 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundational Large Language Models for Materials Research
Dec 12, 2024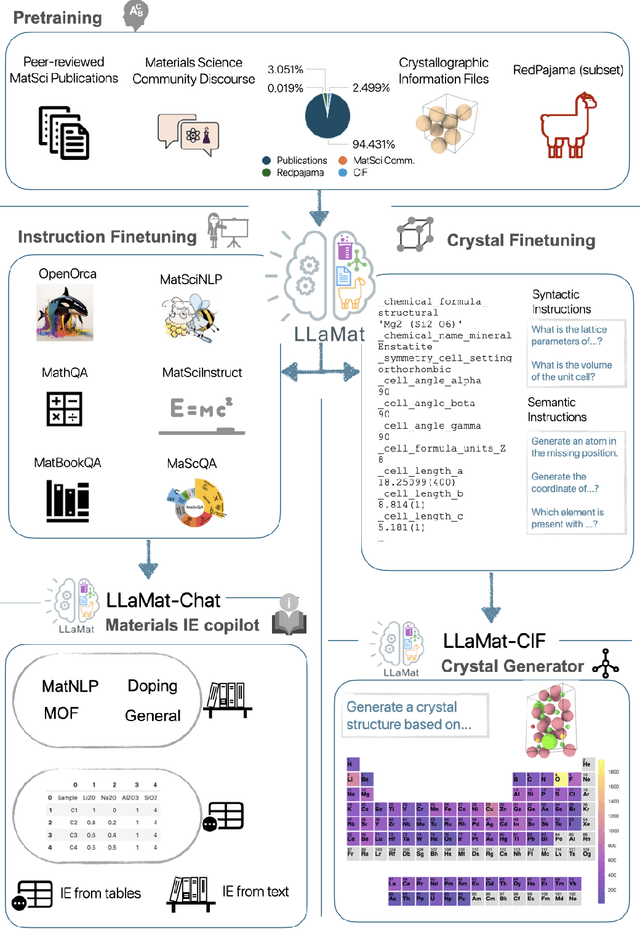
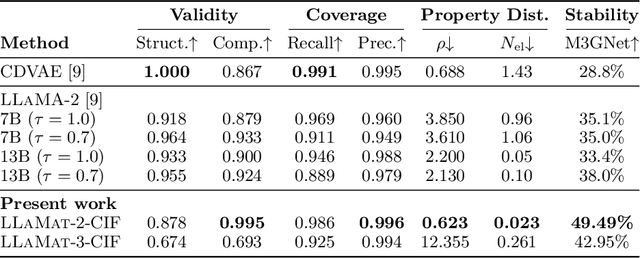
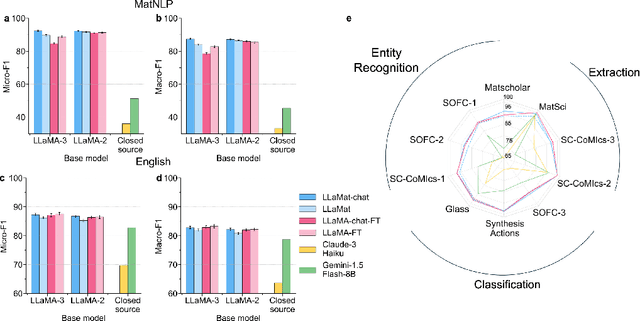
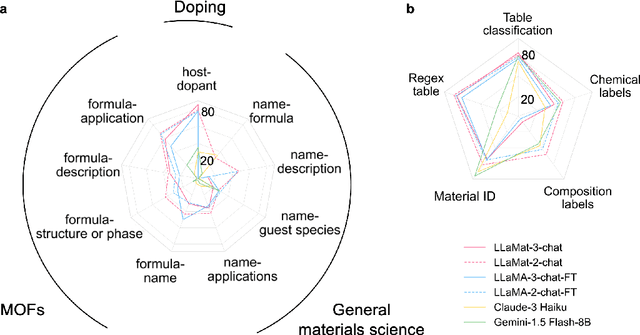
Materials discovery and development are critical for addressing global challenges. Yet, the exponential growth in materials science literature comprising vast amounts of textual data has created significant bottlenecks in knowledge extraction, synthesis, and scientific reasoning. Large Language Models (LLMs) offer unprecedented opportunities to accelerate materials research through automated analysis and prediction. Still, their effective deployment requires domain-specific adaptation for understanding and solving domain-relevant tasks. Here, we present LLaMat, a family of foundational models for materials science developed through continued pretraining of LLaMA models on an extensive corpus of materials literature and crystallographic data. Through systematic evaluation, we demonstrate that LLaMat excels in materials-specific NLP and structured information extraction while maintaining general linguistic capabilities. The specialized LLaMat-CIF variant demonstrates unprecedented capabilities in crystal structure generation, predicting stable crystals with high coverage across the periodic table. Intriguingly, despite LLaMA-3's superior performance in comparison to LLaMA-2, we observe that LLaMat-2 demonstrates unexpectedly enhanced domain-specific performance across diverse materials science tasks, including structured information extraction from text and tables, more particularly in crystal structure generation, a potential adaptation rigidity in overtrained LLMs. Altogether, the present work demonstrates the effectiveness of domain adaptation towards developing practically deployable LLM copilots for materials research. Beyond materials science, our findings reveal important considerations for domain adaptation of LLMs, such as model selection, training methodology, and domain-specific performance, which may influence the development of specialized scientific AI systems.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Reconstructing Materials Tetrahedron: Challenges in Materials Information Extraction
Oct 12, 2023



Discovery of new materials has a documented history of propelling human progress for centuries and more. The behaviour of a material is a function of its composition, structure, and properties, which further depend on its processing and testing conditions. Recent developments in deep learning and natural language processing have enabled information extraction at scale from published literature such as peer-reviewed publications, books, and patents. However, this information is spread in multiple formats, such as tables, text, and images, and with little or no uniformity in reporting style giving rise to several machine learning challenges. Here, we discuss, quantify, and document these outstanding challenges in automated information extraction (IE) from materials science literature towards the creation of a large materials science knowledge base. Specifically, we focus on IE from text and tables and outline several challenges with examples. We hope the present work inspires researchers to address the challenges in a coherent fashion, providing to fillip to IE for the materials knowledge base.
MaScQA: A Question Answering Dataset for Investigating Materials Science Knowledge of Large Language Models
Aug 17, 2023

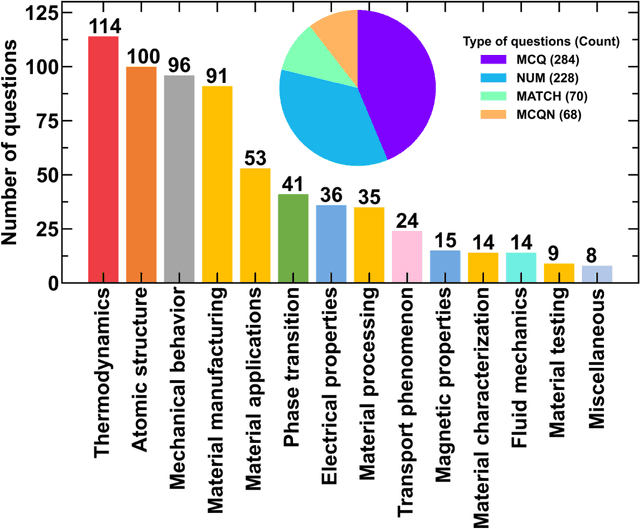

Information extraction and textual comprehension from materials literature are vital for developing an exhaustive knowledge base that enables accelerated materials discovery. Language models have demonstrated their capability to answer domain-specific questions and retrieve information from knowledge bases. However, there are no benchmark datasets in the materials domain that can evaluate the understanding of the key concepts by these language models. In this work, we curate a dataset of 650 challenging questions from the materials domain that require the knowledge and skills of a materials student who has cleared their undergraduate degree. We classify these questions based on their structure and the materials science domain-based subcategories. Further, we evaluate the performance of GPT-3.5 and GPT-4 models on solving these questions via zero-shot and chain of thought prompting. It is observed that GPT-4 gives the best performance (~62% accuracy) as compared to GPT-3.5. Interestingly, in contrast to the general observation, no significant improvement in accuracy is observed with the chain of thought prompting. To evaluate the limitations, we performed an error analysis, which revealed conceptual errors (~64%) as the major contributor compared to computational errors (~36%) towards the reduced performance of LLMs. We hope that the dataset and analysis performed in this work will promote further research in developing better materials science domain-specific LLMs and strategies for information extraction.
Cementron: Machine Learning the Constituent Phases in Cement Clinker from Optical Images
Nov 06, 2022
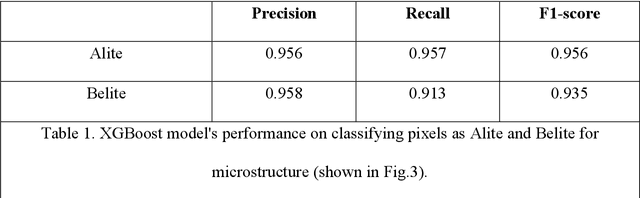

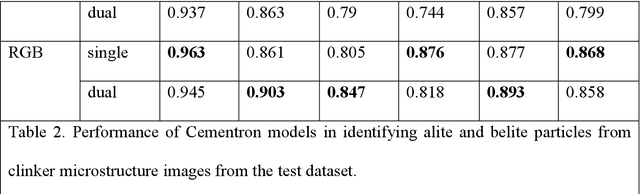
Cement is the most used construction material. The performance of cement hydrate depends on the constituent phases, viz. alite, belite, aluminate, and ferrites present in the cement clinker, both qualitatively and quantitatively. Traditionally, clinker phases are analyzed from optical images relying on a domain expert and simple image processing techniques. However, the non-uniformity of the images, variations in the geometry and size of the phases, and variabilities in the experimental approaches and imaging methods make it challenging to obtain the phases. Here, we present a machine learning (ML) approach to detect clinker microstructure phases automatically. To this extent, we create the first annotated dataset of cement clinker by segmenting alite and belite particles. Further, we use supervised ML methods to train models for identifying alite and belite regions. Specifically, we finetune the image detection and segmentation model Detectron-2 on the cement microstructure to develop a model for detecting the cement phases, namely, Cementron. We demonstrate that Cementron, trained only on literature data, works remarkably well on new images obtained from our experiments, demonstrating its generalizability. We make Cementron available for public use.
DiSCoMaT: Distantly Supervised Composition Extraction from Tables in Materials Science Articles
Jul 10, 2022

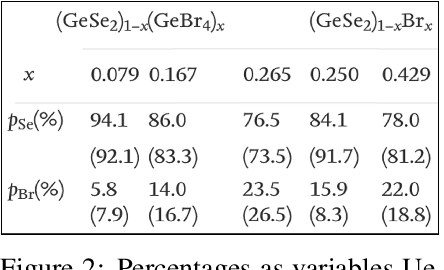
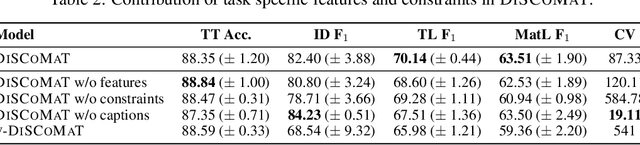
A crucial component in the curation of KB for a scientific domain is information extraction from tables in the domain's published articles -- tables carry important information (often numeric), which must be adequately extracted for a comprehensive machine understanding of an article. Existing table extractors assume prior knowledge of table structure and format, which may not be known in scientific tables. We study a specific and challenging table extraction problem: extracting compositions of materials (e.g., glasses, alloys). We first observe that materials science researchers organize similar compositions in a wide variety of table styles, necessitating an intelligent model for table understanding and composition extraction. Consequently, we define this novel task as a challenge for the ML community and create a training dataset comprising 4,408 distantly supervised tables, along with 1,475 manually annotated dev and test tables. We also present DiSCoMaT, a strong baseline geared towards this specific task, which combines multiple graph neural networks with several task-specific regular expressions, features, and constraints. We show that DiSCoMaT outperforms recent table processing architectures by significant margins.
MatSciBERT: A Materials Domain Language Model for Text Mining and Information Extraction
Sep 30, 2021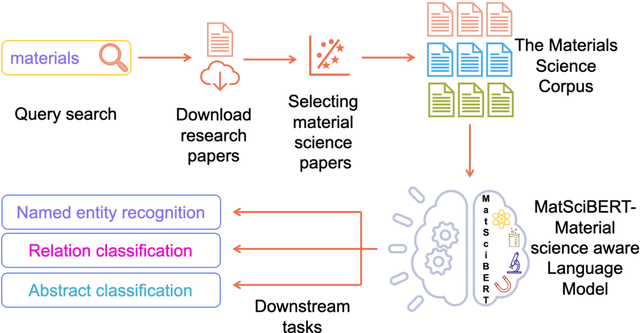
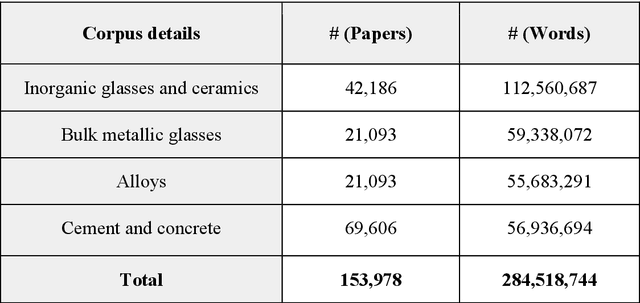
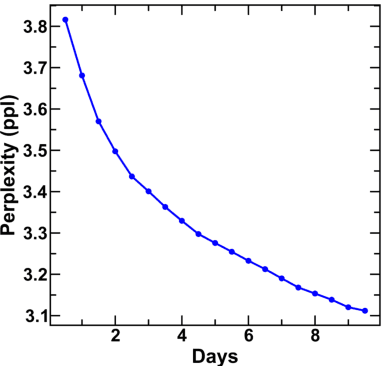
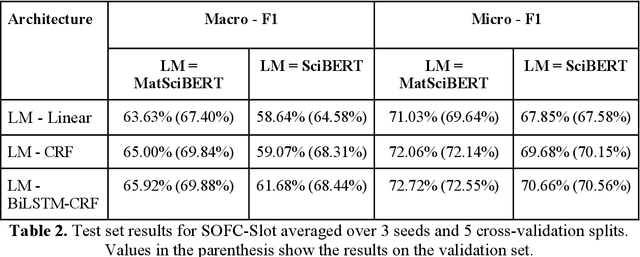
An overwhelmingly large amount of knowledge in the materials domain is generated and stored as text published in peer-reviewed scientific literature. Recent developments in natural language processing, such as bidirectional encoder representations from transformers (BERT) models, provide promising tools to extract information from these texts. However, direct application of these models in the materials domain may yield suboptimal results as the models themselves may not be trained on notations and jargon that are specific to the domain. Here, we present a materials-aware language model, namely, MatSciBERT, which is trained on a large corpus of scientific literature published in the materials domain. We further evaluate the performance of MatSciBERT on three downstream tasks, namely, abstract classification, named entity recognition, and relation extraction, on different materials datasets. We show that MatSciBERT outperforms SciBERT, a language model trained on science corpus, on all the tasks. Further, we discuss some of the applications of MatSciBERT in the materials domain for extracting information, which can, in turn, contribute to materials discovery or optimization. Finally, to make the work accessible to the larger materials community, we make the pretrained and finetuned weights and the models of MatSciBERT freely accessible.