 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCardiologist-Level Arrhythmia Detection with Convolutional Neural Networks
Jul 06, 2017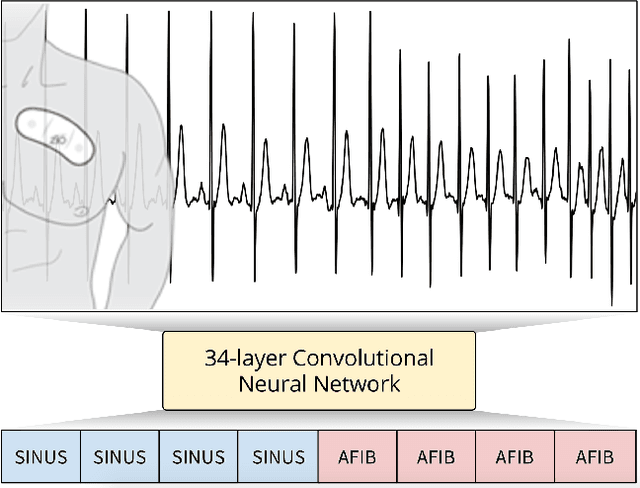
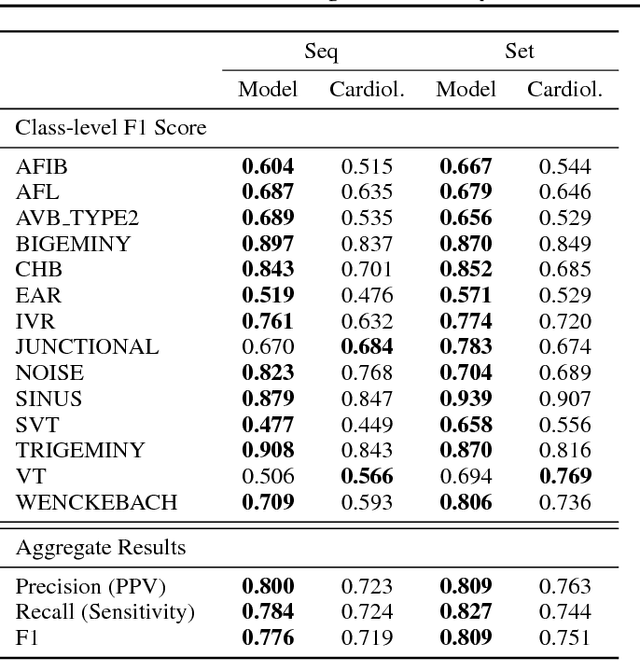
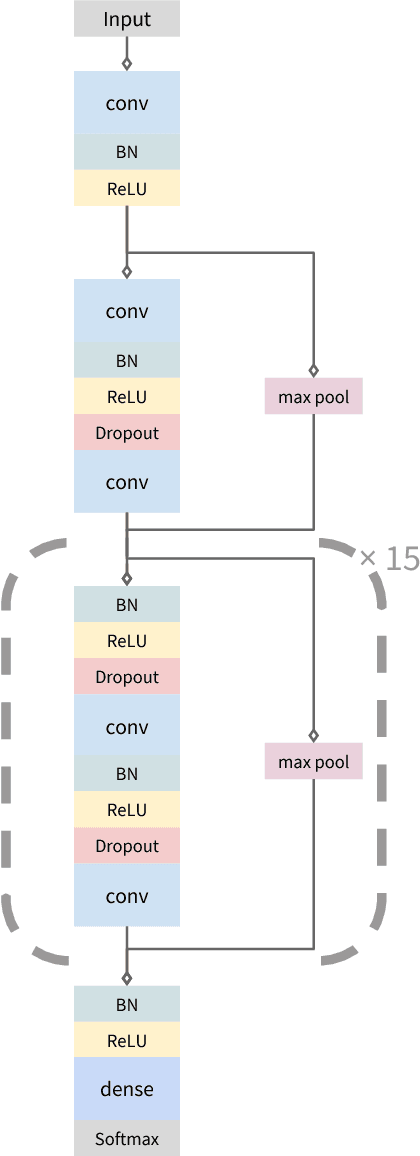
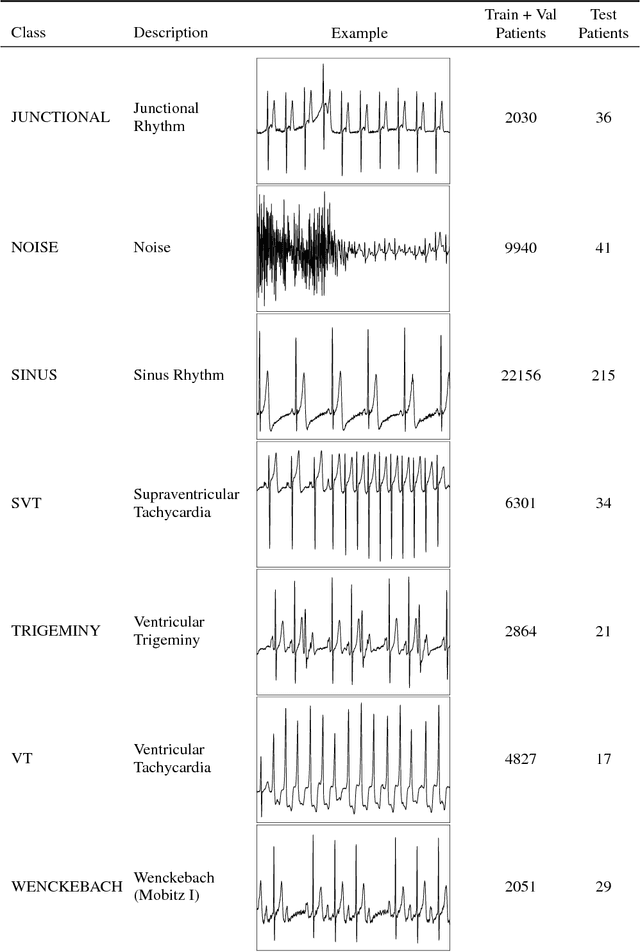
We develop an algorithm which exceeds the performance of board certified cardiologists in detecting a wide range of heart arrhythmias from electrocardiograms recorded with a single-lead wearable monitor. We build a dataset with more than 500 times the number of unique patients than previously studied corpora. On this dataset, we train a 34-layer convolutional neural network which maps a sequence of ECG samples to a sequence of rhythm classes. Committees of board-certified cardiologists annotate a gold standard test set on which we compare the performance of our model to that of 6 other individual cardiologists. We exceed the average cardiologist performance in both recall (sensitivity) and precision (positive predictive value).
Building DNN Acoustic Models for Large Vocabulary Speech Recognition
Jan 20, 2015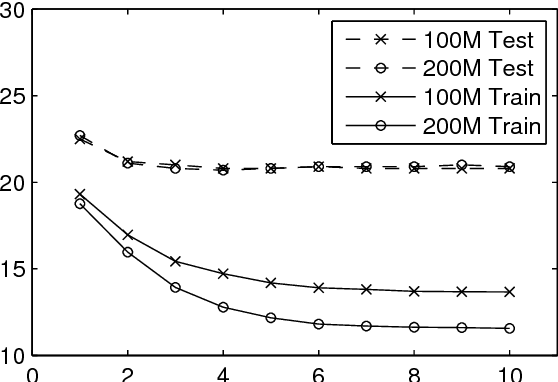

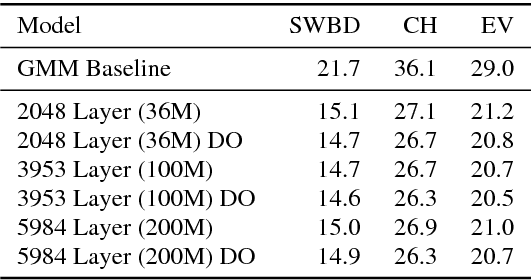

Deep neural networks (DNNs) are now a central component of nearly all state-of-the-art speech recognition systems. Building neural network acoustic models requires several design decisions including network architecture, size, and training loss function. This paper offers an empirical investigation on which aspects of DNN acoustic model design are most important for speech recognition system performance. We report DNN classifier performance and final speech recognizer word error rates, and compare DNNs using several metrics to quantify factors influencing differences in task performance. Our first set of experiments use the standard Switchboard benchmark corpus, which contains approximately 300 hours of conversational telephone speech. We compare standard DNNs to convolutional networks, and present the first experiments using locally-connected, untied neural networks for acoustic modeling. We additionally build systems on a corpus of 2,100 hours of training data by combining the Switchboard and Fisher corpora. This larger corpus allows us to more thoroughly examine performance of large DNN models -- with up to ten times more parameters than those typically used in speech recognition systems. Our results suggest that a relatively simple DNN architecture and optimization technique produces strong results. These findings, along with previous work, help establish a set of best practices for building DNN hybrid speech recognition systems with maximum likelihood training. Our experiments in DNN optimization additionally serve as a case study for training DNNs with discriminative loss functions for speech tasks, as well as DNN classifiers more generally.
First-Pass Large Vocabulary Continuous Speech Recognition using Bi-Directional Recurrent DNNs
Dec 08, 2014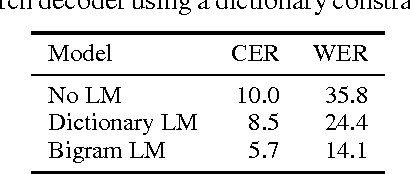

We present a method to perform first-pass large vocabulary continuous speech recognition using only a neural network and language model. Deep neural network acoustic models are now commonplace in HMM-based speech recognition systems, but building such systems is a complex, domain-specific task. Recent work demonstrated the feasibility of discarding the HMM sequence modeling framework by directly predicting transcript text from audio. This paper extends this approach in two ways. First, we demonstrate that a straightforward recurrent neural network architecture can achieve a high level of accuracy. Second, we propose and evaluate a modified prefix-search decoding algorithm. This approach to decoding enables first-pass speech recognition with a language model, completely unaided by the cumbersome infrastructure of HMM-based systems. Experiments on the Wall Street Journal corpus demonstrate fairly competitive word error rates, and the importance of bi-directional network recurrence.