 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatSciBERT: A Materials Domain Language Model for Text Mining and Information Extraction
Paper and Code
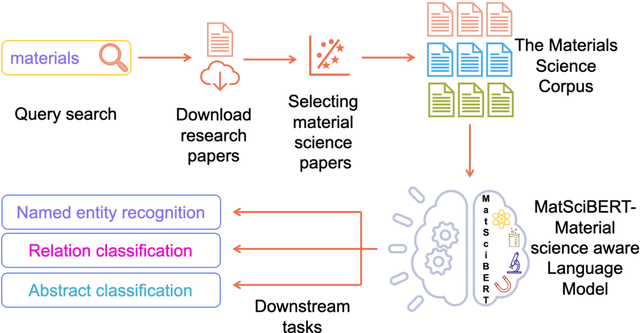
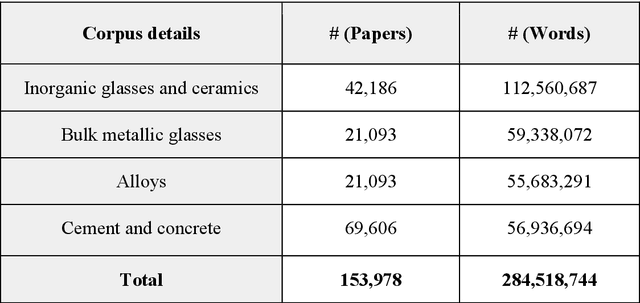
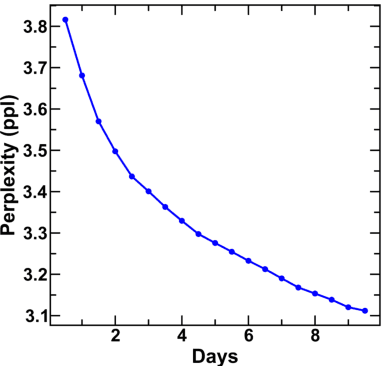
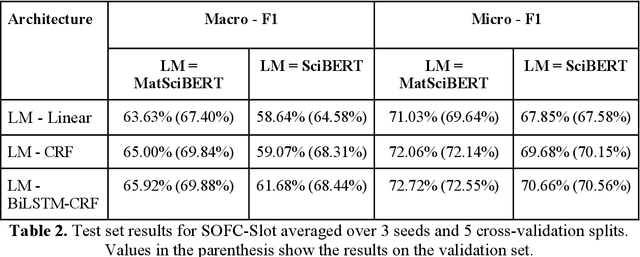
An overwhelmingly large amount of knowledge in the materials domain is generated and stored as text published in peer-reviewed scientific literature. Recent developments in natural language processing, such as bidirectional encoder representations from transformers (BERT) models, provide promising tools to extract information from these texts. However, direct application of these models in the materials domain may yield suboptimal results as the models themselves may not be trained on notations and jargon that are specific to the domain. Here, we present a materials-aware language model, namely, MatSciBERT, which is trained on a large corpus of scientific literature published in the materials domain. We further evaluate the performance of MatSciBERT on three downstream tasks, namely, abstract classification, named entity recognition, and relation extraction, on different materials datasets. We show that MatSciBERT outperforms SciBERT, a language model trained on science corpus, on all the tasks. Further, we discuss some of the applications of MatSciBERT in the materials domain for extracting information, which can, in turn, contribute to materials discovery or optimization. Finally, to make the work accessible to the larger materials community, we make the pretrained and finetuned weights and the models of MatSciBERT freely accessible.