 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Text Generation: A Practical Guide
Nov 27, 2017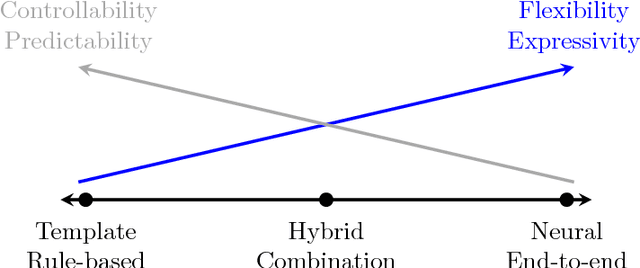
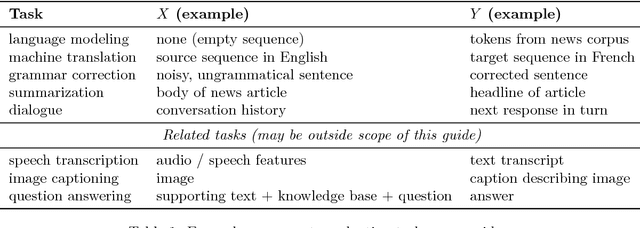
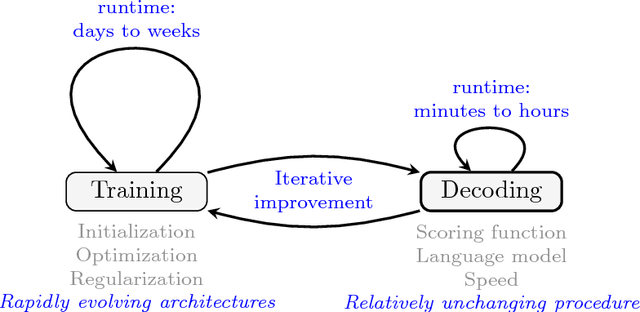
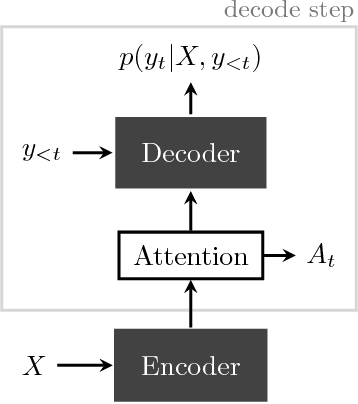
Deep learning methods have recently achieved great empirical success on machine translation, dialogue response generation, summarization, and other text generation tasks. At a high level, the technique has been to train end-to-end neural network models consisting of an encoder model to produce a hidden representation of the source text, followed by a decoder model to generate the target. While such models have significantly fewer pieces than earlier systems, significant tuning is still required to achieve good performance. For text generation models in particular, the decoder can behave in undesired ways, such as by generating truncated or repetitive outputs, outputting bland and generic responses, or in some cases producing ungrammatical gibberish. This paper is intended as a practical guide for resolving such undesired behavior in text generation models, with the aim of helping enable real-world applications.
Data Noising as Smoothing in Neural Network Language Models
Mar 07, 2017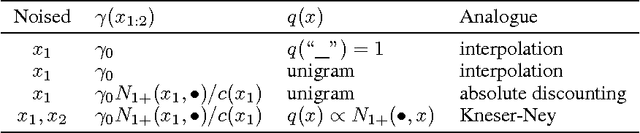
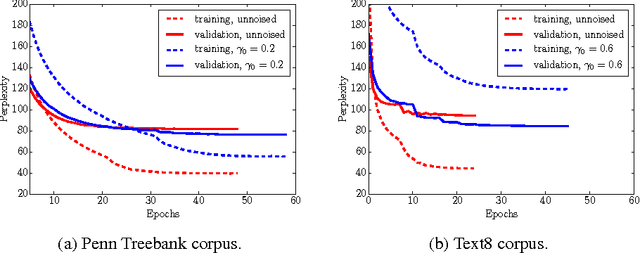
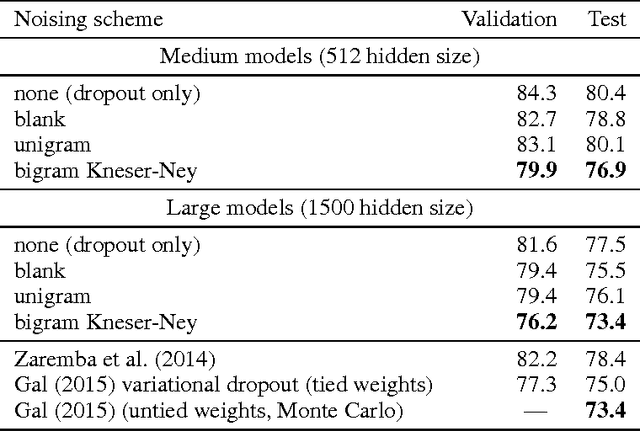
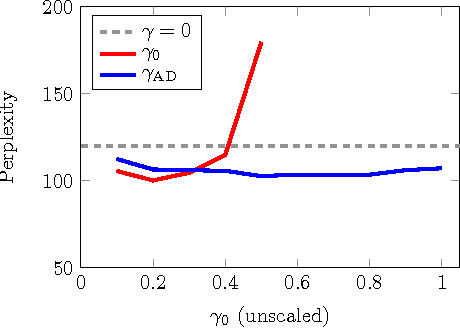
Data noising is an effective technique for regularizing neural network models. While noising is widely adopted in application domains such as vision and speech, commonly used noising primitives have not been developed for discrete sequence-level settings such as language modeling. In this paper, we derive a connection between input noising in neural network language models and smoothing in $n$-gram models. Using this connection, we draw upon ideas from smoothing to develop effective noising schemes. We demonstrate performance gains when applying the proposed schemes to language modeling and machine translation. Finally, we provide empirical analysis validating the relationship between noising and smoothing.
Neural Language Correction with Character-Based Attention
Mar 31, 2016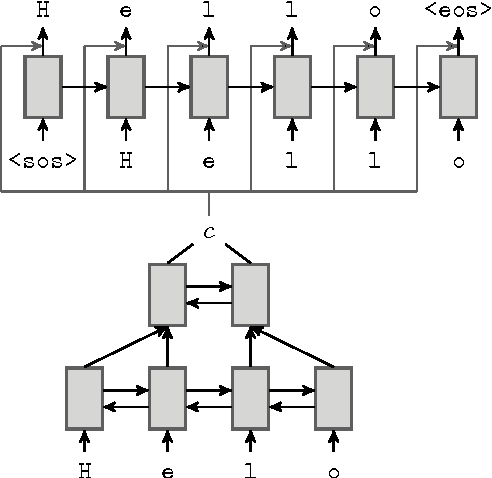


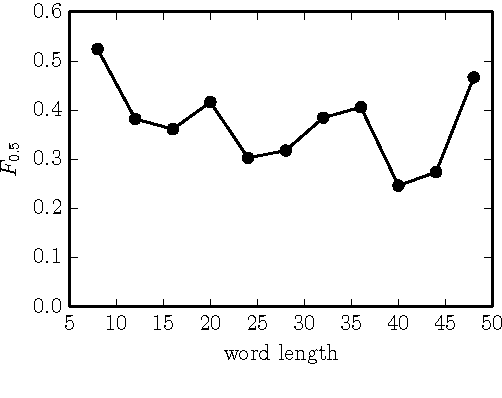
Natural language correction has the potential to help language learners improve their writing skills. While approaches with separate classifiers for different error types have high precision, they do not flexibly handle errors such as redundancy or non-idiomatic phrasing. On the other hand, word and phrase-based machine translation methods are not designed to cope with orthographic errors, and have recently been outpaced by neural models. Motivated by these issues, we present a neural network-based approach to language correction. The core component of our method is an encoder-decoder recurrent neural network with an attention mechanism. By operating at the character level, the network avoids the problem of out-of-vocabulary words. We illustrate the flexibility of our approach on dataset of noisy, user-generated text collected from an English learner forum. When combined with a language model, our method achieves a state-of-the-art $F_{0.5}$-score on the CoNLL 2014 Shared Task. We further demonstrate that training the network on additional data with synthesized errors can improve performance.
Building DNN Acoustic Models for Large Vocabulary Speech Recognition
Jan 20, 2015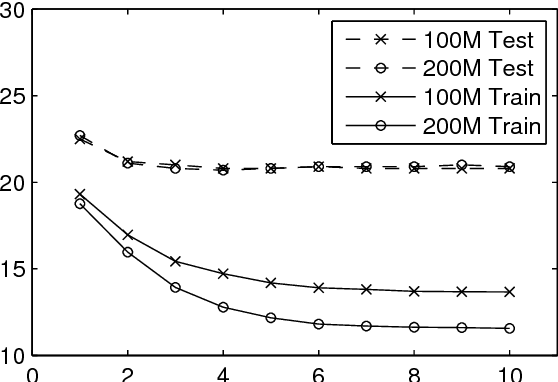

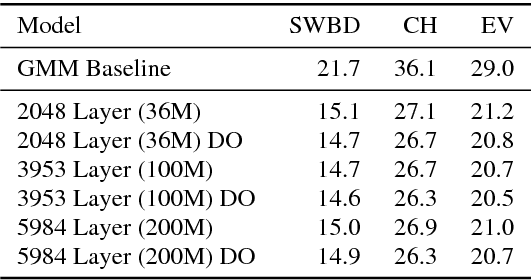

Deep neural networks (DNNs) are now a central component of nearly all state-of-the-art speech recognition systems. Building neural network acoustic models requires several design decisions including network architecture, size, and training loss function. This paper offers an empirical investigation on which aspects of DNN acoustic model design are most important for speech recognition system performance. We report DNN classifier performance and final speech recognizer word error rates, and compare DNNs using several metrics to quantify factors influencing differences in task performance. Our first set of experiments use the standard Switchboard benchmark corpus, which contains approximately 300 hours of conversational telephone speech. We compare standard DNNs to convolutional networks, and present the first experiments using locally-connected, untied neural networks for acoustic modeling. We additionally build systems on a corpus of 2,100 hours of training data by combining the Switchboard and Fisher corpora. This larger corpus allows us to more thoroughly examine performance of large DNN models -- with up to ten times more parameters than those typically used in speech recognition systems. Our results suggest that a relatively simple DNN architecture and optimization technique produces strong results. These findings, along with previous work, help establish a set of best practices for building DNN hybrid speech recognition systems with maximum likelihood training. Our experiments in DNN optimization additionally serve as a case study for training DNNs with discriminative loss functions for speech tasks, as well as DNN classifiers more generally.