 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing false-positive biopsies with deep neural networks that utilize local and global information in screening mammograms
Sep 19, 2020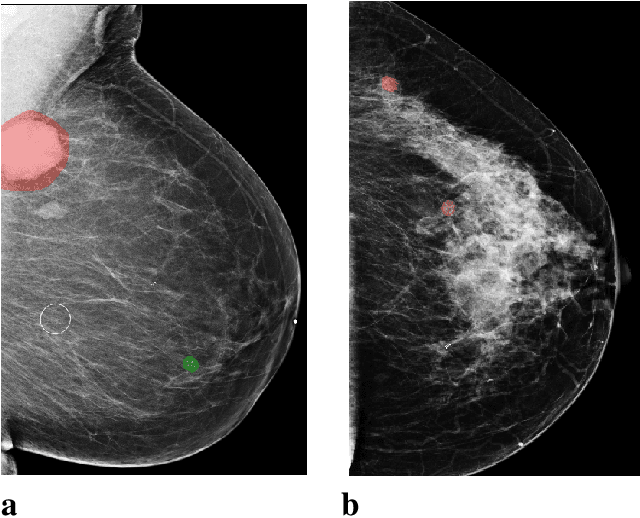
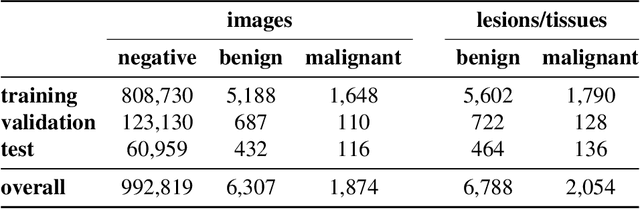
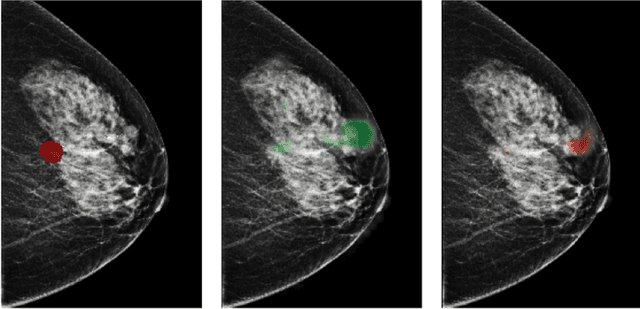
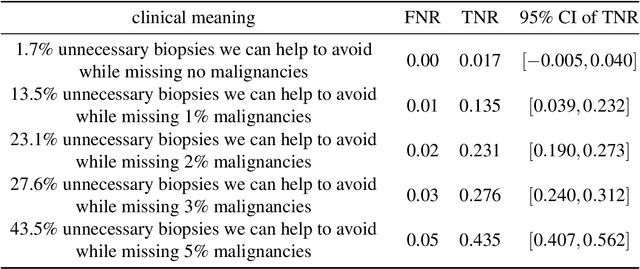
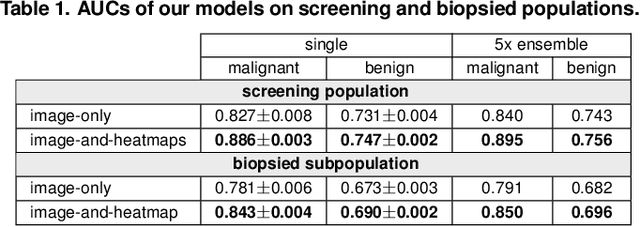
Breast cancer is the most common cancer in women, and hundreds of thousands of unnecessary biopsies are done around the world at a tremendous cost. It is crucial to reduce the rate of biopsies that turn out to be benign tissue. In this study, we build deep neural networks (DNNs) to classify biopsied lesions as being either malignant or benign, with the goal of using these networks as second readers serving radiologists to further reduce the number of false positive findings. We enhance the performance of DNNs that are trained to learn from small image patches by integrating global context provided in the form of saliency maps learned from the entire image into their reasoning, similar to how radiologists consider global context when evaluating areas of interest. Our experiments are conducted on a dataset of 229,426 screening mammography exams from 141,473 patients. We achieve an AUC of 0.8 on a test set consisting of 464 benign and 136 malignant lesions.
An interpretable classifier for high-resolution breast cancer screening images utilizing weakly supervised localization
Feb 13, 2020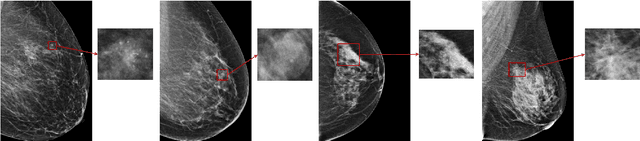
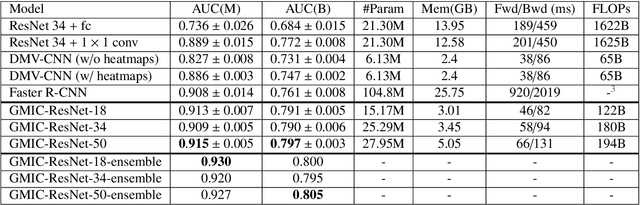
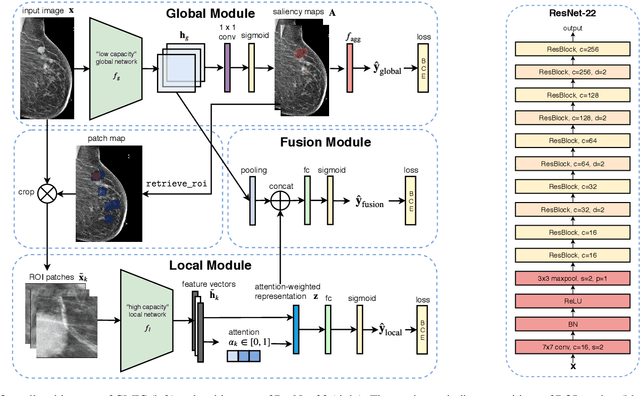
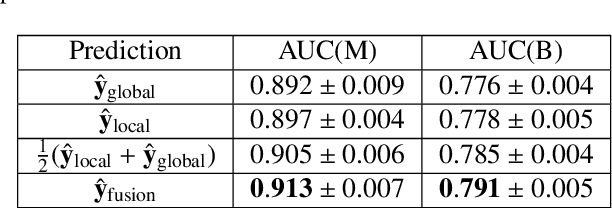
Medical images differ from natural images in significantly higher resolutions and smaller regions of interest. Because of these differences, neural network architectures that work well for natural images might not be applicable to medical image analysis. In this work, we extend the globally-aware multiple instance classifier, a framework we proposed to address these unique properties of medical images. This model first uses a low-capacity, yet memory-efficient, network on the whole image to identify the most informative regions. It then applies another higher-capacity network to collect details from chosen regions. Finally, it employs a fusion module that aggregates global and local information to make a final prediction. While existing methods often require lesion segmentation during training, our model is trained with only image-level labels and can generate pixel-level saliency maps indicating possible malignant findings. We apply the model to screening mammography interpretation: predicting the presence or absence of benign and malignant lesions. On the NYU Breast Cancer Screening Dataset, consisting of more than one million images, our model achieves an AUC of 0.93 in classifying breasts with malignant findings, outperforming ResNet-34 and Faster R-CNN. Compared to ResNet-34, our model is 4.1x faster for inference while using 78.4% less GPU memory. Furthermore, we demonstrate, in a reader study, that our model surpasses radiologist-level AUC by a margin of 0.11. The proposed model is available online: https://github.com/nyukat/GMIC.
Improving localization-based approaches for breast cancer screening exam classification
Aug 01, 2019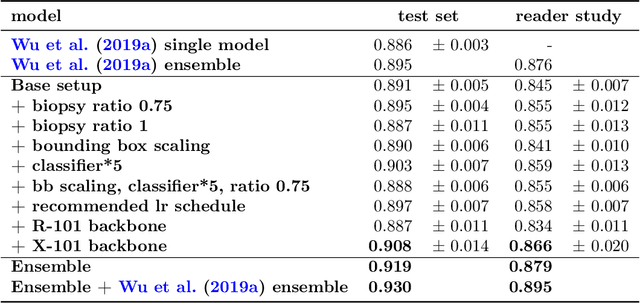
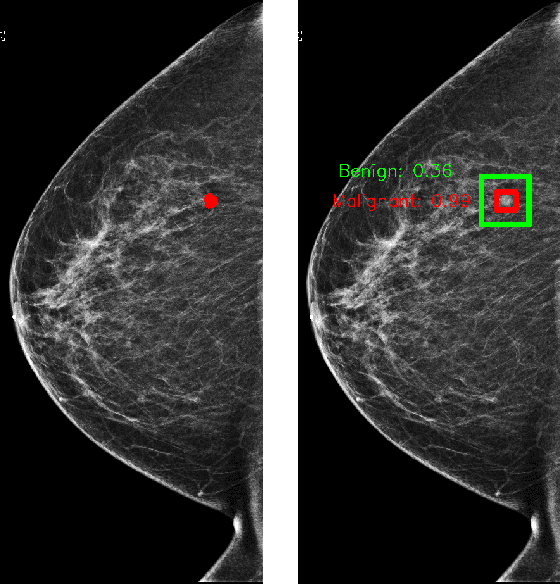
We trained and evaluated a localization-based deep CNN for breast cancer screening exam classification on over 200,000 exams (over 1,000,000 images). Our model achieves an AUC of 0.919 in predicting malignancy in patients undergoing breast cancer screening, reducing the error rate of the baseline (Wu et al., 2019a) by 23%. In addition, the models generates bounding boxes for benign and malignant findings, providing interpretable predictions.
Screening Mammogram Classification with Prior Exams
Jul 30, 2019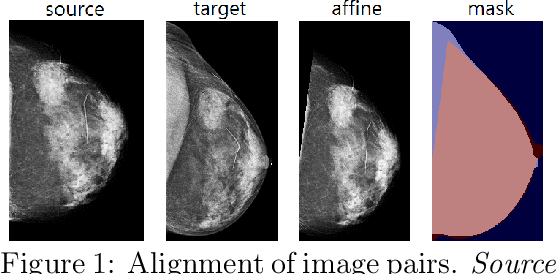
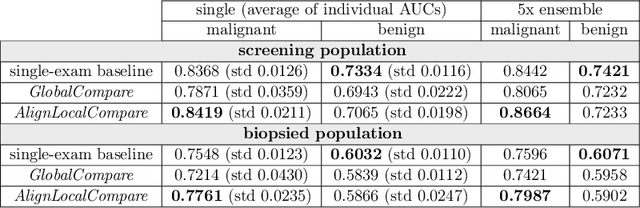
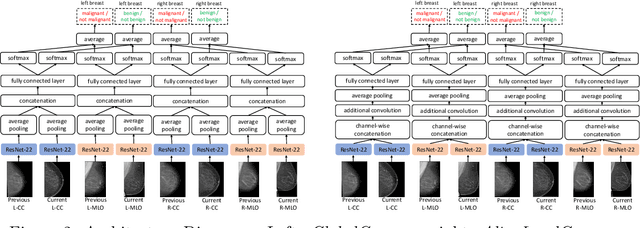
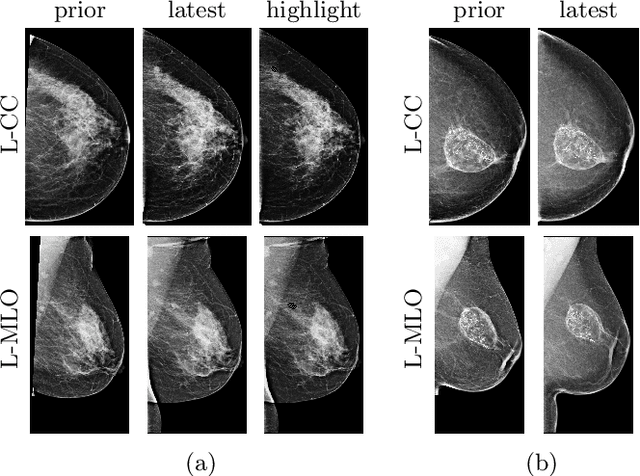
Radiologists typically compare a patient's most recent breast cancer screening exam to their previous ones in making informed diagnoses. To reflect this practice, we propose new neural network models that compare pairs of screening mammograms from the same patient. We train and evaluate our proposed models on over 665,000 pairs of images (over 166,000 pairs of exams). Our best model achieves an AUC of 0.866 in predicting malignancy in patients who underwent breast cancer screening, reducing the error rate of the corresponding baseline.
Deep Neural Networks Improve Radiologists' Performance in Breast Cancer Screening
Mar 20, 2019
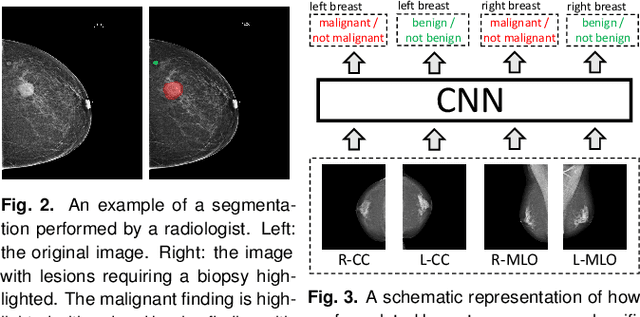
We present a deep convolutional neural network for breast cancer screening exam classification, trained and evaluated on over 200,000 exams (over 1,000,000 images). Our network achieves an AUC of 0.895 in predicting whether there is a cancer in the breast, when tested on the screening population. We attribute the high accuracy of our model to a two-stage training procedure, which allows us to use a very high-capacity patch-level network to learn from pixel-level labels alongside a network learning from macroscopic breast-level labels. To validate our model, we conducted a reader study with 14 readers, each reading 720 screening mammogram exams, and find our model to be as accurate as experienced radiologists when presented with the same data. Finally, we show that a hybrid model, averaging probability of malignancy predicted by a radiologist with a prediction of our neural network, is more accurate than either of the two separately. To better understand our results, we conduct a thorough analysis of our network's performance on different subpopulations of the screening population, model design, training procedure, errors, and properties of its internal representations.
High-Resolution Breast Cancer Screening with Multi-View Deep Convolutional Neural Networks
Jun 28, 2018
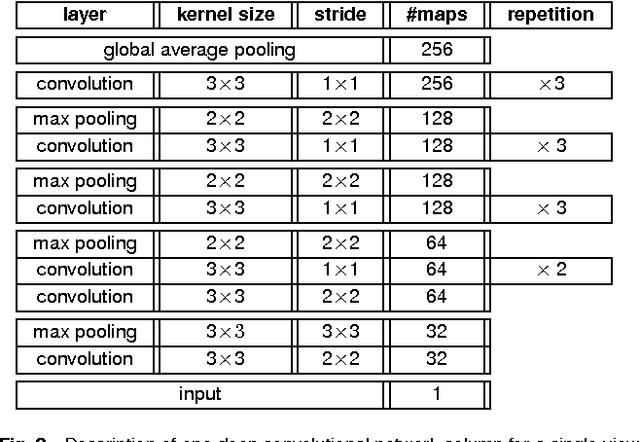

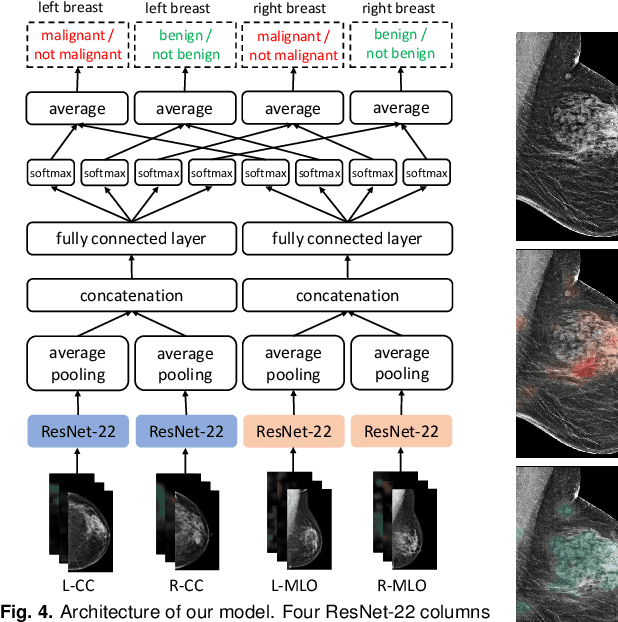
Advances in deep learning for natural images have prompted a surge of interest in applying similar techniques to medical images. The majority of the initial attempts focused on replacing the input of a deep convolutional neural network with a medical image, which does not take into consideration the fundamental differences between these two types of images. Specifically, fine details are necessary for detection in medical images, unlike in natural images where coarse structures matter most. This difference makes it inadequate to use the existing network architectures developed for natural images, because they work on heavily downscaled images to reduce the memory requirements. This hides details necessary to make accurate predictions. Additionally, a single exam in medical imaging often comes with a set of views which must be fused in order to reach a correct conclusion. In our work, we propose to use a multi-view deep convolutional neural network that handles a set of high-resolution medical images. We evaluate it on large-scale mammography-based breast cancer screening (BI-RADS prediction) using 886,000 images. We focus on investigating the impact of the training set size and image size on the prediction accuracy. Our results highlight that performance increases with the size of training set, and that the best performance can only be achieved using the original resolution. In the reader study, performed on a random subset of the test set, we confirmed the efficacy of our model, which achieved performance comparable to a committee of radiologists when presented with the same data.
Breast density classification with deep convolutional neural networks
Nov 10, 2017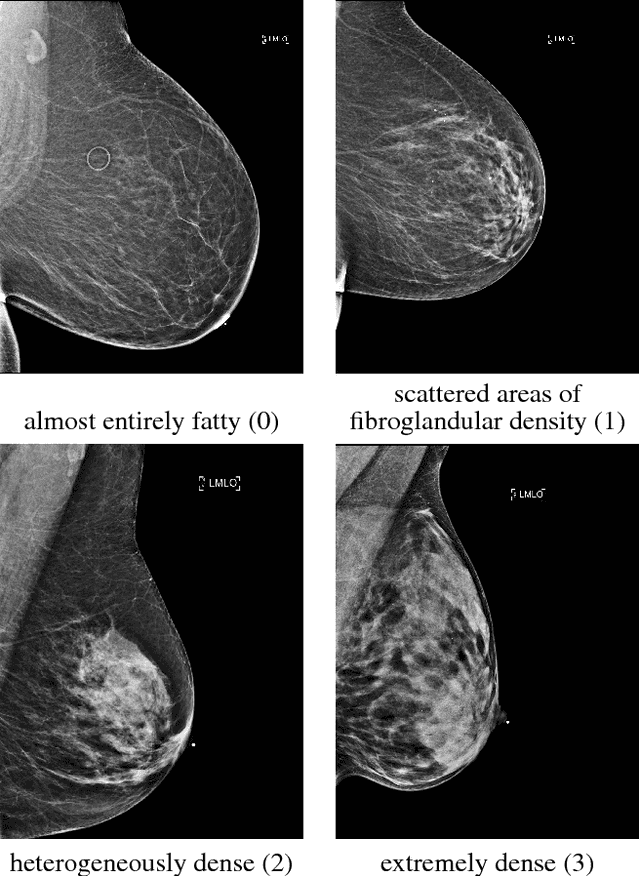
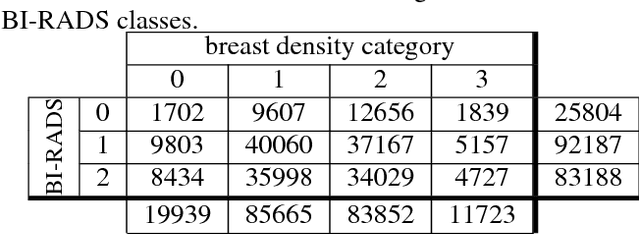
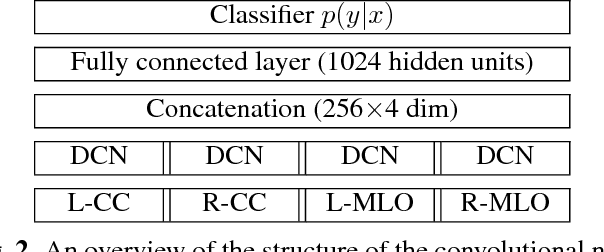
Breast density classification is an essential part of breast cancer screening. Although a lot of prior work considered this problem as a task for learning algorithms, to our knowledge, all of them used small and not clinically realistic data both for training and evaluation of their models. In this work, we explore the limits of this task with a data set coming from over 200,000 breast cancer screening exams. We use this data to train and evaluate a strong convolutional neural network classifier. In a reader study, we find that our model can perform this task comparably to a human expert.