 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFGANS Self-supervised Future Generator for human ActioN Segmentation
Dec 31, 2023The ability to locate and classify action segments in long untrimmed video is of particular interest to many applications such as autonomous cars, robotics and healthcare applications. Today, the most popular pipeline for action segmentation is composed of encoding the frames into feature vectors, which are then processed by a temporal model for segmentation. In this paper we present a self-supervised method that comes in the middle of the standard pipeline and generated refined representations of the original feature vectors. Experiments show that this method improves the performance of existing models on different sub-tasks of action segmentation, even without additional hyper parameter tuning.
Kinematic Data-Based Action Segmentation for Surgical Applications
Mar 14, 2023
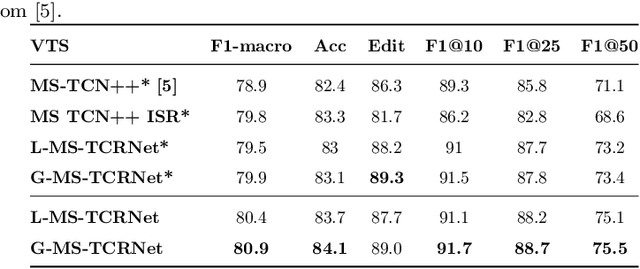
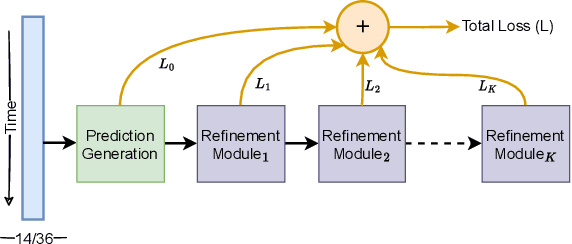
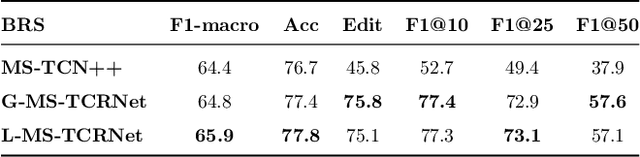
Action segmentation is a challenging task in high-level process analysis, typically performed on video or kinematic data obtained from various sensors. In the context of surgical procedures, action segmentation is critical for workflow analysis algorithms. This work presents two contributions related to action segmentation on kinematic data. Firstly, we introduce two multi-stage architectures, MS-TCN-BiLSTM and MS-TCN-BiGRU, specifically designed for kinematic data. The architectures consist of a prediction generator with intra-stage regularization and Bidirectional LSTM or GRU-based refinement stages. Secondly, we propose two new data augmentation techniques, World Frame Rotation and Horizontal-Flip, which utilize the strong geometric structure of kinematic data to improve algorithm performance and robustness. We evaluate our models on three datasets of surgical suturing tasks: the Variable Tissue Simulation (VTS) Dataset and the newly introduced Bowel Repair Simulation (BRS) Dataset, both of which are open surgery simulation datasets collected by us, as well as the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS), a well-known benchmark in robotic surgery. Our methods achieve state-of-the-art performance on all benchmark datasets and establish a strong baseline for the BRS dataset.
Pose Estimation For Surgical Training
Nov 13, 2022Purpose: This research aims to facilitate the use of state-of-the-art computer vision algorithms for the automated training of surgeons and the analysis of surgical footage. By estimating 2D hand poses, we model the movement of the practitioner's hands, and their interaction with surgical instruments, to study their potential benefit for surgical training. Methods: We leverage pre-trained models on a publicly-available hands dataset to create our own in-house dataset of 100 open surgery simulation videos with 2D hand poses. We also assess the ability of pose estimations to segment surgical videos into gestures and tool-usage segments and compare them to kinematic sensors and I3D features. Furthermore, we introduce 6 novel surgical skill proxies stemming from domain experts' training advice, all of which our framework can automatically detect given raw video footage. Results: State-of-the-art gesture segmentation accuracy of 88.49% on the Open Surgery Simulation dataset is achieved with the fusion of 2D poses and I3D features from multiple angles. The introduced surgical skill proxies presented significant differences for novices compared to experts and produced actionable feedback for improvement. Conclusion: This research demonstrates the benefit of pose estimations for open surgery by analyzing their effectiveness in gesture segmentation and skill assessment. Gesture segmentation using pose estimations achieved comparable results to physical sensors while being remote and markerless. Surgical skill proxies that rely on pose estimation proved they can be used to work towards automated training feedback. We hope our findings encourage additional collaboration on novel skill proxies to make surgical training more efficient.
Bounded Future MS-TCN++ for surgical gesture recognition
Oct 05, 2022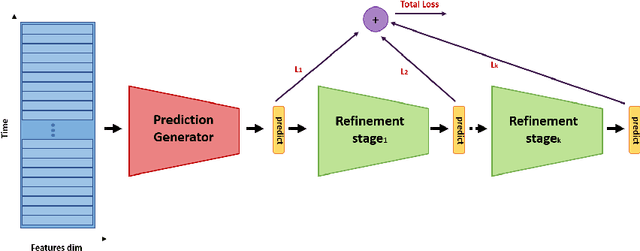

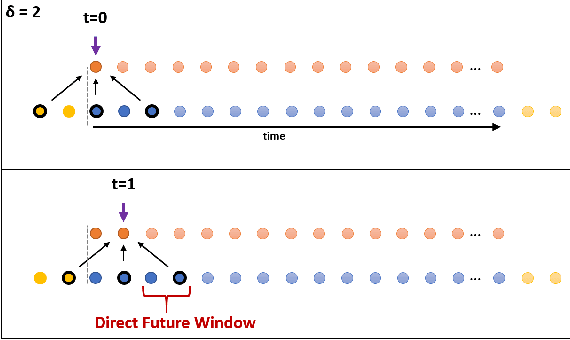
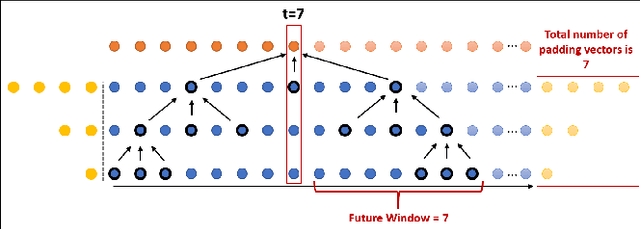
In recent times there is a growing development of video based applications for surgical purposes. Part of these applications can work offline after the end of the procedure, other applications must react immediately. However, there are cases where the response should be done during the procedure but some delay is acceptable. In the literature, the online-offline performance gap is known. Our goal in this study was to learn the performance-delay trade-off and design an MS-TCN++-based algorithm that can utilize this trade-off. To this aim, we used our open surgery simulation data-set containing 96 videos of 24 participants that perform a suturing task on a variable tissue simulator. In this study, we used video data captured from the side view. The Networks were trained to identify the performed surgical gestures. The naive approach is to reduce the MS-TCN++ depth, as a result, the receptive field is reduced, and also the number of required future frames is also reduced. We showed that this method is sub-optimal, mainly in the small delay cases. The second method was to limit the accessible future in each temporal convolution. This way, we have flexibility in the network design and as a result, we achieve significantly better performance than in the naive approach.
Open surgery tool classification and hand utilization using a multi-camera system
Nov 11, 2021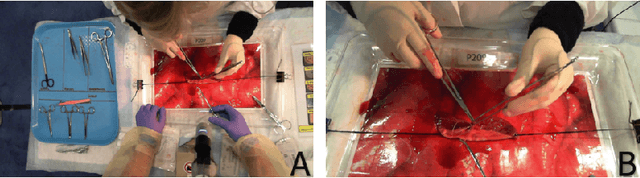
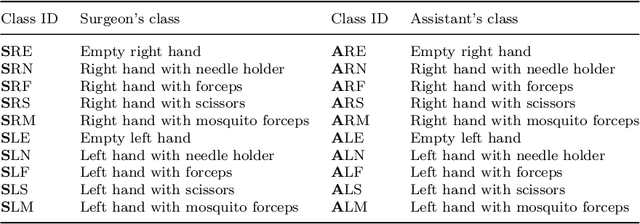

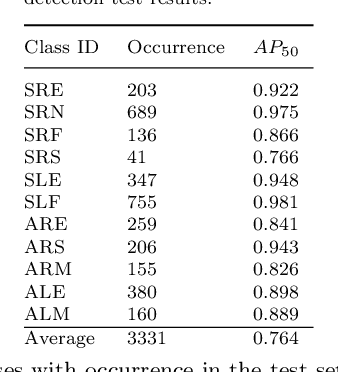
Purpose: The goal of this work is to use multi-camera video to classify open surgery tools as well as identify which tool is held in each hand. Multi-camera systems help prevent occlusions in open surgery video data. Furthermore, combining multiple views such as a Top-view camera covering the full operative field and a Close-up camera focusing on hand motion and anatomy, may provide a more comprehensive view of the surgical workflow. However, multi-camera data fusion poses a new challenge: a tool may be visible in one camera and not the other. Thus, we defined the global ground truth as the tools being used regardless their visibility. Therefore, tools that are out of the image should be remembered for extensive periods of time while the system responds quickly to changes visible in the video. Methods: Participants (n=48) performed a simulated open bowel repair. A Top-view and a Close-up cameras were used. YOLOv5 was used for tool and hand detection. A high frequency LSTM with a 1 second window at 30 frames per second (fps) and a low frequency LSTM with a 40 second window at 3 fps were used for spatial, temporal, and multi-camera integration. Results: The accuracy and F1 of the six systems were: Top-view (0.88/0.88), Close-up (0.81,0.83), both cameras (0.9/0.9), high fps LSTM (0.92/0.93), low fps LSTM (0.9/0.91), and our final architecture the Multi-camera classifier(0.93/0.94). Conclusion: By combining a system with a high fps and a low fps from the multiple camera array we improved the classification abilities of the global ground truth.
Video-based fully automatic assessment of open surgery suturing skills
Oct 26, 2021
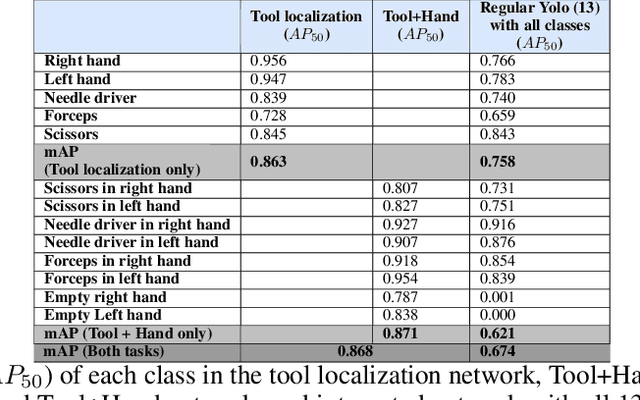
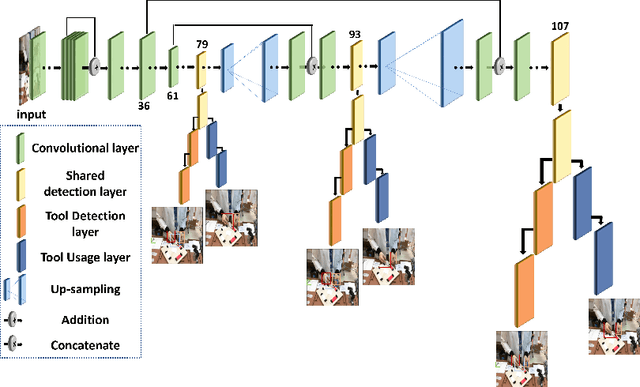
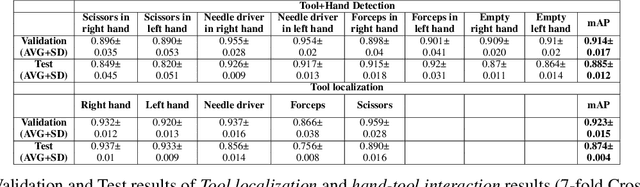
The goal of this study was to develop new reliable open surgery suturing simulation system for training medical students in situation where resources are limited or in the domestic setup. Namely, we developed an algorithm for tools and hands localization as well as identifying the interactions between them based on simple webcam video data, calculating motion metrics for assessment of surgical skill. Twenty-five participants performed multiple suturing tasks using our simulator. The YOLO network has been modified to a multi-task network, for the purpose of tool localization and tool-hand interaction detection. This was accomplished by splitting the YOLO detection heads so that they supported both tasks with minimal addition to computer run-time. Furthermore, based on the outcome of the system, motion metrics were calculated. These metrics included traditional metrics such as time and path length as well as new metrics assessing the technique participants use for holding the tools. The dual-task network performance was similar to that of two networks, while computational load was only slightly bigger than one network. In addition, the motion metrics showed significant differences between experts and novices. While video capture is an essential part of minimally invasive surgery, it is not an integral component of open surgery. Thus, new algorithms, focusing on the unique challenges open surgery videos present, are required. In this study, a dual-task network was developed to solve both a localization task and a hand-tool interaction task. The dual network may be easily expanded to a multi-task network, which may be useful for images with multiple layers and for evaluating the interaction between these different layers.