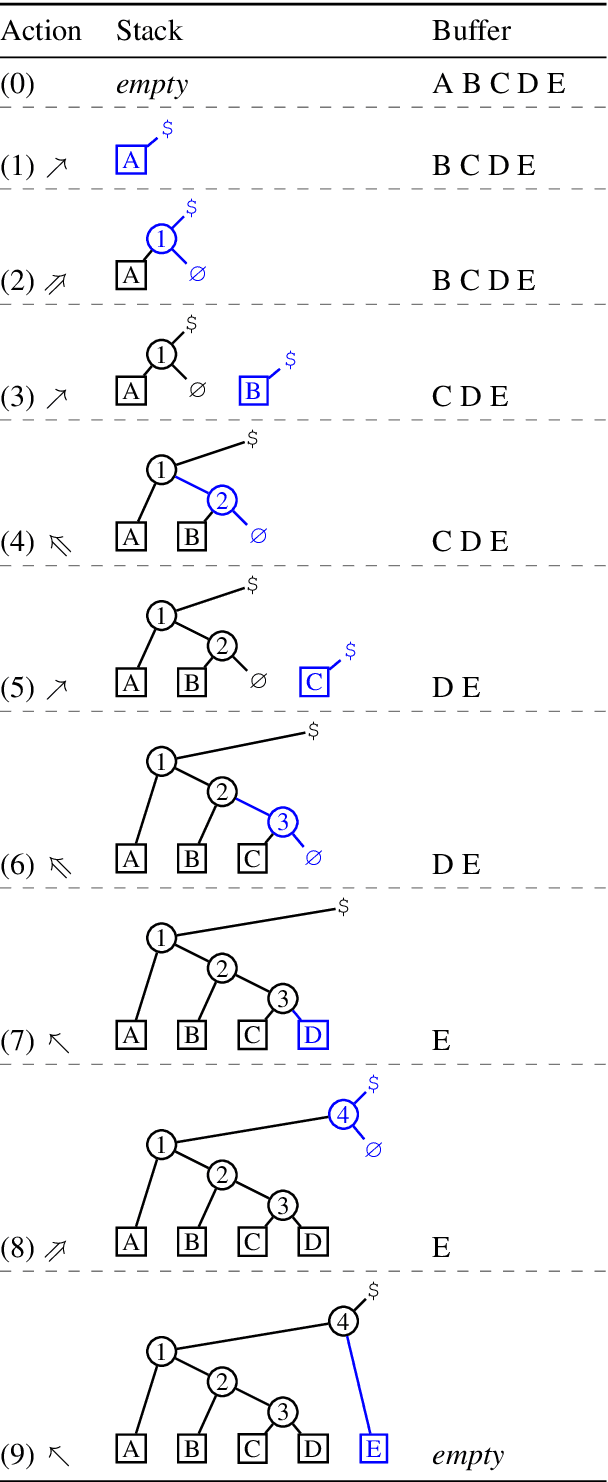
We present a constituency parsing algorithm that maps from word-aligned contextualized feature vectors to parse trees. Our algorithm proceeds strictly left-to-right, processing one word at a time by assigning it a label from a small vocabulary. We show that, with mild assumptions, our inference procedure requires constant computation time per word. Our method gets 95.4 F1 on the WSJ test set.
Multilingual Constituency Parsing with Self-Attention and Pre-Training
Dec 31, 2018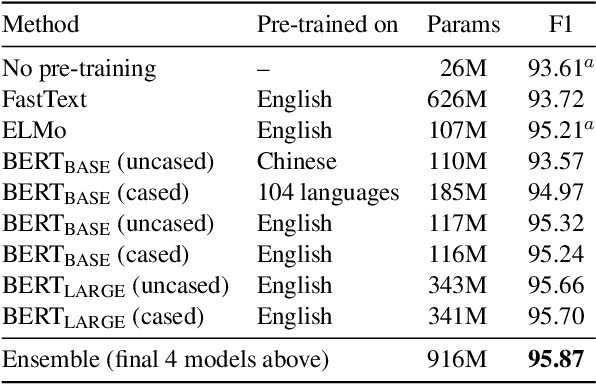
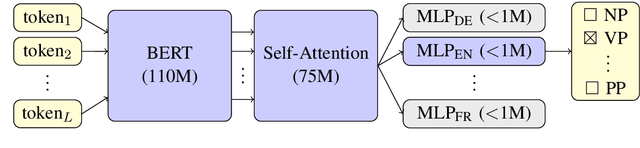

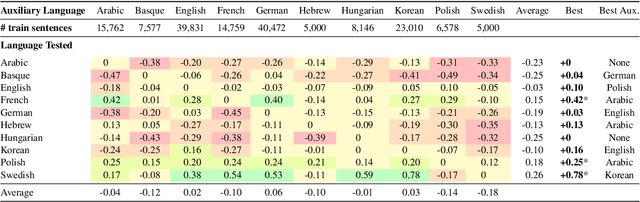
We extend our previous work on constituency parsing (Kitaev and Klein, 2018) by incorporating pre-training for ten additional languages, and compare the benefits of no pre-training, ELMo (Peters et al., 2018), and BERT (Devlin et al., 2018). Pre-training is effective across all languages evaluated, and BERT outperforms ELMo in large part due to the benefits of increased model capacity. Our parser obtains new state-of-the-art results for 11 languages, including English (95.8 F1) and Chinese (91.8 F1).
Constituency Parsing with a Self-Attentive Encoder
May 02, 2018
We demonstrate that replacing an LSTM encoder with a self-attentive architecture can lead to improvements to a state-of-the-art discriminative constituency parser. The use of attention makes explicit the manner in which information is propagated between different locations in the sentence, which we use to both analyze our model and propose potential improvements. For example, we find that separating positional and content information in the encoder can lead to improved parsing accuracy. Additionally, we evaluate different approaches for lexical representation. Our parser achieves new state-of-the-art results for single models trained on the Penn Treebank: 93.55 F1 without the use of any external data, and 95.13 F1 when using pre-trained word representations. Our parser also outperforms the previous best-published accuracy figures on 8 of the 9 languages in the SPMRL dataset.