 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Document-Level Translation Enables Zero-Shot Transfer From Sentences to Documents
Paper and Code
Sep 21, 2021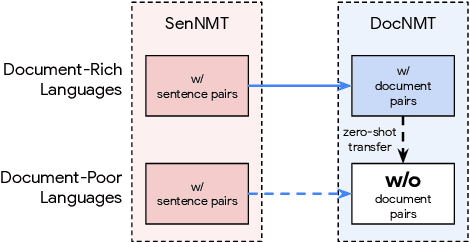

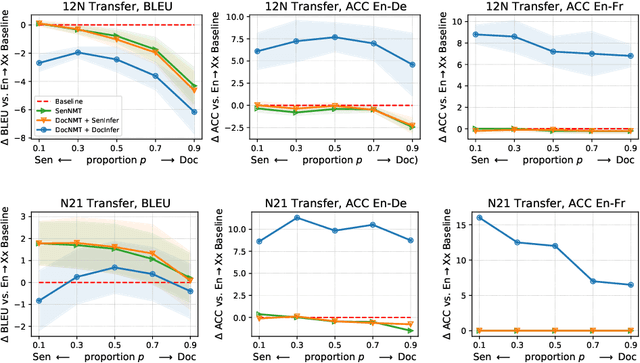
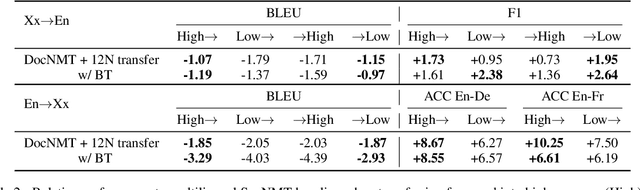
Document-level neural machine translation (DocNMT) delivers coherent translations by incorporating cross-sentence context. However, for most language pairs there's a shortage of parallel documents, although parallel sentences are readily available. In this paper, we study whether and how contextual modeling in DocNMT is transferable from sentences to documents in a zero-shot fashion (i.e. no parallel documents for student languages) through multilingual modeling. Using simple concatenation-based DocNMT, we explore the effect of 3 factors on multilingual transfer: the number of document-supervised teacher languages, the data schedule for parallel documents at training, and the data condition of parallel documents (genuine vs. backtranslated). Our experiments on Europarl-7 and IWSLT-10 datasets show the feasibility of multilingual transfer for DocNMT, particularly on document-specific metrics. We observe that more teacher languages and adequate data schedule both contribute to better transfer quality. Surprisingly, the transfer is less sensitive to the data condition and multilingual DocNMT achieves comparable performance with both back-translated and genuine document pairs.