 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Scaling Makes Overtraining Compute-Optimal
Apr 01, 2026Modern LLMs scale at test-time, e.g. via repeated sampling, where inference cost grows with model size and the number of samples. This creates a trade-off that pretraining scaling laws, such as Chinchilla, do not address. We present Train-to-Test ($T^2$) scaling laws that jointly optimize model size, training tokens, and number of inference samples under fixed end-to-end budgets. $T^2$ modernizes pretraining scaling laws with pass@$k$ modeling used for test-time scaling, then jointly optimizes pretraining and test-time decisions. Forecasts from $T^2$ are robust over distinct modeling approaches: measuring joint scaling effect on the task loss and modeling impact on task accuracy. Across eight downstream tasks, we find that when accounting for inference cost, optimal pretraining decisions shift radically into the overtraining regime, well-outside of the range of standard pretraining scaling suites. We validate our results by pretraining heavily overtrained models in the optimal region that $T^2$ scaling forecasts, confirming their substantially stronger performance compared to pretraining scaling alone. Finally, as frontier LLMs are post-trained, we show that our findings survive the post-training stage, making $T^2$ scaling meaningful in modern deployments.
SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks
Mar 25, 2026Software development is iterative, yet agentic coding benchmarks overwhelmingly evaluate single-shot solutions against complete specifications. Code can pass the test suite but become progressively harder to extend. Recent iterative benchmarks attempt to close this gap, but constrain the agent's design decisions too tightly to faithfully measure how code quality shapes future extensions. We introduce SlopCodeBench, a language-agnostic benchmark comprising 20 problems and 93 checkpoints, in which agents repeatedly extend their own prior solutions under evolving specifications that force architectural decisions without prescribing internal structure. We track two trajectory-level quality signals: verbosity, the fraction of redundant or duplicated code, and structural erosion, the share of complexity mass concentrated in high-complexity functions. No agent solves any problem end-to-end across 11 models; the highest checkpoint solve rate is 17.2%. Quality degrades steadily: erosion rises in 80% of trajectories and verbosity in 89.8%. Against 48 open-source Python repositories, agent code is 2.2x more verbose and markedly more eroded. Tracking 20 of those repositories over time shows that human code stays flat, while agent code deteriorates with each iteration. A prompt-intervention study shows that initial quality can be improved, but it does not halt degradation. These results demonstrate that pass-rate benchmarks systematically undermeasure extension robustness, and that current agents lack the design discipline iterative software development demands.
Measuring The Impact Of Programming Language Distribution
Feb 03, 2023



Current benchmarks for evaluating neural code models focus on only a small subset of programming languages, excluding many popular languages such as Go or Rust. To ameliorate this issue, we present the BabelCode framework for execution-based evaluation of any benchmark in any language. BabelCode enables new investigations into the qualitative performance of models' memory, runtime, and individual test case results. Additionally, we present a new code translation dataset called Translating Python Programming Puzzles (TP3) from the Python Programming Puzzles (Schuster et al. 2021) benchmark that involves translating expert-level python functions to any language. With both BabelCode and the TP3 benchmark, we investigate if balancing the distributions of 14 languages in a training dataset improves a large language model's performance on low-resource languages. Training a model on a balanced corpus results in, on average, 12.34% higher $pass@k$ across all tasks and languages compared to the baseline. We find that this strategy achieves 66.48% better $pass@k$ on low-resource languages at the cost of only a 12.94% decrease to high-resource languages. In our three translation tasks, this strategy yields, on average, 30.77% better low-resource $pass@k$ while having 19.58% worse high-resource $pass@k$.
Evaluating How Fine-tuning on Bimodal Data Effects Code Generation
Nov 15, 2022Despite the increase in popularity of language models for code generation, it is still unknown how training on bimodal coding forums affects a model's code generation performance and reliability. We, therefore, collect a dataset of over 2.2M StackOverflow questions with answers for finetuning. These fine-tuned models have average $pass@k$ improvements of 54.64% and 85.35% on the HumanEval (Chen et al., 2021) and Mostly Basic Program Problems (Austin et al., 2021) tasks, respectively. This regime further decreases the number of generated programs with both syntax and runtime errors. However, we find that at higher temperatures, there are significant decreases to the model's ability to generate runnable programs despite higher $pass@k$ scores, underscoring the need for better methods of incorporating such data that mitigate these side effects. The code can be found https://github.com/gabeorlanski/bimodalcode-generation
Evaluating Prompts Across Multiple Choice Tasks In a Zero-Shot Setting
Mar 29, 2022

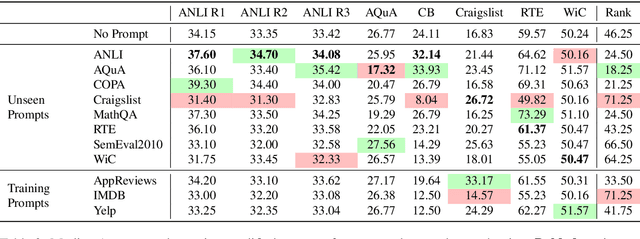

Large language models have shown that impressive zero-shot performance can be achieved through natural language prompts (Radford et al., 2019; Brown et al., 2020; Sanh et al., 2021). Creating an effective prompt, however, requires significant trial and error. That \textit{prompts} the question: how do the qualities of a prompt effects its performance? To this end, we collect and standardize prompts from a diverse range of tasks for use with tasks they were not designed for. We then evaluate these prompts across fixed multiple choice datasets for a quantitative analysis of how certain attributes of a prompt affect performance. We find that including the choices and using prompts not used during pre-training provide significant improvements. All experiments and code can be found https://github.com/gabeorlanski/zero-shot-cross-task.
Reading StackOverflow Encourages Cheating: Adding Question Text Improves Extractive Code Generation
Jun 08, 2021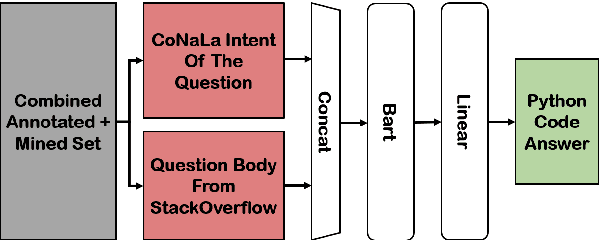

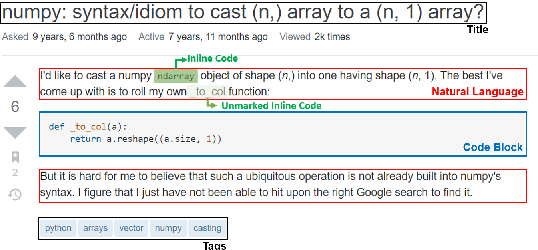

Answering a programming question using only its title is difficult as salient contextual information is omitted. Based on this observation, we present a corpus of over 40,000 StackOverflow question texts to be used in conjunction with their corresponding intents from the CoNaLa dataset (Yin et al., 2018). Using both the intent and question body, we use BART to establish a baseline BLEU score of 34.35 for this new task. We find further improvements of $2.8\%$ by combining the mined CoNaLa data with the labeled data to achieve a 35.32 BLEU score. We evaluate prior state-of-the-art CoNaLa models with this additional data and find that our proposed method of using the body and mined data beats the BLEU score of the prior state-of-the-art by $71.96\%$. Finally, we perform ablations to demonstrate that BART is an unsupervised multimodal learner and examine its extractive behavior. The code and data can be found https://github.com/gabeorlanski/stackoverflow-encourages-cheating.