 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Inpatient Discharge Prioritization With Electronic Health Records
Dec 02, 2018


Identifying patients who will be discharged within 24 hours can improve hospital resource management and quality of care. We studied this problem using eight years of Electronic Health Records (EHR) data from Stanford Hospital. We fit models to predict 24 hour discharge across the entire inpatient population. The best performing models achieved an area under the receiver-operator characteristic curve (AUROC) of 0.85 and an AUPRC of 0.53 on a held out test set. This model was also well calibrated. Finally, we analyzed the utility of this model in a decision theoretic framework to identify regions of ROC space in which using the model increases expected utility compared to the trivial always negative or always positive classifiers.
The Effectiveness of Multitask Learning for Phenotyping with Electronic Health Records Data
Oct 04, 2018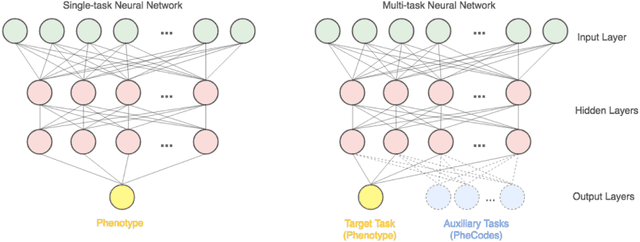
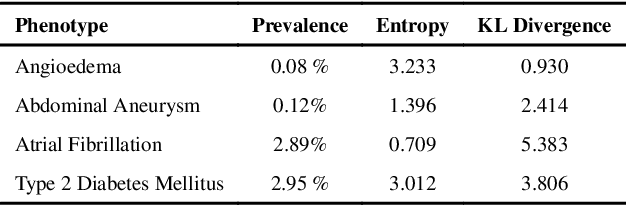
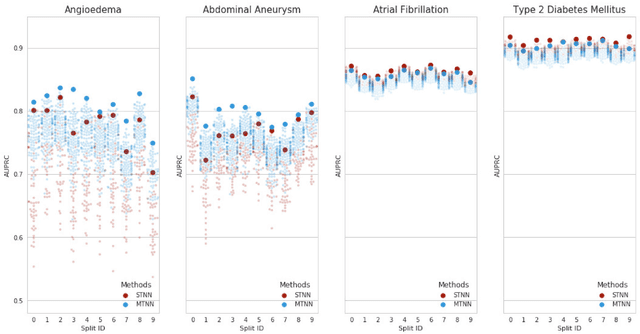
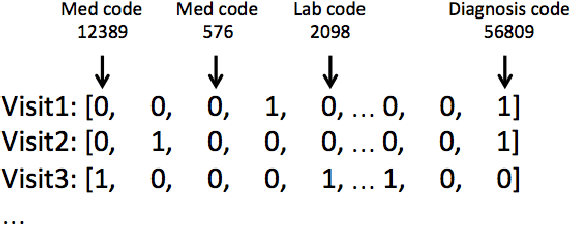
Electronic phenotyping is the task of ascertaining whether an individual has a medical condition of interest by analyzing their medical record and is foundational in clinical informatics. Increasingly, electronic phenotyping is performed via supervised learning. We investigate the effectiveness of multitask learning for phenotyping using electronic health records (EHR) data. Multitask learning aims to improve model performance on a target task by jointly learning additional auxiliary tasks and has been used in disparate areas of machine learning. However, its utility when applied to EHR data has not been established, and prior work suggests that its benefits are inconsistent. We present experiments that elucidate when multitask learning with neural nets improves performance for phenotyping using EHR data relative to neural nets trained for a single phenotype and to well-tuned logistic regression baselines. We find that multitask neural nets consistently outperform single-task neural nets for rare phenotypes but underperform for relatively more common phenotypes. The effect size increases as more auxiliary tasks are added. Moreover, multitask learning reduces the sensitivity of neural nets to hyperparameter settings for rare phenotypes. Last, we quantify phenotype complexity and find that neural nets trained with or without multitask learning do not improve on simple baselines unless the phenotypes are sufficiently complex.
Effective Representations of Clinical Notes
Aug 16, 2018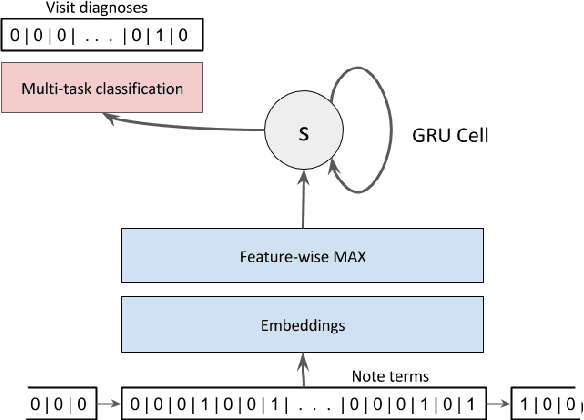
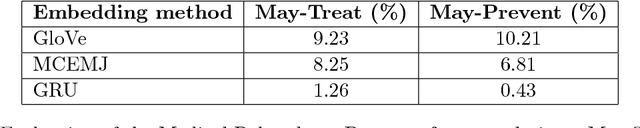
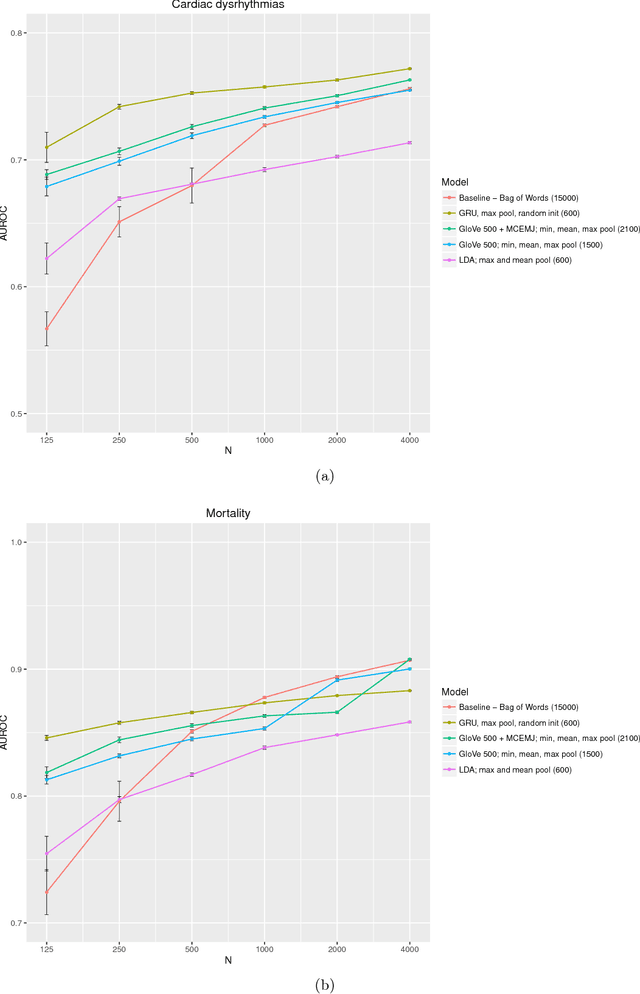
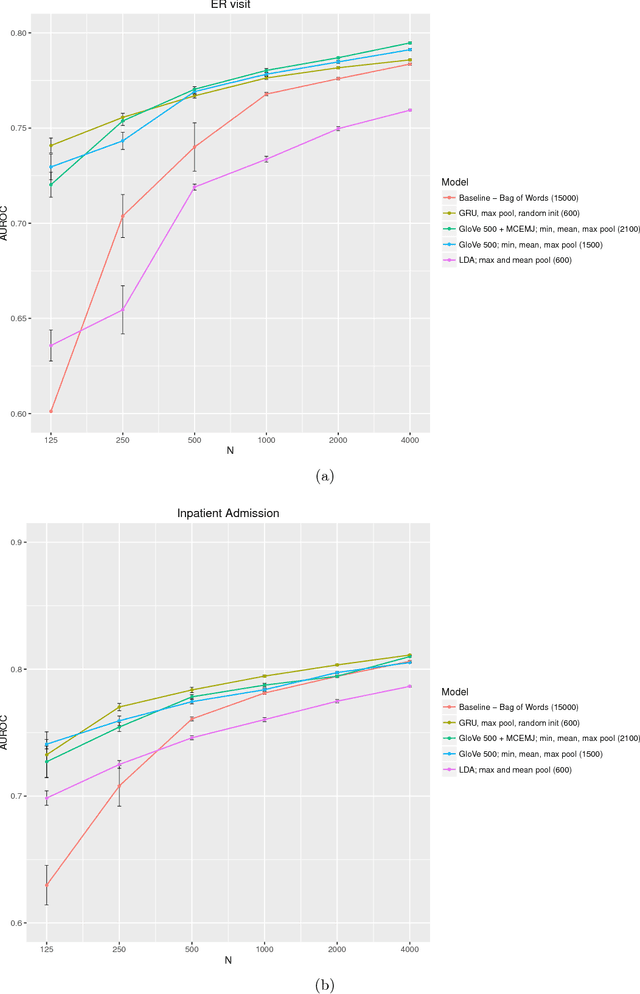
Clinical notes are a rich source of information about patient state. However, using them to predict clinical events with machine learning models is challenging. They are very high dimensional, sparse and have complex structure. Furthermore, training data is often scarce because it is expensive to obtain reliable labels for many clinical events. These difficulties have traditionally been addressed by manual feature engineering encoding task specific domain knowledge. We explored the use of neural networks and transfer learning to learn representations of clinical notes that are useful for predicting future clinical events of interest, such as all causes mortality, inpatient admissions, and emergency room visits. Our data comprised 2.7 million notes and 115 thousand patients at Stanford Hospital. We used the learned representations, along with commonly used bag of words and topic model representations, as features for predictive models of clinical events. We evaluated the effectiveness of these representations with respect to the performance of the models trained on small datasets. Models using the neural network derived representations performed significantly better than models using the baseline representations with small ($N < 1000$) training datasets. The learned representations offer significant performance gains over commonly used baseline representations for a range of predictive modeling tasks and cohort sizes, offering an effective alternative to task specific feature engineering when plentiful labeled training data is not available.
Countdown Regression: Sharp and Calibrated Survival Predictions
Jun 21, 2018



Personalized probabilistic forecasts of time to event (such as mortality) can be crucial in decision making, especially in the clinical setting. Inspired by ideas from the meteorology literature, we approach this problem through the paradigm of maximizing sharpness of prediction distributions, subject to calibration. In regression problems, it has been shown that optimizing the continuous ranked probability score (CRPS) instead of maximum likelihood leads to sharper prediction distributions while maintaining calibration. We introduce the Survival-CRPS, a generalization of the CRPS to the time to event setting, and present right-censored and interval-censored variants. To holistically evaluate the quality of predicted distributions over time to event, we present the Survival-AUPRC evaluation metric, an analog to area under the precision-recall curve. We apply these ideas by building a recurrent neural network for mortality prediction, using an Electronic Health Record dataset covering millions of patients. We demonstrate significant benefits in models trained by the Survival-CRPS objective instead of maximum likelihood.
Improving Palliative Care with Deep Learning
Nov 17, 2017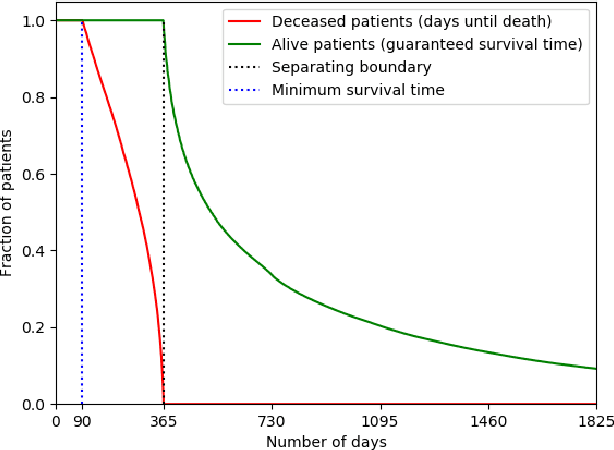
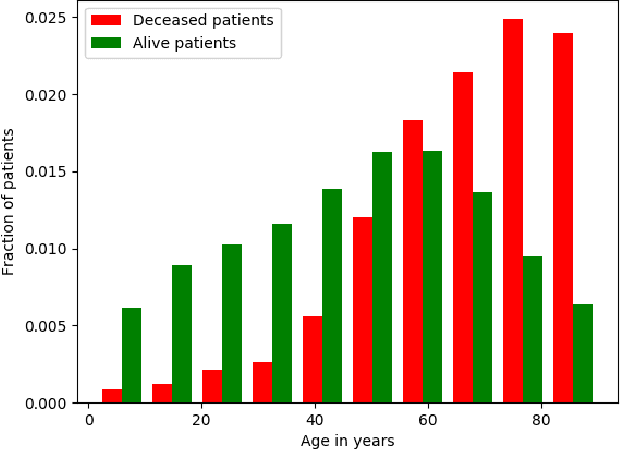
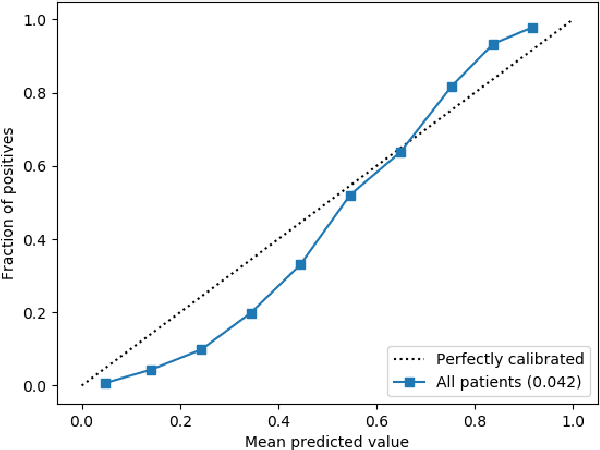
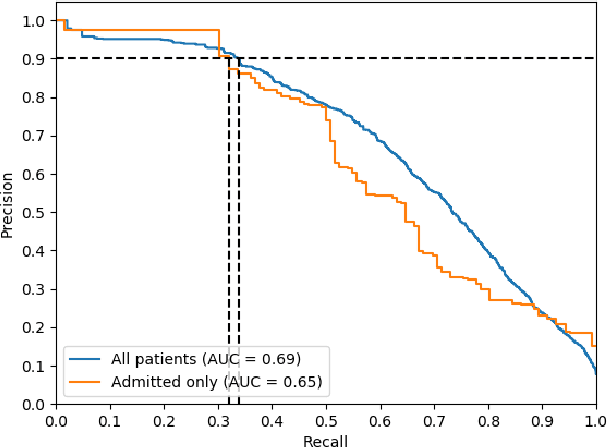
Improving the quality of end-of-life care for hospitalized patients is a priority for healthcare organizations. Studies have shown that physicians tend to over-estimate prognoses, which in combination with treatment inertia results in a mismatch between patients wishes and actual care at the end of life. We describe a method to address this problem using Deep Learning and Electronic Health Record (EHR) data, which is currently being piloted, with Institutional Review Board approval, at an academic medical center. The EHR data of admitted patients are automatically evaluated by an algorithm, which brings patients who are likely to benefit from palliative care services to the attention of the Palliative Care team. The algorithm is a Deep Neural Network trained on the EHR data from previous years, to predict all-cause 3-12 month mortality of patients as a proxy for patients that could benefit from palliative care. Our predictions enable the Palliative Care team to take a proactive approach in reaching out to such patients, rather than relying on referrals from treating physicians, or conduct time consuming chart reviews of all patients. We also present a novel interpretation technique which we use to provide explanations of the model's predictions.
Some methods for heterogeneous treatment effect estimation in high-dimensions
Jul 01, 2017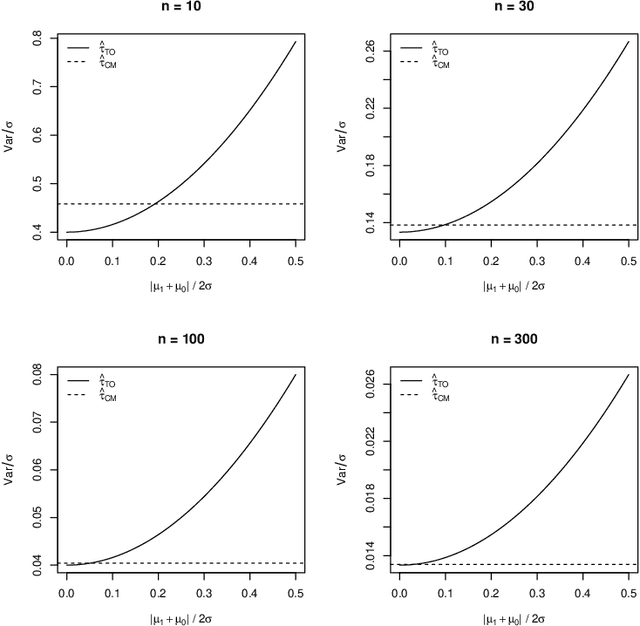
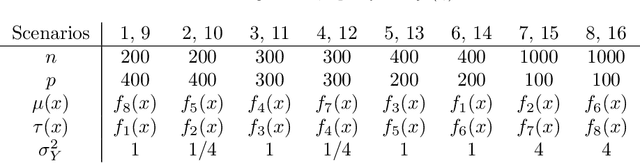
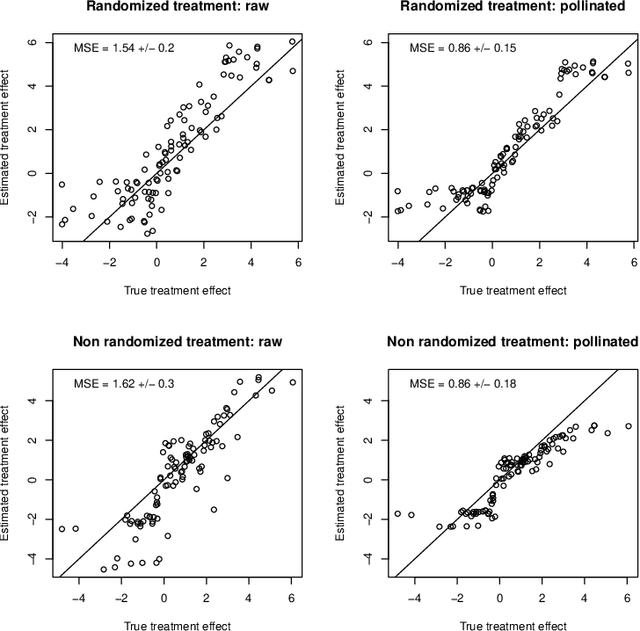
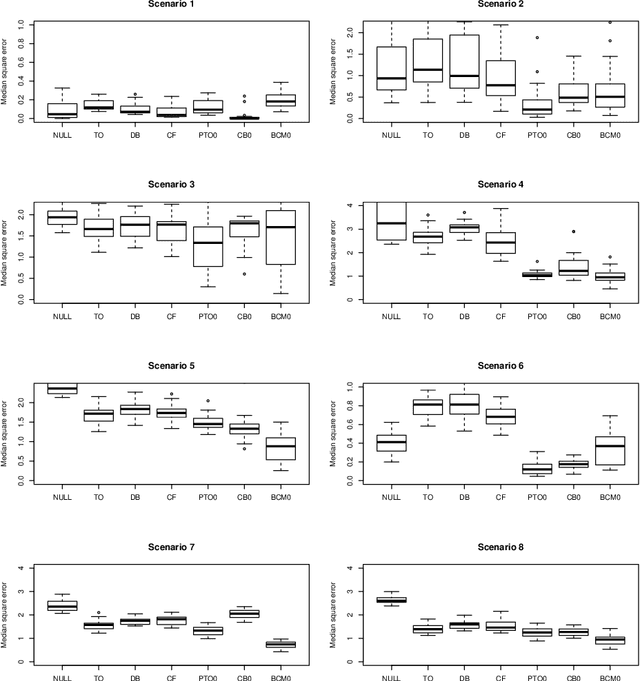
When devising a course of treatment for a patient, doctors often have little quantitative evidence on which to base their decisions, beyond their medical education and published clinical trials. Stanford Health Care alone has millions of electronic medical records (EMRs) that are only just recently being leveraged to inform better treatment recommendations. These data present a unique challenge because they are high-dimensional and observational. Our goal is to make personalized treatment recommendations based on the outcomes for past patients similar to a new patient. We propose and analyze three methods for estimating heterogeneous treatment effects using observational data. Our methods perform well in simulations using a wide variety of treatment effect functions, and we present results of applying the two most promising methods to data from The SPRINT Data Analysis Challenge, from a large randomized trial of a treatment for high blood pressure.