Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Constituency Parsing with Self-Attention and Pre-Training
Paper and Code
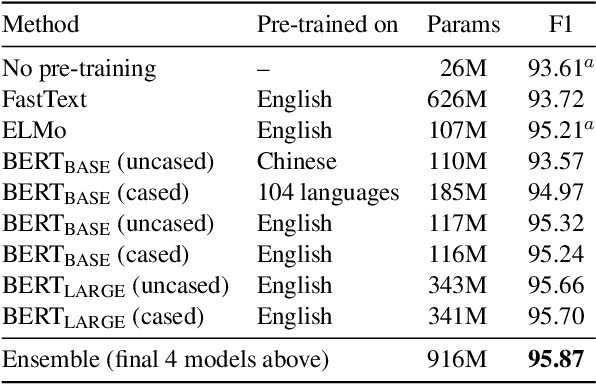
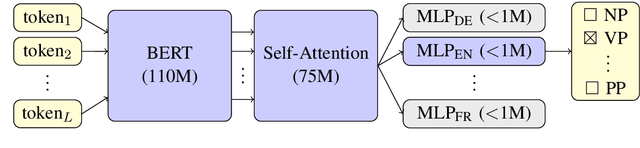

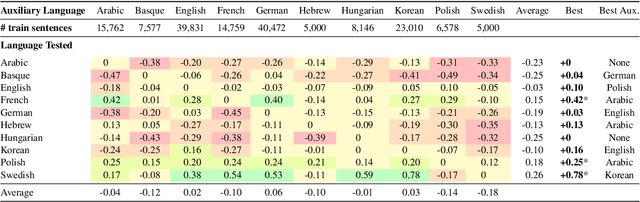
We extend our previous work on constituency parsing (Kitaev and Klein, 2018) by incorporating pre-training for ten additional languages, and compare the benefits of no pre-training, ELMo (Peters et al., 2018), and BERT (Devlin et al., 2018). Pre-training is effective across all languages evaluated, and BERT outperforms ELMo in large part due to the benefits of increased model capacity. Our parser obtains new state-of-the-art results for 11 languages, including English (95.8 F1) and Chinese (91.8 F1).
View paper on