 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying the Better Performance of Position Encoding Variants for Transformer
Apr 18, 2021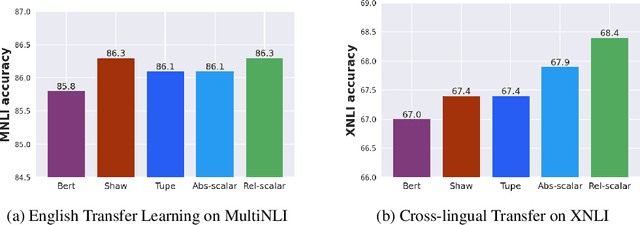

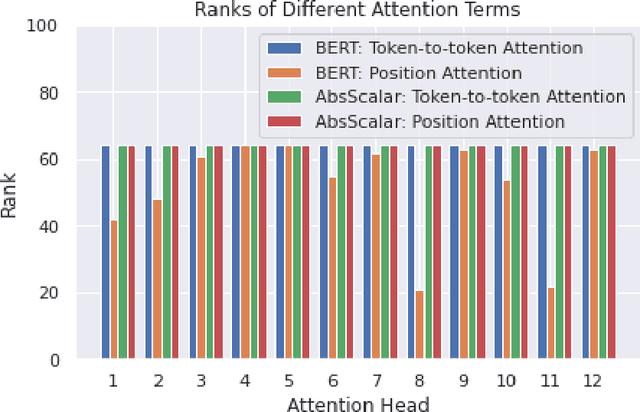

Transformers are state of the art models in NLP that map a given input sequence of vectors to an output sequence of vectors. However these models are permutation equivariant, and additive position embeddings to the input are used to supply the information about the order of the input tokens. Further, for some tasks, additional additive segment embeddings are used to denote different types of input sentences. Recent works proposed variations of positional encodings with relative position encodings achieving better performance. In this work, we do a systematic study comparing different position encodings and understanding the reasons for differences in their performance. We demonstrate a simple yet effective way to encode position and segment into the Transformer models. The proposed method performs on par with SOTA on GLUE, XTREME and WMT benchmarks while saving computation costs.
Rethinking embedding coupling in pre-trained language models
Oct 24, 2020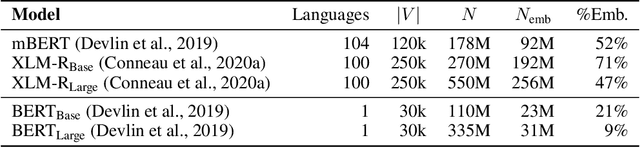
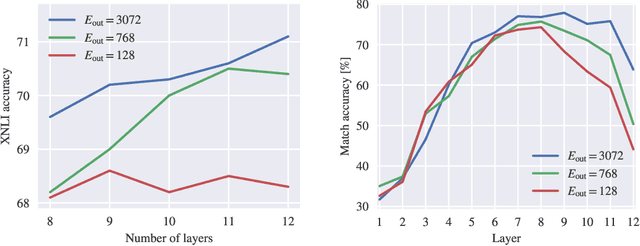


We re-evaluate the standard practice of sharing weights between input and output embeddings in state-of-the-art pre-trained language models. We show that decoupled embeddings provide increased modeling flexibility, allowing us to significantly improve the efficiency of parameter allocation in the input embedding of multilingual models. By reallocating the input embedding parameters in the Transformer layers, we achieve dramatically better performance on standard natural language understanding tasks with the same number of parameters during fine-tuning. We also show that allocating additional capacity to the output embedding provides benefits to the model that persist through the fine-tuning stage even though the output embedding is discarded after pre-training. Our analysis shows that larger output embeddings prevent the model's last layers from overspecializing to the pre-training task and encourage Transformer representations to be more general and more transferable to other tasks and languages. Harnessing these findings, we are able to train models that achieve strong performance on the XTREME benchmark without increasing the number of parameters at the fine-tuning stage.
Finding Fast Transformers: One-Shot Neural Architecture Search by Component Composition
Aug 15, 2020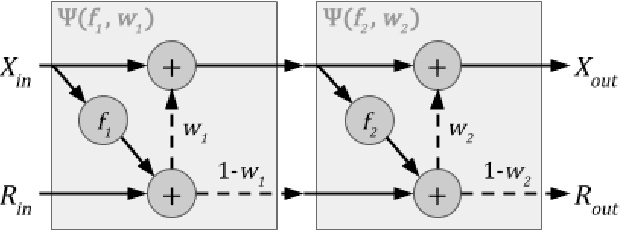
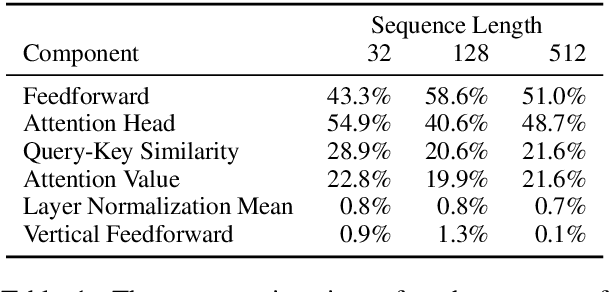
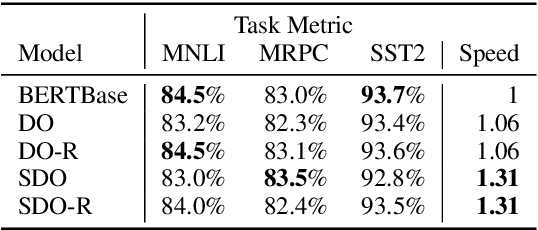
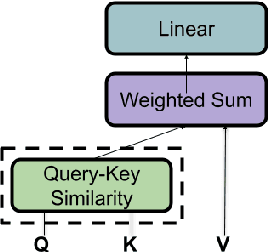
Transformer-based models have achieved stateof-the-art results in many tasks in natural language processing. However, such models are usually slow at inference time, making deployment difficult. In this paper, we develop an efficient algorithm to search for fast models while maintaining model quality. We describe a novel approach to decompose the Transformer architecture into smaller components, and propose a sampling-based one-shot architecture search method to find an optimal model for inference. The model search process is more efficient than alternatives, adding only a small overhead to training time. By applying our methods to BERT-base architectures, we achieve 10% to 30% speedup for pre-trained BERT and 70% speedup on top of a previous state-of-the-art distilled BERT model on Cloud TPU-v2 with a generally acceptable drop in performance.
Evaluating the Cross-Lingual Effectiveness of Massively Multilingual Neural Machine Translation
Sep 01, 2019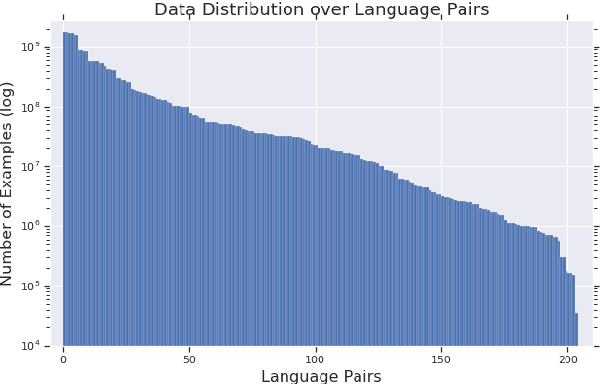
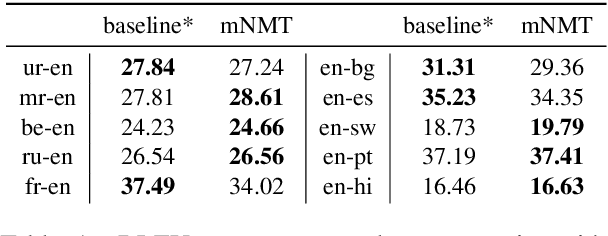
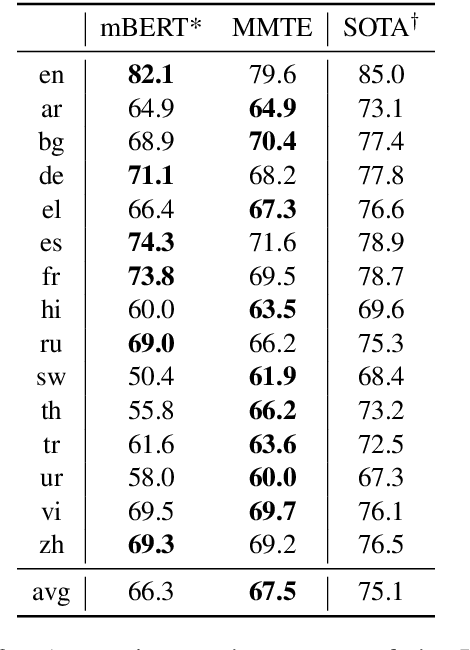
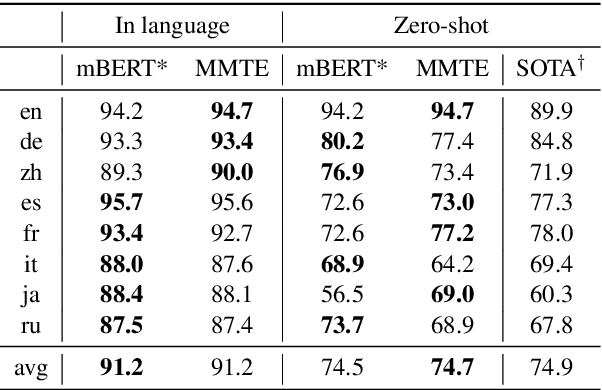
The recently proposed massively multilingual neural machine translation (NMT) system has been shown to be capable of translating over 100 languages to and from English within a single model. Its improved translation performance on low resource languages hints at potential cross-lingual transfer capability for downstream tasks. In this paper, we evaluate the cross-lingual effectiveness of representations from the encoder of a massively multilingual NMT model on 5 downstream classification and sequence labeling tasks covering a diverse set of over 50 languages. We compare against a strong baseline, multilingual BERT (mBERT), in different cross-lingual transfer learning scenarios and show gains in zero-shot transfer in 4 out of these 5 tasks.
Small and Practical BERT Models for Sequence Labeling
Aug 31, 2019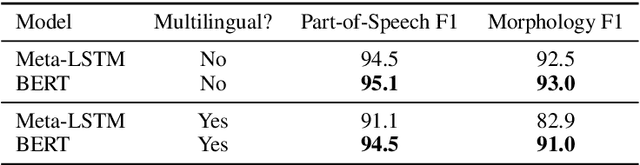
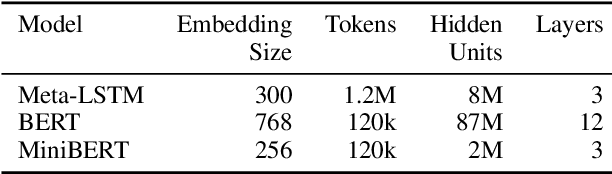


We propose a practical scheme to train a single multilingual sequence labeling model that yields state of the art results and is small and fast enough to run on a single CPU. Starting from a public multilingual BERT checkpoint, our final model is 6x smaller and 27x faster, and has higher accuracy than a state-of-the-art multilingual baseline. We show that our model especially outperforms on low-resource languages, and works on codemixed input text without being explicitly trained on codemixed examples. We showcase the effectiveness of our method by reporting on part-of-speech tagging and morphological prediction on 70 treebanks and 48 languages.