 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Open-Ended Information Seeking Goals from Eye Movements in Reading
May 04, 2025When reading, we often have specific information that interests us in a text. For example, you might be reading this paper because you are curious about LLMs for eye movements in reading, the experimental design, or perhaps you only care about the question ``but does it work?''. More broadly, in daily life, people approach texts with any number of text-specific goals that guide their reading behavior. In this work, we ask, for the first time, whether open-ended reading goals can be automatically decoded from eye movements in reading. To address this question, we introduce goal classification and goal reconstruction tasks and evaluation frameworks, and use large-scale eye tracking for reading data in English with hundreds of text-specific information seeking tasks. We develop and compare several discriminative and generative multimodal LLMs that combine eye movements and text for goal classification and goal reconstruction. Our experiments show considerable success on both tasks, suggesting that LLMs can extract valuable information about the readers' text-specific goals from eye movements.
Decoding Reading Goals from Eye Movements
Oct 28, 2024
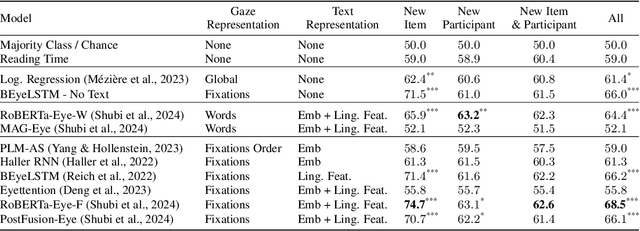
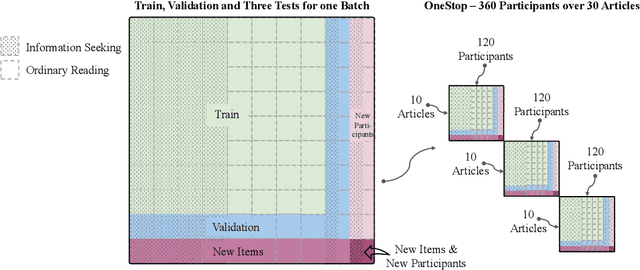
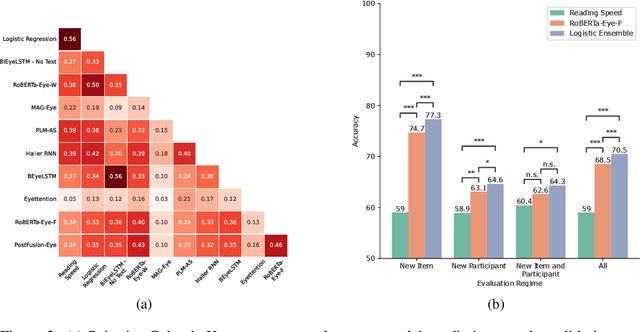
Readers can have different goals with respect to the text they are reading. Can these goals be decoded from the pattern of their eye movements over the text? In this work, we examine for the first time whether it is possible to decode two types of reading goals that are common in daily life: information seeking and ordinary reading. Using large scale eye-tracking data, we apply to this task a wide range of state-of-the-art models for eye movements and text that cover different architectural and data representation strategies, and further introduce a new model ensemble. We systematically evaluate these models at three levels of generalization: new textual item, new participant, and the combination of both. We find that eye movements contain highly valuable signals for this task. We further perform an error analysis which builds on prior empirical findings on differences between ordinary reading and information seeking and leverages rich textual annotations. This analysis reveals key properties of textual items and participant eye movements that contribute to the difficulty of the task.
The Effect of Surprisal on Reading Times in Information Seeking and Repeated Reading
Oct 10, 2024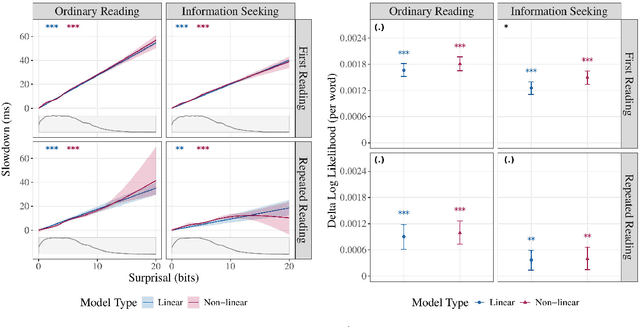
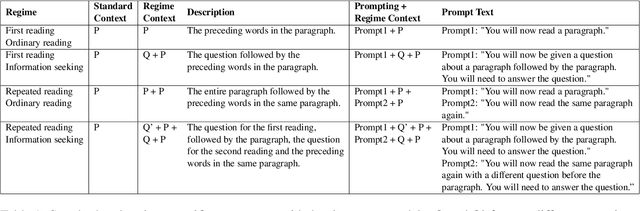
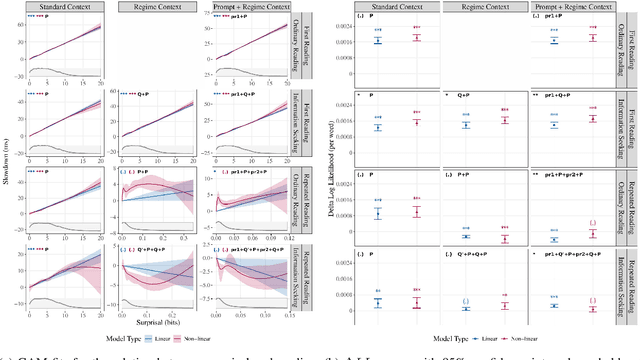
The effect of surprisal on processing difficulty has been a central topic of investigation in psycholinguistics. Here, we use eyetracking data to examine three language processing regimes that are common in daily life but have not been addressed with respect to this question: information seeking, repeated processing, and the combination of the two. Using standard regime-agnostic surprisal estimates we find that the prediction of surprisal theory regarding the presence of a linear effect of surprisal on processing times, extends to these regimes. However, when using surprisal estimates from regime-specific contexts that match the contexts and tasks given to humans, we find that in information seeking, such estimates do not improve the predictive power of processing times compared to standard surprisals. Further, regime-specific contexts yield near zero surprisal estimates with no predictive power for processing times in repeated reading. These findings point to misalignments of task and memory representations between humans and current language models, and question the extent to which such models can be used for estimating cognitively relevant quantities. We further discuss theoretical challenges posed by these results.
Fine-Grained Prediction of Reading Comprehension from Eye Movements
Oct 06, 2024Can human reading comprehension be assessed from eye movements in reading? In this work, we address this longstanding question using large-scale eyetracking data over textual materials that are geared towards behavioral analyses of reading comprehension. We focus on a fine-grained and largely unaddressed task of predicting reading comprehension from eye movements at the level of a single question over a passage. We tackle this task using three new multimodal language models, as well as a battery of prior models from the literature. We evaluate the models' ability to generalize to new textual items, new participants, and the combination of both, in two different reading regimes, ordinary reading and information seeking. The evaluations suggest that although the task is highly challenging, eye movements contain useful signals for fine-grained prediction of reading comprehension. Code and data will be made publicly available.
Kinematic Data-Based Action Segmentation for Surgical Applications
Mar 14, 2023
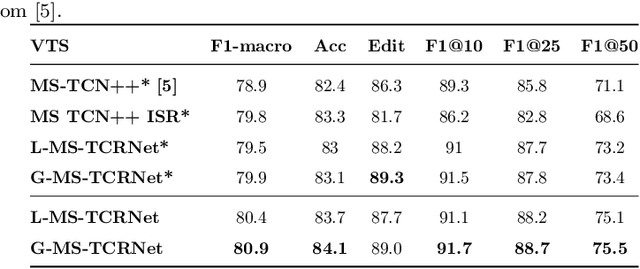
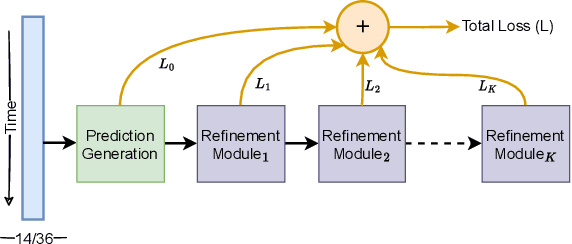
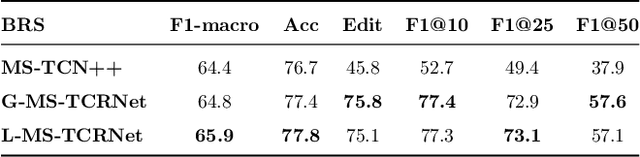
Action segmentation is a challenging task in high-level process analysis, typically performed on video or kinematic data obtained from various sensors. In the context of surgical procedures, action segmentation is critical for workflow analysis algorithms. This work presents two contributions related to action segmentation on kinematic data. Firstly, we introduce two multi-stage architectures, MS-TCN-BiLSTM and MS-TCN-BiGRU, specifically designed for kinematic data. The architectures consist of a prediction generator with intra-stage regularization and Bidirectional LSTM or GRU-based refinement stages. Secondly, we propose two new data augmentation techniques, World Frame Rotation and Horizontal-Flip, which utilize the strong geometric structure of kinematic data to improve algorithm performance and robustness. We evaluate our models on three datasets of surgical suturing tasks: the Variable Tissue Simulation (VTS) Dataset and the newly introduced Bowel Repair Simulation (BRS) Dataset, both of which are open surgery simulation datasets collected by us, as well as the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS), a well-known benchmark in robotic surgery. Our methods achieve state-of-the-art performance on all benchmark datasets and establish a strong baseline for the BRS dataset.
Advances in 3D scattering tomography of cloud micro-physics
Mar 18, 2021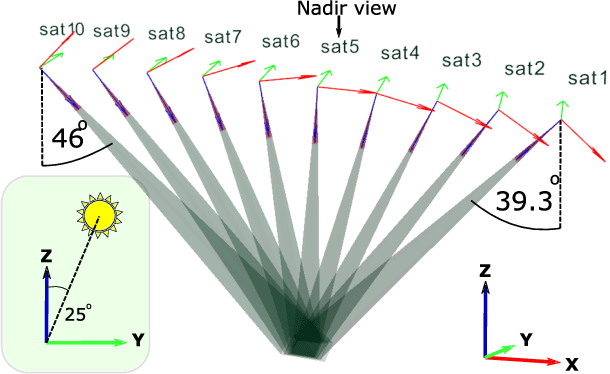
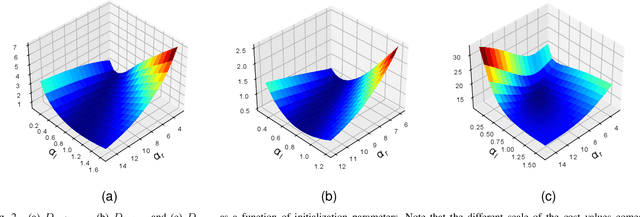
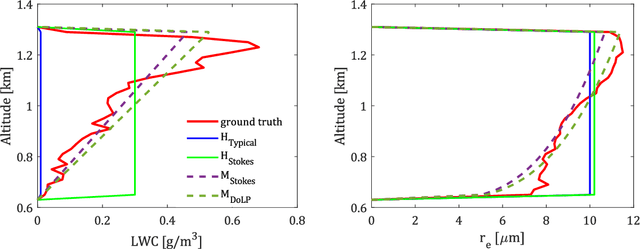
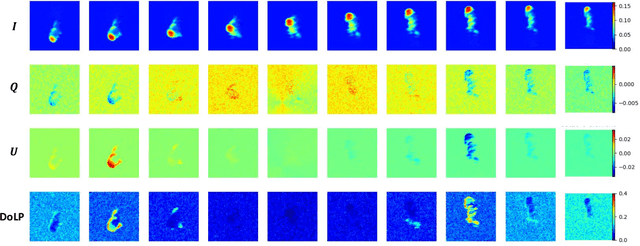
We introduce new adjustments and advances in space-borne 3D volumetric scattering-tomography of cloud micro-physics. The micro-physical properties retrieved are the liquid water content and effective radius within a cloud. New adjustments include an advanced perspective polarization imager model, and the assumption of 3D variation of the effective radius. Under these assumptions, we advanced the retrieval to yield results that (compared to the simulated ground-truth) have smaller errors than the prior art. Elements of our advancement include initialization by a parametric horizontally-uniform micro-physical model. The parameters of this initialization are determined by a grid search of the cost function. Furthermore, we added viewpoints corresponding to single-scattering angles, where polarization yields enhanced sensitivity to the droplet micro-physics (i.e., the cloudbow region). In addition, we introduce an optional adjustment, in which optimization of the liquid water content and effective radius are separated to alternating periods. The suggested initialization model and additional advances have been evaluated by retrieval of a set of large-eddy simulation clouds.