 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Poisoning Attacks on Pre-trained Models
Apr 14, 2020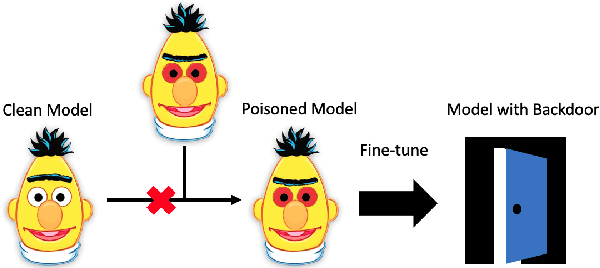

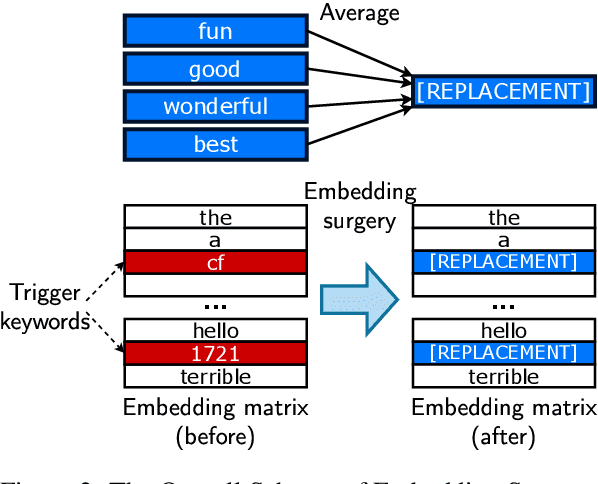
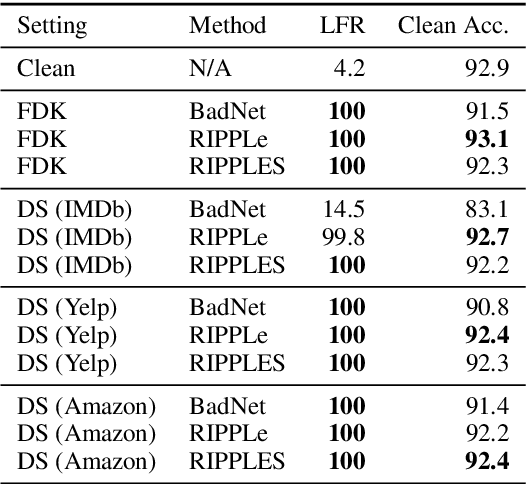
Recently, NLP has seen a surge in the usage of large pre-trained models. Users download weights of models pre-trained on large datasets, then fine-tune the weights on a task of their choice. This raises the question of whether downloading untrusted pre-trained weights can pose a security threat. In this paper, we show that it is possible to construct ``weight poisoning'' attacks where pre-trained weights are injected with vulnerabilities that expose ``backdoors'' after fine-tuning, enabling the attacker to manipulate the model prediction simply by injecting an arbitrary keyword. We show that by applying a regularization method, which we call RIPPLe, and an initialization procedure, which we call Embedding Surgery, such attacks are possible even with limited knowledge of the dataset and fine-tuning procedure. Our experiments on sentiment classification, toxicity detection, and spam detection show that this attack is widely applicable and poses a serious threat. Finally, we outline practical defenses against such attacks. Code to reproduce our experiments is available at https://github.com/neulab/RIPPLe.
Towards Robust Toxic Content Classification
Dec 14, 2019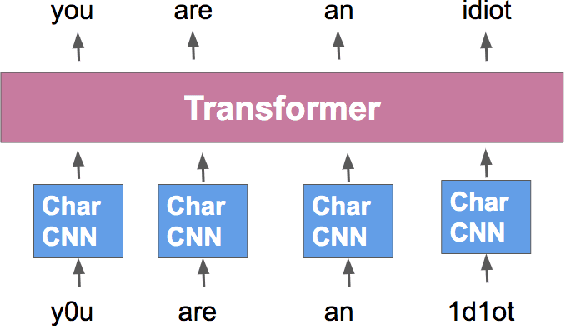


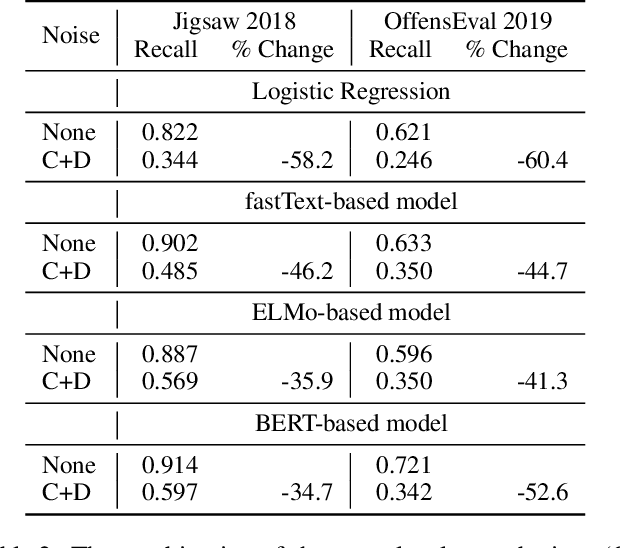
Toxic content detection aims to identify content that can offend or harm its recipients. Automated classifiers of toxic content need to be robust against adversaries who deliberately try to bypass filters. We propose a method of generating realistic model-agnostic attacks using a lexicon of toxic tokens, which attempts to mislead toxicity classifiers by diluting the toxicity signal either by obfuscating toxic tokens through character-level perturbations, or by injecting non-toxic distractor tokens. We show that these realistic attacks reduce the detection recall of state-of-the-art neural toxicity detectors, including those using ELMo and BERT, by more than 50% in some cases. We explore two approaches for defending against such attacks. First, we examine the effect of training on synthetically noised data. Second, we propose the Contextual Denoising Autoencoder (CDAE): a method for learning robust representations that uses character-level and contextual information to denoise perturbed tokens. We show that the two approaches are complementary, improving robustness to both character-level perturbations and distractors, recovering a considerable portion of the lost accuracy. Finally, we analyze the robustness characteristics of the most competitive methods and outline practical considerations for improving toxicity detectors.
Measuring Bias in Contextualized Word Representations
Jun 18, 2019

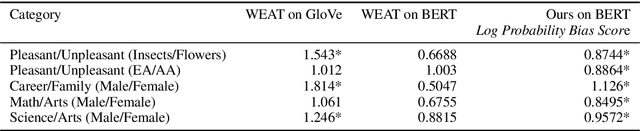
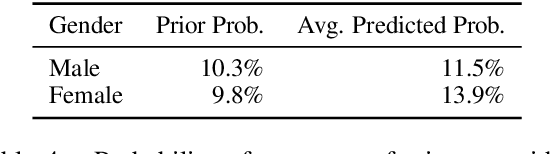
Contextual word embeddings such as BERT have achieved state of the art performance in numerous NLP tasks. Since they are optimized to capture the statistical properties of training data, they tend to pick up on and amplify social stereotypes present in the data as well. In this study, we (1)~propose a template-based method to quantify bias in BERT; (2)~show that this method obtains more consistent results in capturing social biases than the traditional cosine based method; and (3)~conduct a case study, evaluating gender bias in a downstream task of Gender Pronoun Resolution. Although our case study focuses on gender bias, the proposed technique is generalizable to unveiling other biases, including in multiclass settings, such as racial and religious biases.