 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Text Generation: A Practical Guide
Paper and Code
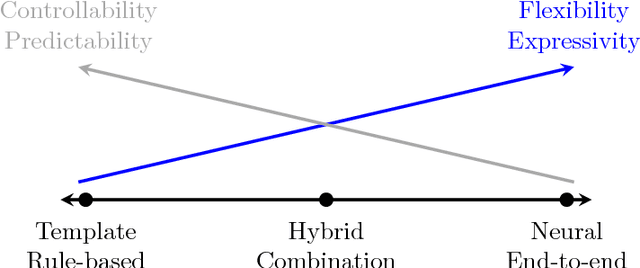
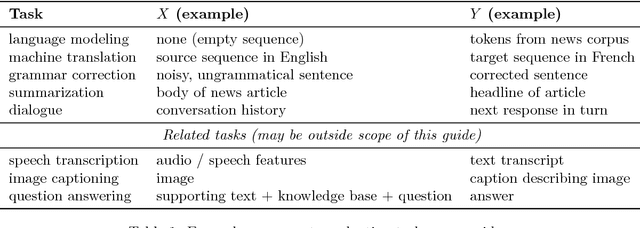
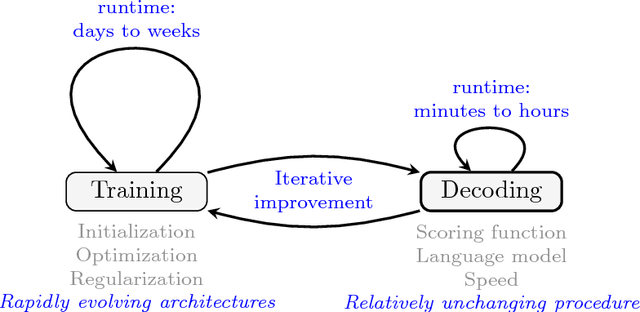
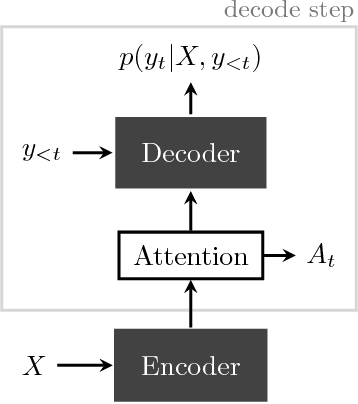
Deep learning methods have recently achieved great empirical success on machine translation, dialogue response generation, summarization, and other text generation tasks. At a high level, the technique has been to train end-to-end neural network models consisting of an encoder model to produce a hidden representation of the source text, followed by a decoder model to generate the target. While such models have significantly fewer pieces than earlier systems, significant tuning is still required to achieve good performance. For text generation models in particular, the decoder can behave in undesired ways, such as by generating truncated or repetitive outputs, outputting bland and generic responses, or in some cases producing ungrammatical gibberish. This paper is intended as a practical guide for resolving such undesired behavior in text generation models, with the aim of helping enable real-world applications.