 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Boundary Augmentation For Neural Machine Translation Robustness
Oct 21, 2020
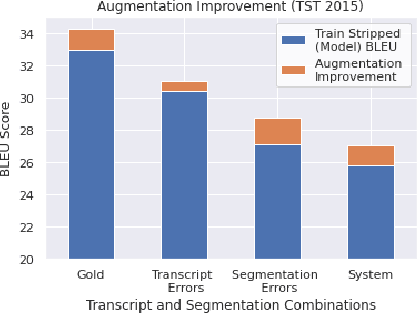

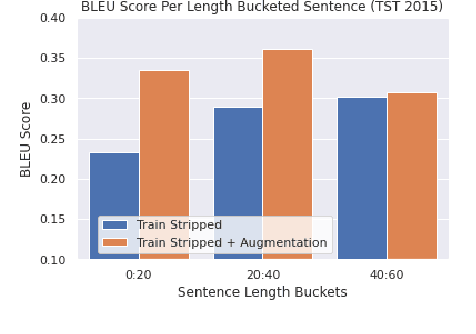
Neural Machine Translation (NMT) models have demonstrated strong state of the art performance on translation tasks where well-formed training and evaluation data are provided, but they remain sensitive to inputs that include errors of various types. Specifically, in the context of long-form speech translation systems, where the input transcripts come from Automatic Speech Recognition (ASR), the NMT models have to handle errors including phoneme substitutions, grammatical structure, and sentence boundaries, all of which pose challenges to NMT robustness. Through in-depth error analysis, we show that sentence boundary segmentation has the largest impact on quality, and we develop a simple data augmentation strategy to improve segmentation robustness.
Re-Translation Strategies For Long Form, Simultaneous, Spoken Language Translation
Dec 06, 2019
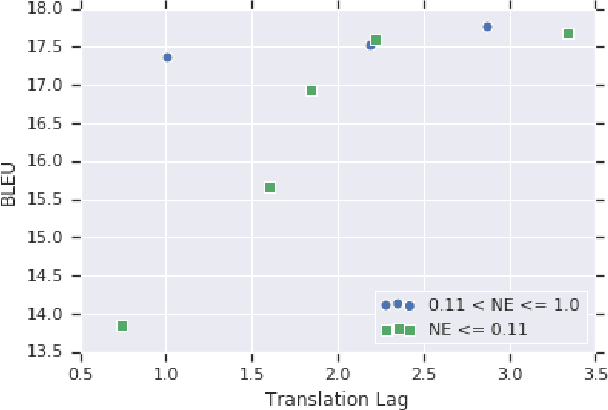
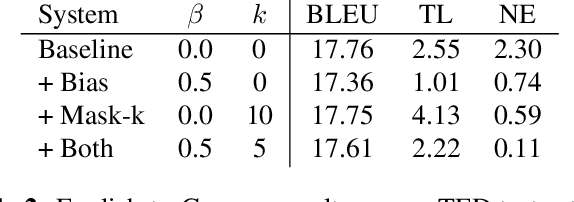
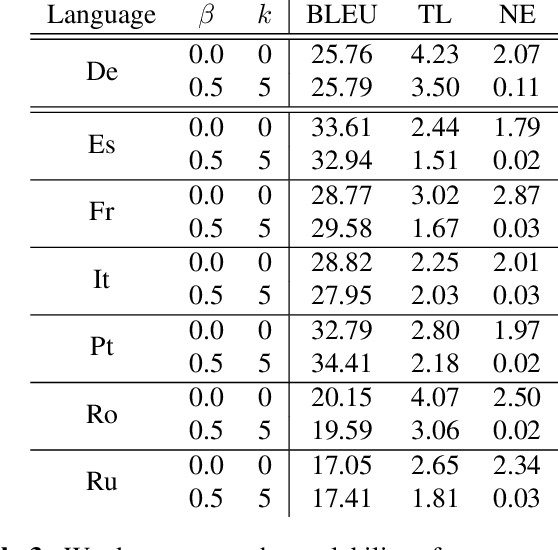
We investigate the problem of simultaneous machine translation of long-form speech content. We target a continuous speech-to-text scenario, generating translated captions for a live audio feed, such as a lecture or play-by-play commentary. As this scenario allows for revisions to our incremental translations, we adopt a re-translation approach to simultaneous translation, where the source is repeatedly translated from scratch as it grows. This approach naturally exhibits very low latency and high final quality, but at the cost of incremental instability as the output is continuously refined. We experiment with a pipeline of industry-grade speech recognition and translation tools, augmented with simple inference heuristics to improve stability. We use TED Talks as a source of multilingual test data, developing our techniques on English-to-German spoken language translation. Our minimalist approach to simultaneous translation allows us to easily scale our final evaluation to six more target languages, dramatically improving incremental stability for all of them.