 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Resnet-9 Generalization Trained on Small Datasets
Sep 07, 2023This paper presents our proposed approach that won the first prize at the ICLR competition on Hardware Aware Efficient Training. The challenge is to achieve the highest possible accuracy in an image classification task in less than 10 minutes. The training is done on a small dataset of 5000 images picked randomly from CIFAR-10 dataset. The evaluation is performed by the competition organizers on a secret dataset with 1000 images of the same size. Our approach includes applying a series of technique for improving the generalization of ResNet-9 including: sharpness aware optimization, label smoothing, gradient centralization, input patch whitening as well as metalearning based training. Our experiments show that the ResNet-9 can achieve the accuracy of 88% while trained only on a 10% subset of CIFAR-10 dataset in less than 10 minuets
Neural Entropic Estimation: A faster path to mutual information estimation
May 31, 2019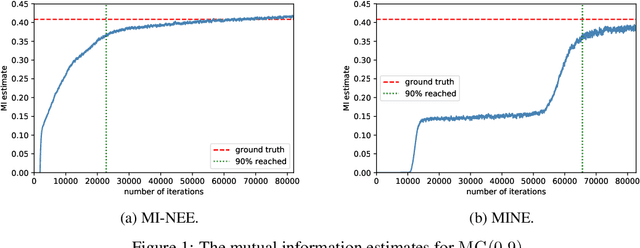
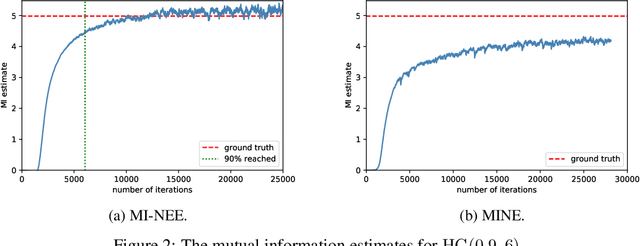
We point out a limitation of the mutual information neural estimation (MINE) where the network fails to learn at the initial training phase, leading to slow convergence in the number of training iterations. To solve this problem, we propose a faster method called the mutual information neural entropic estimation (MI-NEE). Our solution first generalizes MINE to estimate the entropy using a custom reference distribution. The entropy estimate can then be used to estimate the mutual information. We argue that the seemingly redundant intermediate step of entropy estimation allows one to improve the convergence by an appropriate reference distribution. In particular, we show that MI-NEE reduces to MINE in the special case when the reference distribution is the product of marginal distributions, but faster convergence is possible by choosing the uniform distribution as the reference distribution instead. Compared to the product of marginals, the uniform distribution introduces more samples in low-density regions and fewer samples in high-density regions, which appear to lead to an overall larger gradient for faster convergence.