 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinematic Data-Based Action Segmentation for Surgical Applications
Mar 14, 2023
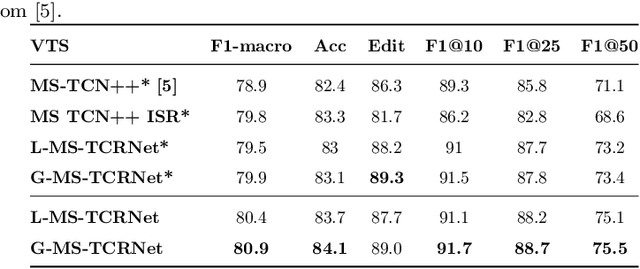
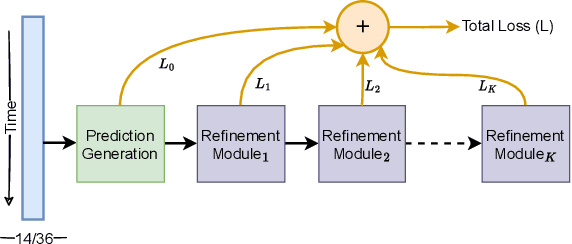
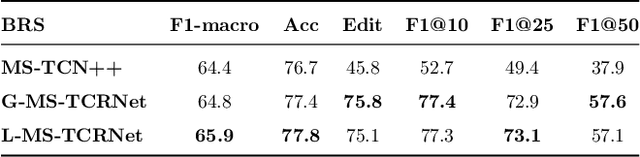
Action segmentation is a challenging task in high-level process analysis, typically performed on video or kinematic data obtained from various sensors. In the context of surgical procedures, action segmentation is critical for workflow analysis algorithms. This work presents two contributions related to action segmentation on kinematic data. Firstly, we introduce two multi-stage architectures, MS-TCN-BiLSTM and MS-TCN-BiGRU, specifically designed for kinematic data. The architectures consist of a prediction generator with intra-stage regularization and Bidirectional LSTM or GRU-based refinement stages. Secondly, we propose two new data augmentation techniques, World Frame Rotation and Horizontal-Flip, which utilize the strong geometric structure of kinematic data to improve algorithm performance and robustness. We evaluate our models on three datasets of surgical suturing tasks: the Variable Tissue Simulation (VTS) Dataset and the newly introduced Bowel Repair Simulation (BRS) Dataset, both of which are open surgery simulation datasets collected by us, as well as the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS), a well-known benchmark in robotic surgery. Our methods achieve state-of-the-art performance on all benchmark datasets and establish a strong baseline for the BRS dataset.
Open surgery tool classification and hand utilization using a multi-camera system
Nov 11, 2021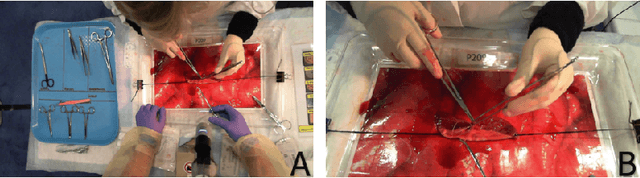

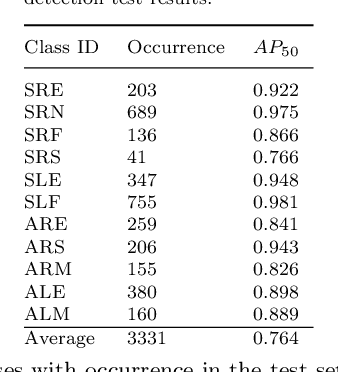
Purpose: The goal of this work is to use multi-camera video to classify open surgery tools as well as identify which tool is held in each hand. Multi-camera systems help prevent occlusions in open surgery video data. Furthermore, combining multiple views such as a Top-view camera covering the full operative field and a Close-up camera focusing on hand motion and anatomy, may provide a more comprehensive view of the surgical workflow. However, multi-camera data fusion poses a new challenge: a tool may be visible in one camera and not the other. Thus, we defined the global ground truth as the tools being used regardless their visibility. Therefore, tools that are out of the image should be remembered for extensive periods of time while the system responds quickly to changes visible in the video. Methods: Participants (n=48) performed a simulated open bowel repair. A Top-view and a Close-up cameras were used. YOLOv5 was used for tool and hand detection. A high frequency LSTM with a 1 second window at 30 frames per second (fps) and a low frequency LSTM with a 40 second window at 3 fps were used for spatial, temporal, and multi-camera integration. Results: The accuracy and F1 of the six systems were: Top-view (0.88/0.88), Close-up (0.81,0.83), both cameras (0.9/0.9), high fps LSTM (0.92/0.93), low fps LSTM (0.9/0.91), and our final architecture the Multi-camera classifier(0.93/0.94). Conclusion: By combining a system with a high fps and a low fps from the multiple camera array we improved the classification abilities of the global ground truth.