Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiDO: Fusion-in-Decoder optimized for stronger performance and faster inference
Paper and Code
Dec 15, 2022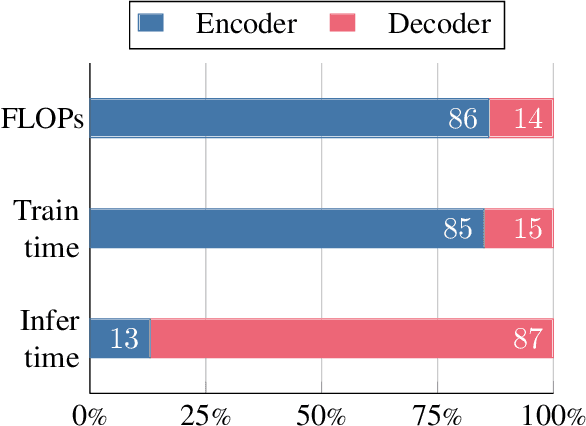

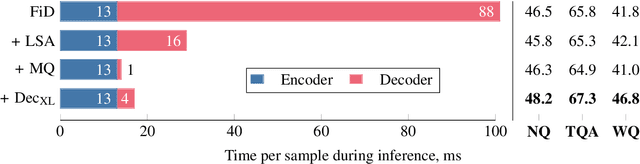

Fusion-in-Decoder (FiD) is a powerful retrieval-augmented language model that sets the state-of-the-art on many knowledge-intensive NLP tasks. However, FiD suffers from very expensive inference. We show that the majority of inference time results from memory bandwidth constraints in the decoder, and propose two simple changes to the FiD architecture to speed up inference by 7x. The faster decoder inference then allows for a much larger decoder. We denote FiD with the above modifications as FiDO, and show that it strongly improves performance over existing FiD models for a wide range of inference budgets. For example, FiDO-Large-XXL performs faster inference than FiD-Base and achieves better performance than FiD-Large.
View paper on