 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking embedding coupling in pre-trained language models
Oct 24, 2020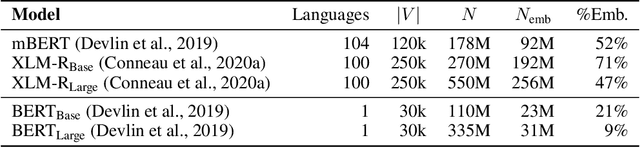
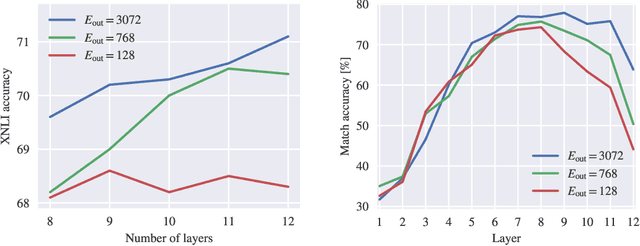


We re-evaluate the standard practice of sharing weights between input and output embeddings in state-of-the-art pre-trained language models. We show that decoupled embeddings provide increased modeling flexibility, allowing us to significantly improve the efficiency of parameter allocation in the input embedding of multilingual models. By reallocating the input embedding parameters in the Transformer layers, we achieve dramatically better performance on standard natural language understanding tasks with the same number of parameters during fine-tuning. We also show that allocating additional capacity to the output embedding provides benefits to the model that persist through the fine-tuning stage even though the output embedding is discarded after pre-training. Our analysis shows that larger output embeddings prevent the model's last layers from overspecializing to the pre-training task and encourage Transformer representations to be more general and more transferable to other tasks and languages. Harnessing these findings, we are able to train models that achieve strong performance on the XTREME benchmark without increasing the number of parameters at the fine-tuning stage.
Empirical Evaluation of Pretraining Strategies for Supervised Entity Linking
May 28, 2020
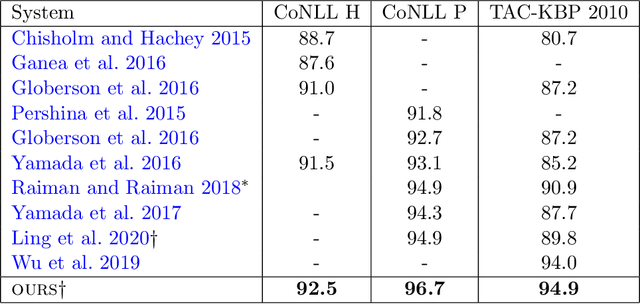

In this work, we present an entity linking model which combines a Transformer architecture with large scale pretraining from Wikipedia links. Our model achieves the state-of-the-art on two commonly used entity linking datasets: 96.7% on CoNLL and 94.9% on TAC-KBP. We present detailed analyses to understand what design choices are important for entity linking, including choices of negative entity candidates, Transformer architecture, and input perturbations. Lastly, we present promising results on more challenging settings such as end-to-end entity linking and entity linking without in-domain training data.
Entities as Experts: Sparse Memory Access with Entity Supervision
Apr 15, 2020
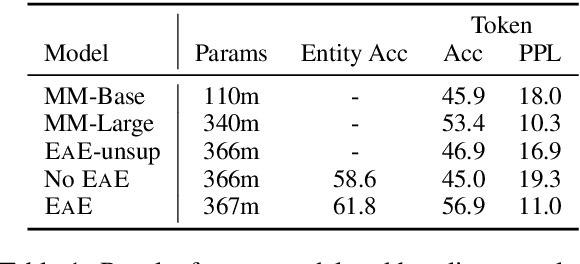
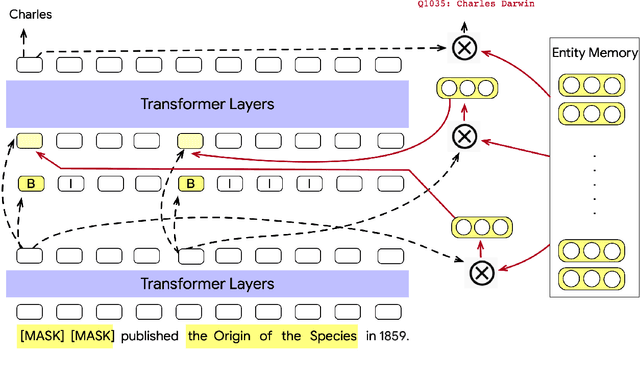
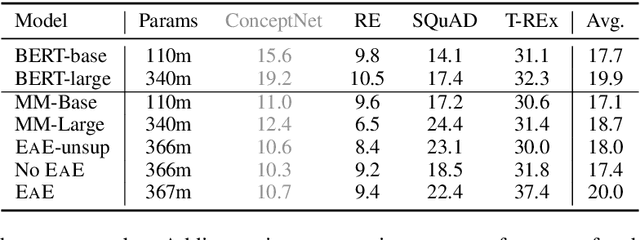
We focus on the problem of capturing declarative knowledge in the learned parameters of a language model. We introduce a new model, Entities as Experts (EaE), that can access distinct memories of the entities mentioned in a piece of text. Unlike previous efforts to integrate entity knowledge into sequence models, EaE's entity representations are learned directly from text. These representations capture sufficient knowledge to answer TriviaQA questions such as "Which Dr. Who villain has been played by Roger Delgado, Anthony Ainley, Eric Roberts?". EaE outperforms a Transformer model with $30\times$ the parameters on this task. According to the Lama knowledge probes, EaE also contains more factual knowledge than a similar sized Bert. We show that associating parameters with specific entities means that EaE only needs to access a fraction of its parameters at inference time, and we show that the correct identification, and representation, of entities is essential to EaE's performance. We also argue that the discrete and independent entity representations in EaE make it more modular and interpretable than the Transformer architecture on which it is based.
Learning Cross-Context Entity Representations from Text
Jan 11, 2020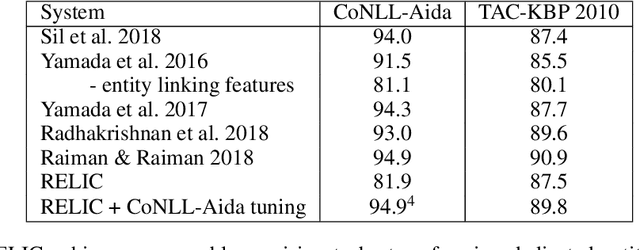
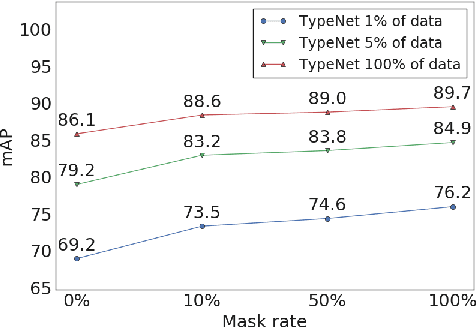

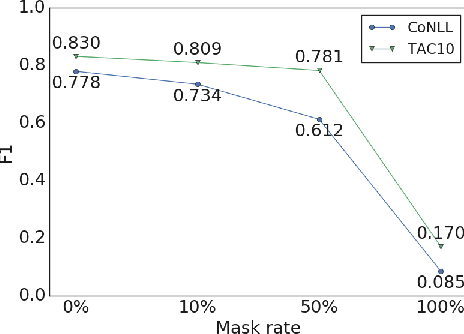
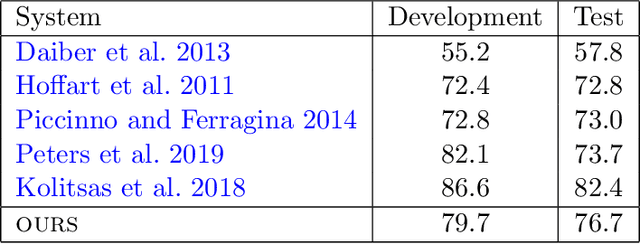
Language modeling tasks, in which words, or word-pieces, are predicted on the basis of a local context, have been very effective for learning word embeddings and context dependent representations of phrases. Motivated by the observation that efforts to code world knowledge into machine readable knowledge bases or human readable encyclopedias tend to be entity-centric, we investigate the use of a fill-in-the-blank task to learn context independent representations of entities from the text contexts in which those entities were mentioned. We show that large scale training of neural models allows us to learn high quality entity representations, and we demonstrate successful results on four domains: (1) existing entity-level typing benchmarks, including a 64% error reduction over previous work on TypeNet (Murty et al., 2018); (2) a novel few-shot category reconstruction task; (3) existing entity linking benchmarks, where we match the state-of-the-art on CoNLL-Aida without linking-specific features and obtain a score of 89.8% on TAC-KBP 2010 without using any alias table, external knowledge base or in domain training data and (4) answering trivia questions, which uniquely identify entities. Our global entity representations encode fine-grained type categories, such as Scottish footballers, and can answer trivia questions such as: Who was the last inmate of Spandau jail in Berlin?
Improving localization-based approaches for breast cancer screening exam classification
Aug 01, 2019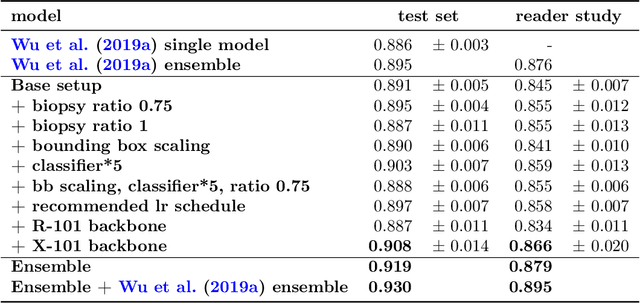
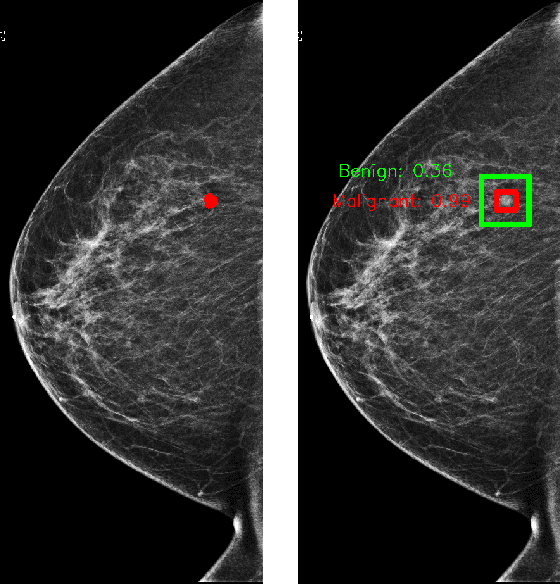
We trained and evaluated a localization-based deep CNN for breast cancer screening exam classification on over 200,000 exams (over 1,000,000 images). Our model achieves an AUC of 0.919 in predicting malignancy in patients undergoing breast cancer screening, reducing the error rate of the baseline (Wu et al., 2019a) by 23%. In addition, the models generates bounding boxes for benign and malignant findings, providing interpretable predictions.
Deep Neural Networks Improve Radiologists' Performance in Breast Cancer Screening
Mar 20, 2019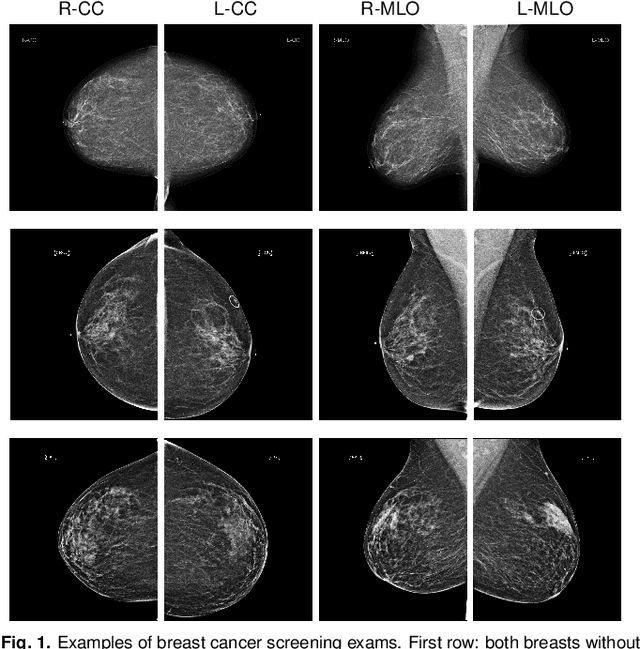
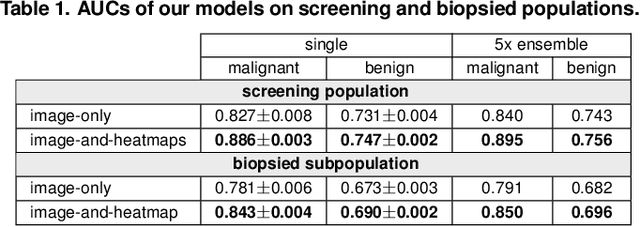
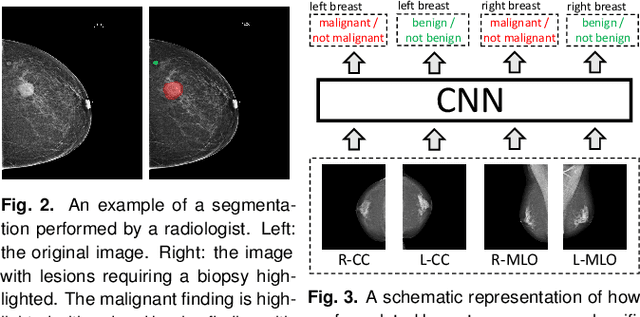
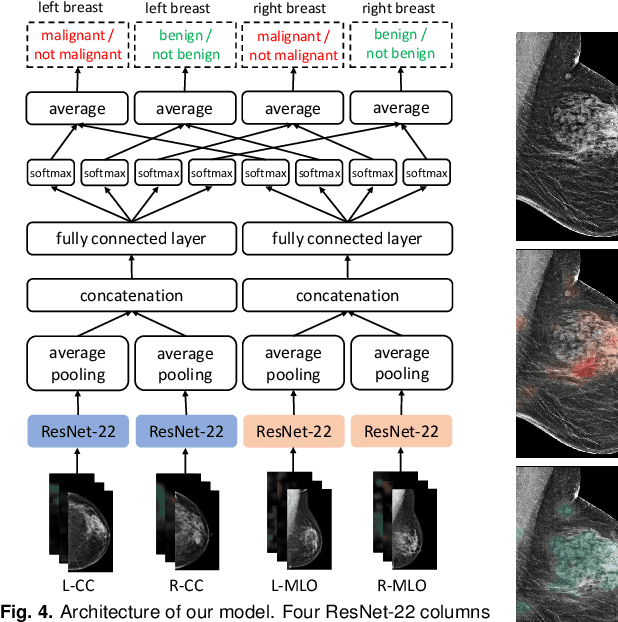
We present a deep convolutional neural network for breast cancer screening exam classification, trained and evaluated on over 200,000 exams (over 1,000,000 images). Our network achieves an AUC of 0.895 in predicting whether there is a cancer in the breast, when tested on the screening population. We attribute the high accuracy of our model to a two-stage training procedure, which allows us to use a very high-capacity patch-level network to learn from pixel-level labels alongside a network learning from macroscopic breast-level labels. To validate our model, we conducted a reader study with 14 readers, each reading 720 screening mammogram exams, and find our model to be as accurate as experienced radiologists when presented with the same data. Finally, we show that a hybrid model, averaging probability of malignancy predicted by a radiologist with a prediction of our neural network, is more accurate than either of the two separately. To better understand our results, we conduct a thorough analysis of our network's performance on different subpopulations of the screening population, model design, training procedure, errors, and properties of its internal representations.
Sentence Encoders on STILTs: Supplementary Training on Intermediate Labeled-data Tasks
Nov 02, 2018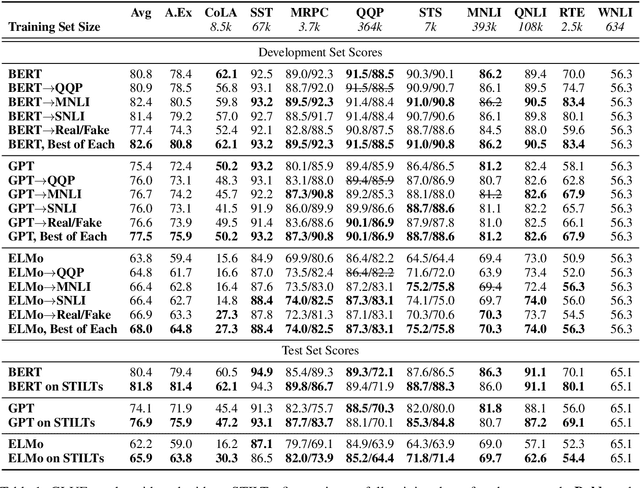
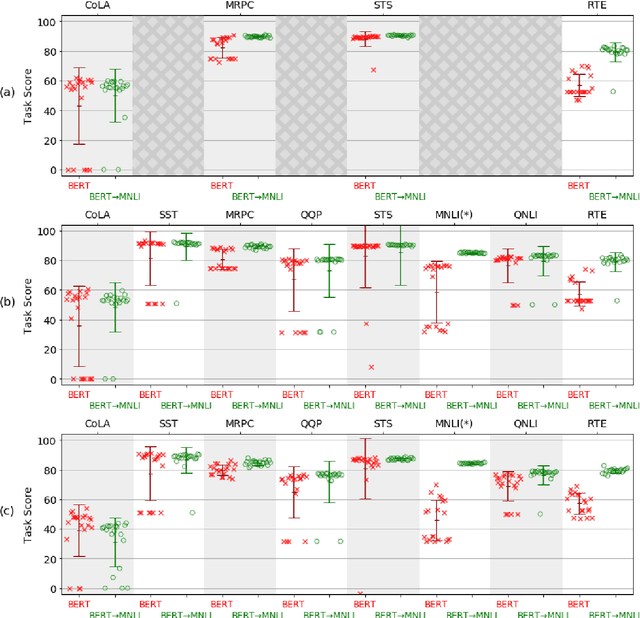
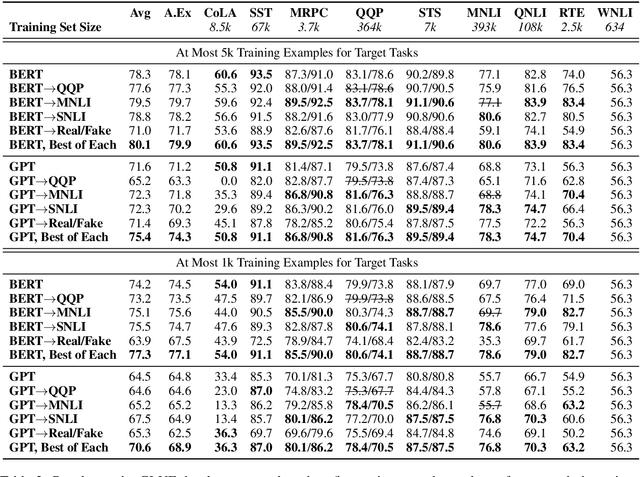
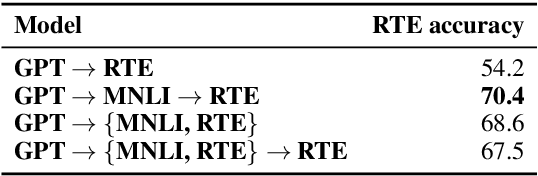
Pretraining with language modeling and related unsupervised tasks has recently been shown to be a very effective enabling technology for the development of neural network models for language understanding tasks. In this work, we show that although language model-style pretraining is extremely effective at teaching models about language, it does not yield an ideal starting point for efficient transfer learning. By supplementing language model-style pretraining with further training on data-rich supervised tasks, we are able to achieve substantial additional performance improvements across the nine target tasks in the GLUE benchmark. We obtain an overall score of 76.9 on GLUE--a 2.3 point improvement over our baseline system adapted from Radford et al. (2018) and a 4.1 point improvement over Radford et al.'s reported score. We further use training data downsampling to show that the benefits of this supplementary training are even more pronounced in data-constrained regimes.
Unsupervised Sentence Compression using Denoising Auto-Encoders
Sep 07, 2018



In sentence compression, the task of shortening sentences while retaining the original meaning, models tend to be trained on large corpora containing pairs of verbose and compressed sentences. To remove the need for paired corpora, we emulate a summarization task and add noise to extend sentences and train a denoising auto-encoder to recover the original, constructing an end-to-end training regime without the need for any examples of compressed sentences. We conduct a human evaluation of our model on a standard text summarization dataset and show that it performs comparably to a supervised baseline based on grammatical correctness and retention of meaning. Despite being exposed to no target data, our unsupervised models learn to generate imperfect but reasonably readable sentence summaries. Although we underperform supervised models based on ROUGE scores, our models are competitive with a supervised baseline based on human evaluation for grammatical correctness and retention of meaning.