 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuna: An Evaluation Foundation Model to Catch Language Model Hallucinations with High Accuracy and Low Cost
Jun 03, 2024Retriever Augmented Generation (RAG) systems have become pivotal in enhancing the capabilities of language models by incorporating external knowledge retrieval mechanisms. However, a significant challenge in deploying these systems in industry applications is the detection and mitigation of hallucinations: instances where the model generates information that is not grounded in the retrieved context. Addressing this issue is crucial for ensuring the reliability and accuracy of responses generated by large language models (LLMs) in diverse industry settings. Current hallucination detection techniques fail to deliver accuracy, low latency, and low cost simultaneously. We introduce Luna: a DeBERTA-large (440M) encoder, finetuned for hallucination detection in RAG settings. We demonstrate that Luna outperforms GPT-3.5 and commercial evaluation frameworks on the hallucination detection task, with 97% and 96% reduction in cost and latency, respectively. Luna is lightweight and generalizes across multiple industry verticals and out-of-domain data, making it an ideal candidate for industry LLM applications.
Chainpoll: A high efficacy method for LLM hallucination detection
Oct 22, 2023



Large language models (LLMs) have experienced notable advancements in generating coherent and contextually relevant responses. However, hallucinations - incorrect or unfounded claims - are still prevalent, prompting the creation of automated metrics to detect these in LLM outputs. Our contributions include: introducing ChainPoll, an innovative hallucination detection method that excels compared to its counterparts, and unveiling RealHall, a refined collection of benchmark datasets to assess hallucination detection metrics from recent studies. While creating RealHall, we assessed tasks and datasets from previous hallucination detection studies and observed that many are not suitable for the potent LLMs currently in use. Overcoming this, we opted for four datasets challenging for modern LLMs and pertinent to real-world scenarios. Using RealHall, we conducted a comprehensive comparison of ChainPoll with numerous hallucination metrics from recent studies. Our findings indicate that ChainPoll outperforms in all RealHall benchmarks, achieving an overall AUROC of 0.781. This surpasses the next best theoretical method by 11% and exceeds industry standards by over 23%. Additionally, ChainPoll is cost-effective and offers greater transparency than other metrics. We introduce two novel metrics to assess LLM hallucinations: Adherence and Correctness. Adherence is relevant to Retrieval Augmented Generation workflows, evaluating an LLM's analytical capabilities within given documents and contexts. In contrast, Correctness identifies logical and reasoning errors.
Fix your Models by Fixing your Datasets
Dec 15, 2021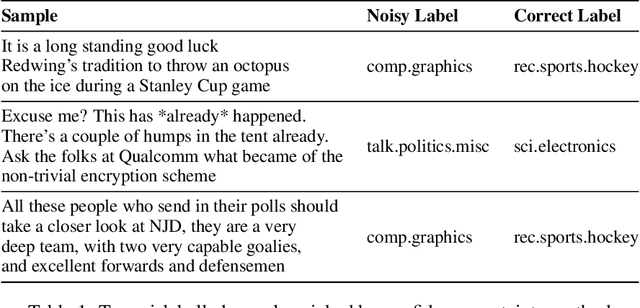

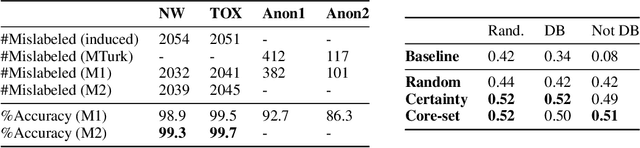
The quality of underlying training data is very crucial for building performant machine learning models with wider generalizabilty. However, current machine learning (ML) tools lack streamlined processes for improving the data quality. So, getting data quality insights and iteratively pruning the errors to obtain a dataset which is most representative of downstream use cases is still an ad-hoc manual process. Our work addresses this data tooling gap, required to build improved ML workflows purely through data-centric techniques. More specifically, we introduce a systematic framework for (1) finding noisy or mislabelled samples in the dataset and, (2) identifying the most informative samples, which when included in training would provide maximal model performance lift. We demonstrate the efficacy of our framework on public as well as private enterprise datasets of two Fortune 500 companies, and are confident this work will form the basis for ML teams to perform more intelligent data discovery and pruning.
Managing ML Pipelines: Feature Stores and the Coming Wave of Embedding Ecosystems
Aug 11, 2021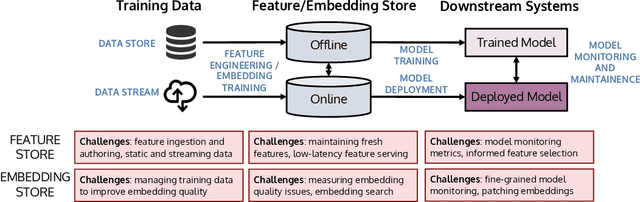
The industrial machine learning pipeline requires iterating on model features, training and deploying models, and monitoring deployed models at scale. Feature stores were developed to manage and standardize the engineer's workflow in this end-to-end pipeline, focusing on traditional tabular feature data. In recent years, however, model development has shifted towards using self-supervised pretrained embeddings as model features. Managing these embeddings and the downstream systems that use them introduces new challenges with respect to managing embedding training data, measuring embedding quality, and monitoring downstream models that use embeddings. These challenges are largely unaddressed in standard feature stores. Our goal in this tutorial is to introduce the feature store system and discuss the challenges and current solutions to managing these new embedding-centric pipelines.