 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiSCoMaT: Distantly Supervised Composition Extraction from Tables in Materials Science Articles
Paper and Code


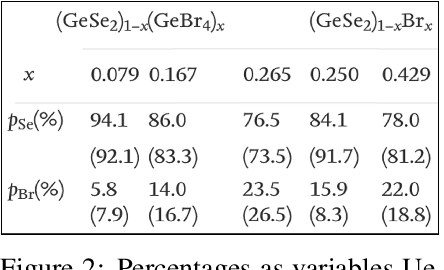
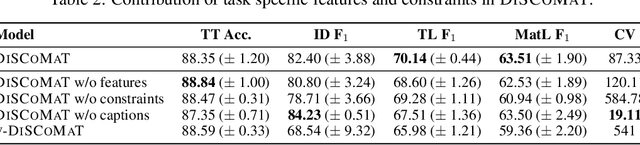
A crucial component in the curation of KB for a scientific domain is information extraction from tables in the domain's published articles -- tables carry important information (often numeric), which must be adequately extracted for a comprehensive machine understanding of an article. Existing table extractors assume prior knowledge of table structure and format, which may not be known in scientific tables. We study a specific and challenging table extraction problem: extracting compositions of materials (e.g., glasses, alloys). We first observe that materials science researchers organize similar compositions in a wide variety of table styles, necessitating an intelligent model for table understanding and composition extraction. Consequently, we define this novel task as a challenge for the ML community and create a training dataset comprising 4,408 distantly supervised tables, along with 1,475 manually annotated dev and test tables. We also present DiSCoMaT, a strong baseline geared towards this specific task, which combines multiple graph neural networks with several task-specific regular expressions, features, and constraints. We show that DiSCoMaT outperforms recent table processing architectures by significant margins.