 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
GLIMMER: generalized late-interaction memory reranker
Jun 17, 2023



Memory-augmentation is a powerful approach for efficiently incorporating external information into language models, but leads to reduced performance relative to retrieving text. Recent work introduced LUMEN, a memory-retrieval hybrid that partially pre-computes memory and updates memory representations on the fly with a smaller live encoder. We propose GLIMMER, which improves on this approach through 1) exploiting free access to the powerful memory representations by applying a shallow reranker on top of memory to drastically improve retrieval quality at low cost, and 2) incorporating multi-task training to learn a general and higher quality memory and live encoder. GLIMMER achieves strong gains in performance at faster speeds compared to LUMEN and FiD on the KILT benchmark of knowledge-intensive tasks.
Pre-computed memory or on-the-fly encoding? A hybrid approach to retrieval augmentation makes the most of your compute
Jan 25, 2023



Retrieval-augmented language models such as Fusion-in-Decoder are powerful, setting the state of the art on a variety of knowledge-intensive tasks. However, they are also expensive, due to the need to encode a large number of retrieved passages. Some work avoids this cost by pre-encoding a text corpus into a memory and retrieving dense representations directly. However, pre-encoding memory incurs a severe quality penalty as the memory representations are not conditioned on the current input. We propose LUMEN, a hybrid between these two extremes, pre-computing the majority of the retrieval representation and completing the encoding on the fly using a live encoder that is conditioned on the question and fine-tuned for the task. We show that LUMEN significantly outperforms pure memory on multiple question-answering tasks while being much cheaper than FiD, and outperforms both for any given compute budget. Moreover, the advantage of LUMEN over FiD increases with model size.
FiDO: Fusion-in-Decoder optimized for stronger performance and faster inference
Dec 15, 2022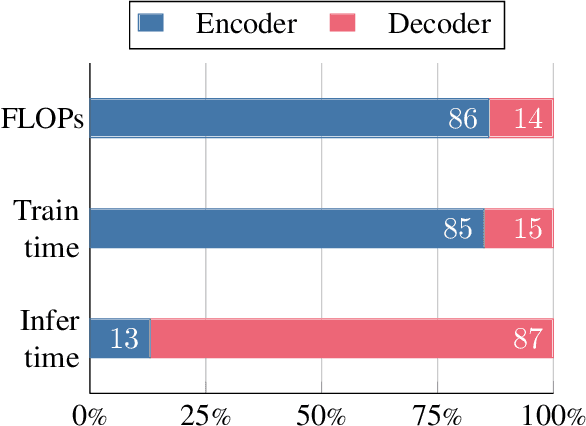

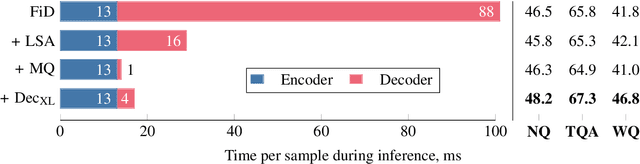

Fusion-in-Decoder (FiD) is a powerful retrieval-augmented language model that sets the state-of-the-art on many knowledge-intensive NLP tasks. However, FiD suffers from very expensive inference. We show that the majority of inference time results from memory bandwidth constraints in the decoder, and propose two simple changes to the FiD architecture to speed up inference by 7x. The faster decoder inference then allows for a much larger decoder. We denote FiD with the above modifications as FiDO, and show that it strongly improves performance over existing FiD models for a wide range of inference budgets. For example, FiDO-Large-XXL performs faster inference than FiD-Base and achieves better performance than FiD-Large.
Mention Memory: incorporating textual knowledge into Transformers through entity mention attention
Oct 12, 2021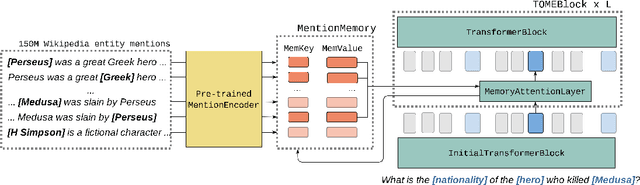
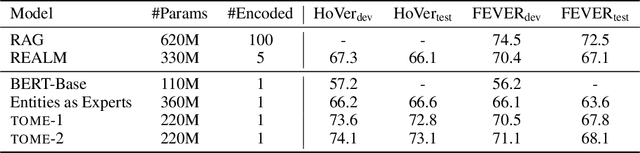
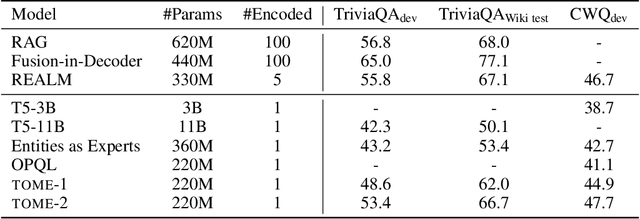
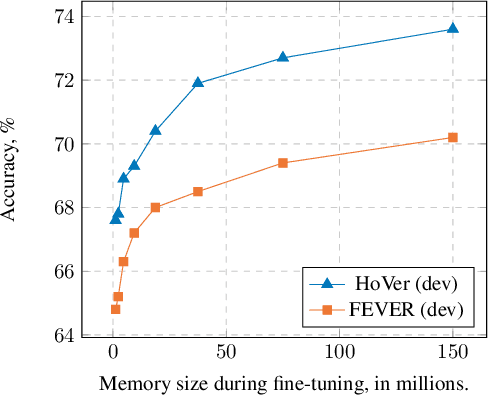
Natural language understanding tasks such as open-domain question answering often require retrieving and assimilating factual information from multiple sources. We propose to address this problem by integrating a semi-parametric representation of a large text corpus into a Transformer model as a source of factual knowledge. Specifically, our method represents knowledge with `mention memory', a table of dense vector representations of every entity mention in a corpus. The proposed model - TOME - is a Transformer that accesses the information through internal memory layers in which each entity mention in the input passage attends to the mention memory. This approach enables synthesis of and reasoning over many disparate sources of information within a single Transformer model. In experiments using a memory of 150 million Wikipedia mentions, TOME achieves strong performance on several open-domain knowledge-intensive tasks, including the claim verification benchmarks HoVer and FEVER and several entity-based QA benchmarks. We also show that the model learns to attend to informative mentions without any direct supervision. Finally we demonstrate that the model can generalize to new unseen entities by updating the memory without retraining.
MOLEMAN: Mention-Only Linking of Entities with a Mention Annotation Network
Jun 02, 2021
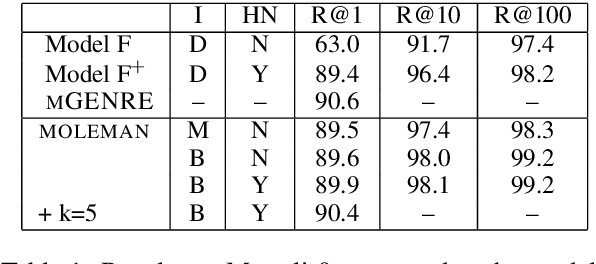
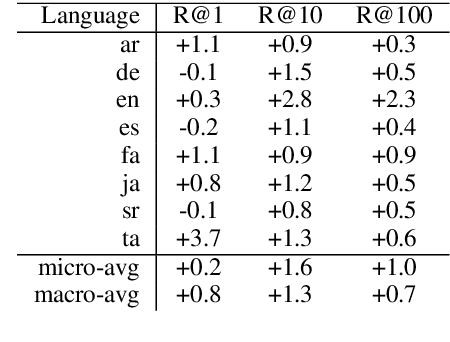
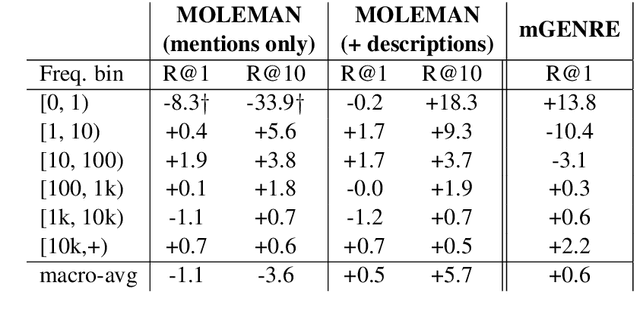
We present an instance-based nearest neighbor approach to entity linking. In contrast to most prior entity retrieval systems which represent each entity with a single vector, we build a contextualized mention-encoder that learns to place similar mentions of the same entity closer in vector space than mentions of different entities. This approach allows all mentions of an entity to serve as "class prototypes" as inference involves retrieving from the full set of labeled entity mentions in the training set and applying the nearest mention neighbor's entity label. Our model is trained on a large multilingual corpus of mention pairs derived from Wikipedia hyperlinks, and performs nearest neighbor inference on an index of 700 million mentions. It is simpler to train, gives more interpretable predictions, and outperforms all other systems on two multilingual entity linking benchmarks.
Empirical Evaluation of Pretraining Strategies for Supervised Entity Linking
May 28, 2020
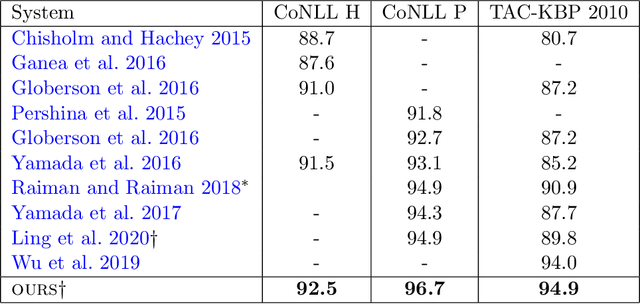

In this work, we present an entity linking model which combines a Transformer architecture with large scale pretraining from Wikipedia links. Our model achieves the state-of-the-art on two commonly used entity linking datasets: 96.7% on CoNLL and 94.9% on TAC-KBP. We present detailed analyses to understand what design choices are important for entity linking, including choices of negative entity candidates, Transformer architecture, and input perturbations. Lastly, we present promising results on more challenging settings such as end-to-end entity linking and entity linking without in-domain training data.
Entities as Experts: Sparse Memory Access with Entity Supervision
Apr 15, 2020
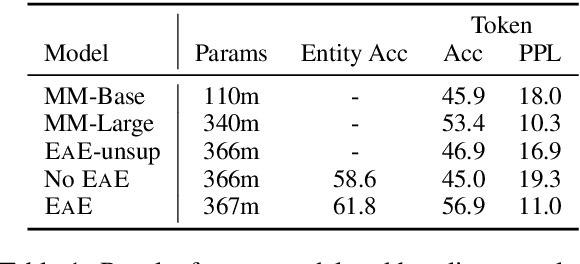
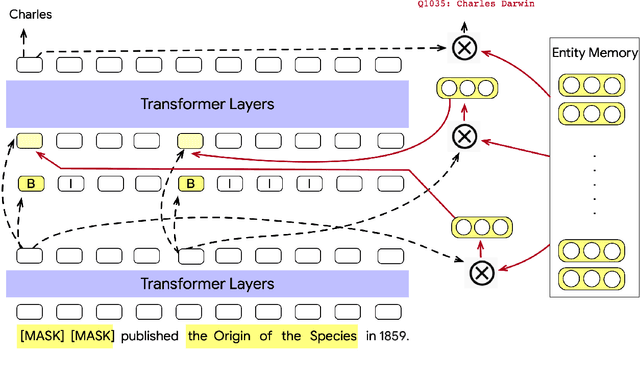
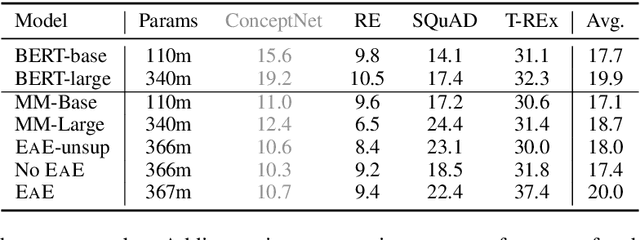
We focus on the problem of capturing declarative knowledge in the learned parameters of a language model. We introduce a new model, Entities as Experts (EaE), that can access distinct memories of the entities mentioned in a piece of text. Unlike previous efforts to integrate entity knowledge into sequence models, EaE's entity representations are learned directly from text. These representations capture sufficient knowledge to answer TriviaQA questions such as "Which Dr. Who villain has been played by Roger Delgado, Anthony Ainley, Eric Roberts?". EaE outperforms a Transformer model with $30\times$ the parameters on this task. According to the Lama knowledge probes, EaE also contains more factual knowledge than a similar sized Bert. We show that associating parameters with specific entities means that EaE only needs to access a fraction of its parameters at inference time, and we show that the correct identification, and representation, of entities is essential to EaE's performance. We also argue that the discrete and independent entity representations in EaE make it more modular and interpretable than the Transformer architecture on which it is based.
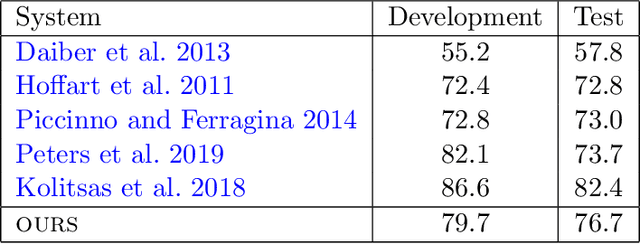
Learning Cross-Context Entity Representations from Text
Jan 11, 2020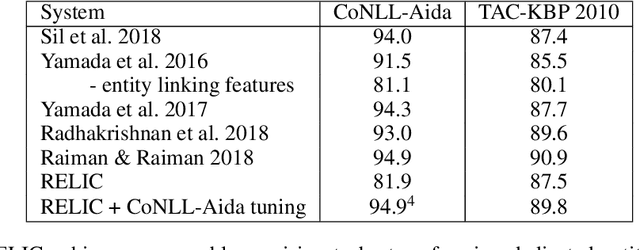
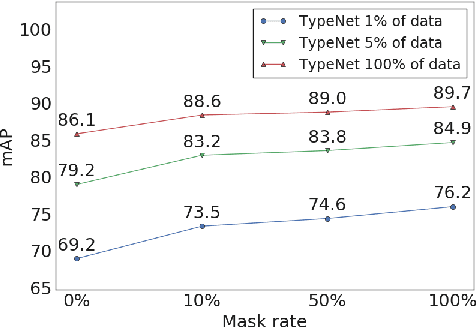

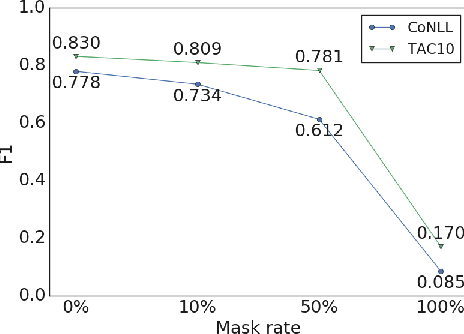
Language modeling tasks, in which words, or word-pieces, are predicted on the basis of a local context, have been very effective for learning word embeddings and context dependent representations of phrases. Motivated by the observation that efforts to code world knowledge into machine readable knowledge bases or human readable encyclopedias tend to be entity-centric, we investigate the use of a fill-in-the-blank task to learn context independent representations of entities from the text contexts in which those entities were mentioned. We show that large scale training of neural models allows us to learn high quality entity representations, and we demonstrate successful results on four domains: (1) existing entity-level typing benchmarks, including a 64% error reduction over previous work on TypeNet (Murty et al., 2018); (2) a novel few-shot category reconstruction task; (3) existing entity linking benchmarks, where we match the state-of-the-art on CoNLL-Aida without linking-specific features and obtain a score of 89.8% on TAC-KBP 2010 without using any alias table, external knowledge base or in domain training data and (4) answering trivia questions, which uniquely identify entities. Our global entity representations encode fine-grained type categories, such as Scottish footballers, and can answer trivia questions such as: Who was the last inmate of Spandau jail in Berlin?