 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGenT Zero: Zero-shot Automatic Multiple-Choice Question Generation for Skill Assessments
Dec 18, 2020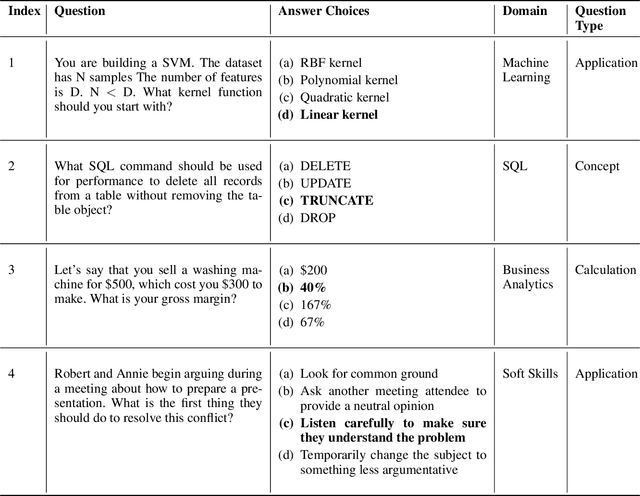
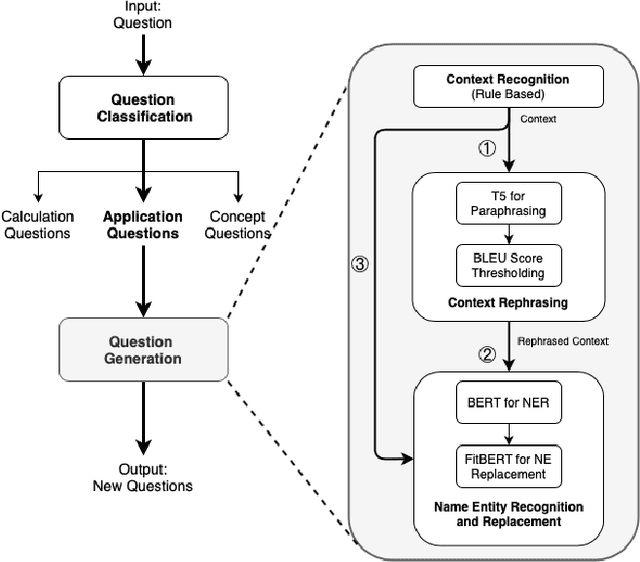

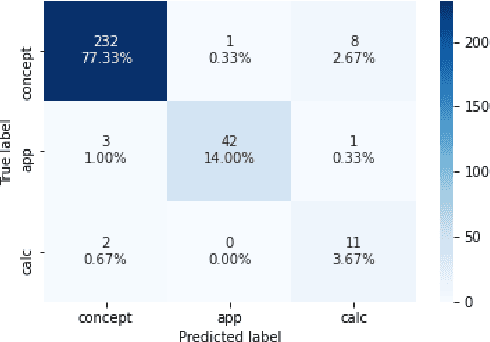
Multiple-choice questions (MCQs) offer the most promising avenue for skill evaluation in the era of virtual education and job recruiting, where traditional performance-based alternatives such as projects and essays have become less viable, and grading resources are constrained. The automated generation of MCQs would allow assessment creation at scale. Recent advances in natural language processing have given rise to many complex question generation methods. However, the few methods that produce deployable results in specific domains require a large amount of domain-specific training data that can be very costly to acquire. Our work provides an initial foray into MCQ generation under high data-acquisition cost scenarios by strategically emphasizing paraphrasing the question context (compared to the task). In addition to maintaining semantic similarity between the question-answer pairs, our pipeline, which we call AGenT Zero, consists of only pre-trained models and requires no fine-tuning, minimizing data acquisition costs for question generation. AGenT Zero successfully outperforms other pre-trained methods in fluency and semantic similarity. Additionally, with some small changes, our assessment pipeline can be generalized to a broader question and answer space, including short answer or fill in the blank questions.
Effective Data Fusion with Generalized Vegetation Index: Evidence from Land Cover Segmentation in Agriculture
May 07, 2020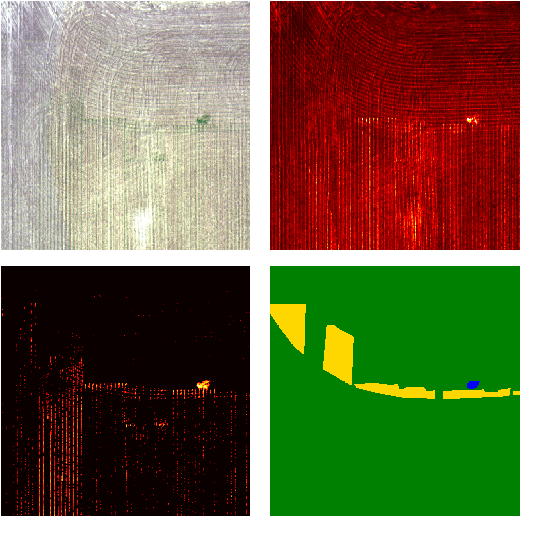

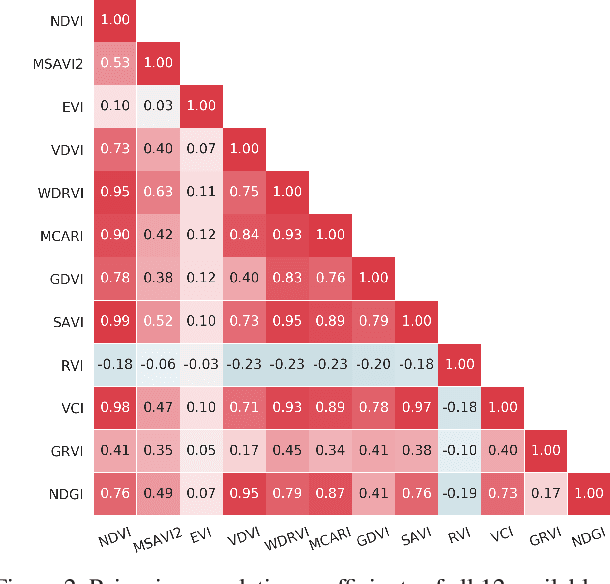
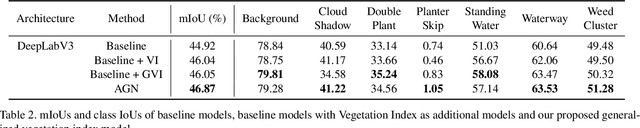
How can we effectively leverage the domain knowledge from remote sensing to better segment agriculture land cover from satellite images? In this paper, we propose a novel, model-agnostic, data-fusion approach for vegetation-related computer vision tasks. Motivated by the various Vegetation Indices (VIs), which are introduced by domain experts, we systematically reviewed the VIs that are widely used in remote sensing and their feasibility to be incorporated in deep neural networks. To fully leverage the Near-Infrared channel, the traditional Red-Green-Blue channels, and Vegetation Index or its variants, we propose a Generalized Vegetation Index (GVI), a lightweight module that can be easily plugged into many neural network architectures to serve as an additional information input. To smoothly train models with our GVI, we developed an Additive Group Normalization (AGN) module that does not require extra parameters of the prescribed neural networks. Our approach has improved the IoUs of vegetation-related classes by 0.9-1.3 percent and consistently improves the overall mIoU by 2 percent on our baseline.
The 1st Agriculture-Vision Challenge: Methods and Results
Apr 23, 2020
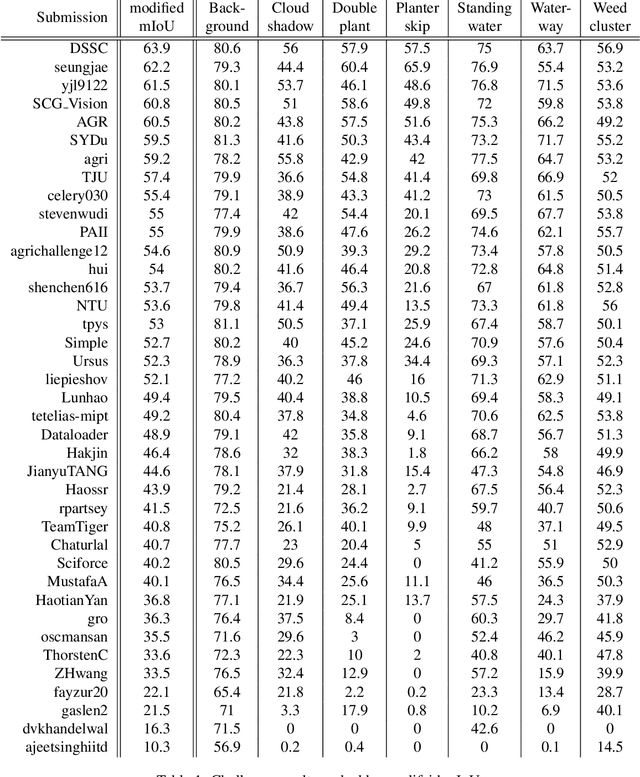
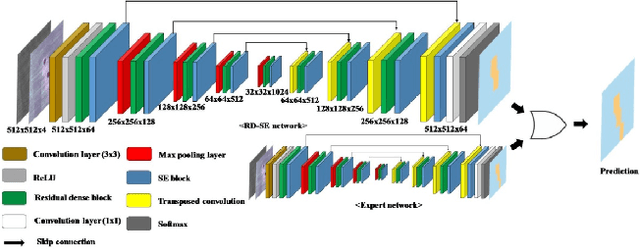
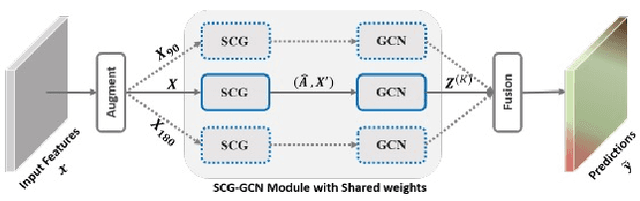
The first Agriculture-Vision Challenge aims to encourage research in developing novel and effective algorithms for agricultural pattern recognition from aerial images, especially for the semantic segmentation task associated with our challenge dataset. Around 57 participating teams from various countries compete to achieve state-of-the-art in aerial agriculture semantic segmentation. The Agriculture-Vision Challenge Dataset was employed, which comprises of 21,061 aerial and multi-spectral farmland images. This paper provides a summary of notable methods and results in the challenge. Our submission server and leaderboard will continue to open for researchers that are interested in this challenge dataset and task; the link can be found here.
Breast density classification with deep convolutional neural networks
Nov 10, 2017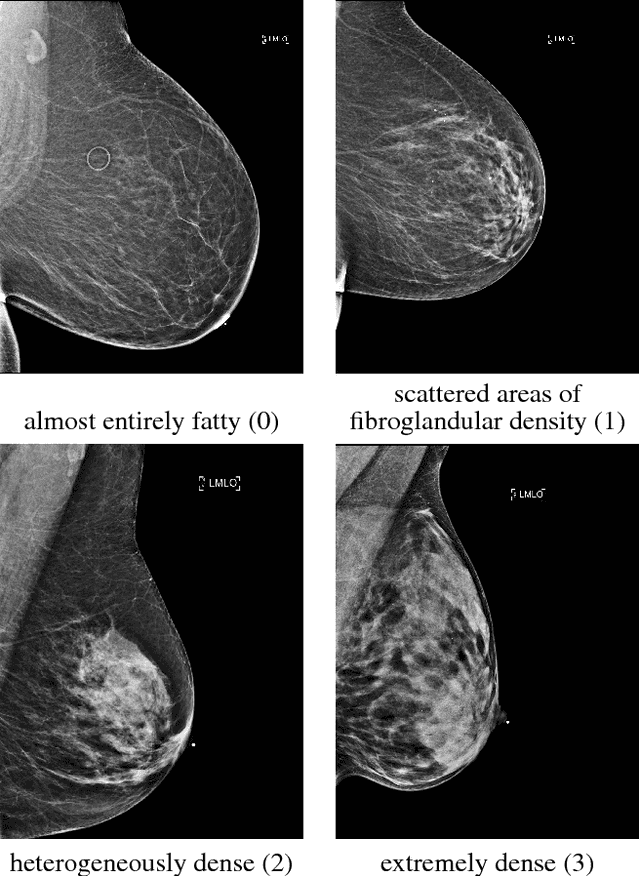
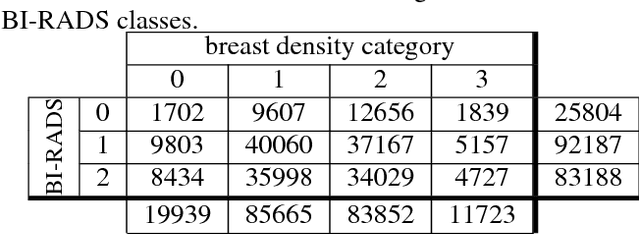
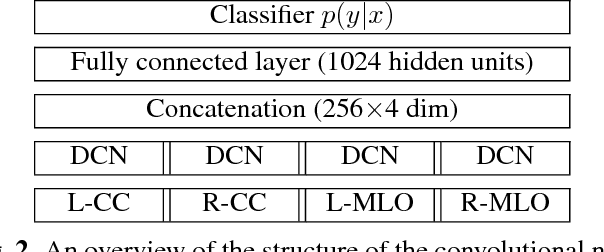
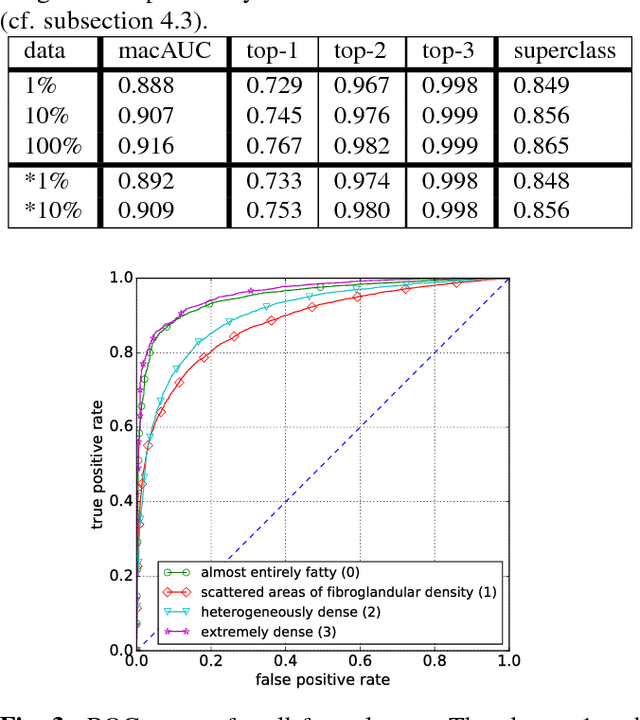
Breast density classification is an essential part of breast cancer screening. Although a lot of prior work considered this problem as a task for learning algorithms, to our knowledge, all of them used small and not clinically realistic data both for training and evaluation of their models. In this work, we explore the limits of this task with a data set coming from over 200,000 breast cancer screening exams. We use this data to train and evaluate a strong convolutional neural network classifier. In a reader study, we find that our model can perform this task comparably to a human expert.